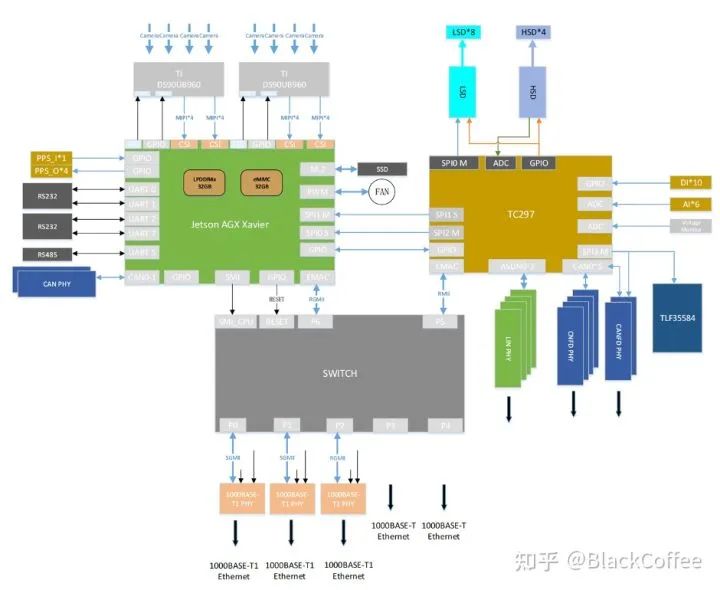
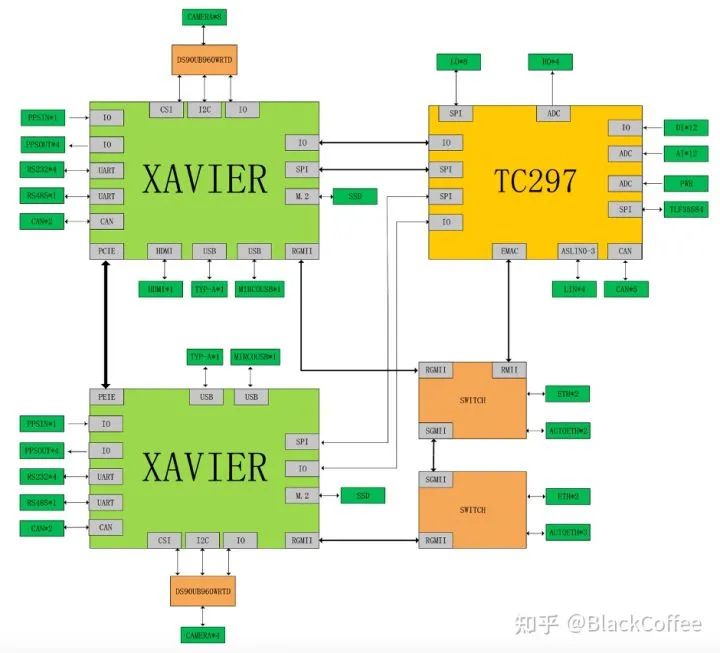
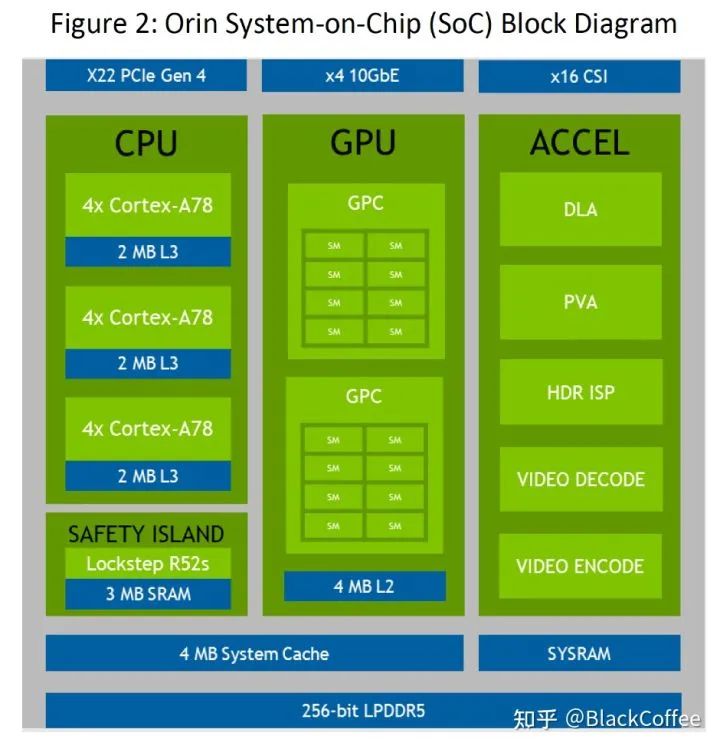
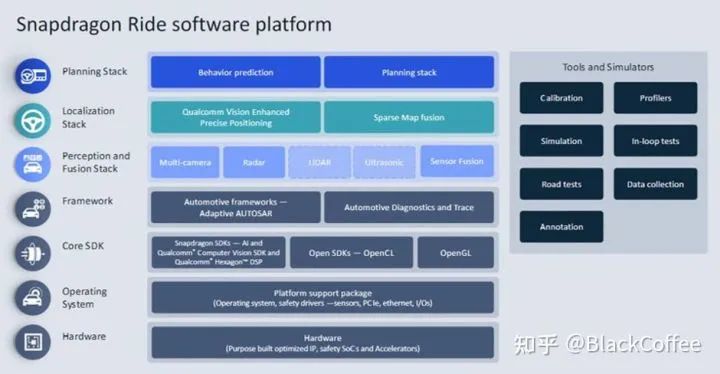
这篇内容主要讨论三个基本问题,硅电容是什么,为什么要使用硅电容,如何正确使用硅电容?1. 硅电容是什么首先我们需要了解电容是什么?物理学上电容的概念指的是给定电位差下自由电荷的储藏量,记为C,单位是F,指的是容纳电荷的能力,C=εS/d=ε0εrS/4πkd(真空)=Q/U。百度百科上电容器的概念指的是两个相互靠近的导体,中间夹一层不导电的绝缘介质。通过观察电容本身的定义公式中可以看到,在各个变量中比较能够改变的就是εr,S和d,也就是介质的介电常数,金属板有效相对面积以及距离。当前
知白
2025-01-06 12:04
120浏览