

作者简介
伟林,中年码农,从事过电信、手机、安全、芯片等行业,目前依旧从事Linux方向开发工作,个人爱好Linux相关知识分享,个人微博CSDN pwl999,欢迎大家关注!
阅码场目前已创建两个专业技术交流群,由阅码场资深讲师主持,主要是为了更好的技术交流与分享。
会员招募:各专业群会员费为88元/季度,权益包含群内提问,线下活动8折,全年定期免费群技术分享(每次点播价为19元/次),有意加入请私信客服小月(小月微信号:linuxer2016)
两个群分别为:
彭伟林-阅码场内核性能与稳定性
本群定位内核性能与稳定性技术交流,覆盖云/网/车/机/芯领域资深内核专家,由阅码场资深讲师彭伟林主持。
甄建勇-Perf Monitor&Perf Counter
本群群定位Perf和CPU架构技术交流,覆盖云/网/车/机/芯领域资深专家,由阅码场资深讲师甄建勇主持。
Q
学员问:我最近在看k8s对cgroup的管理部分,对于cfs对cgroup的调度有些疑惑。想搞明白cgroup里面的 period、quota是如何影响cfs的调度的
A
伟林老师给出如下文章进行解答
linux进程一般分成了实时进程(RT)和普通进程,linux使用sched_class结构来管理不同类型进程的调度算法:rt_sched_class负责实时类进程(SCHED_FIFO/SCHED_RR)的调度,fair_sched_class负责普通进程(SCHED_NORMAL)的调度,还有idle_sched_class(SCHED_IDLE)、dl_sched_class(SCHED_DEADLINE)都比较简单和少见;
实时进程的调度算法移植都没什么变化,SCHED_FIFO类型的谁优先级高就一直抢占/SCHED_RR相同优先级的进行时间片轮转。
所以我们常说的调度算法一般指普通进程(SCHED_NORMAL)的调度算法,这类进程也在系统中占大多数。在2.6.24以后内核引入的是CFS算法,这个也是现在的主流;在这之前2.6内核使用的是一种O(1)算法;
1.1、linux2.6的O(1)调度算法
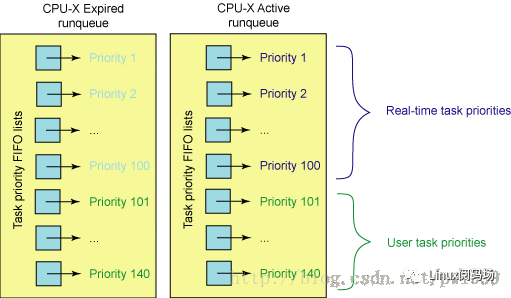
linux进程的优先级有140种,其中优先级(0-99)对应实时进程,优先级(100-139)对应普通进程,nice(0)对应优先级120,nice(-10)对应优先级100,nice(19)对应优先级139。
#define MAX_USER_RT_PRIO 100#define MAX_RT_PRIO MAX_USER_RT_PRIO // 优先级(1-99)对应实时进程#define MAX_PRIO (MAX_RT_PRIO + 40) // 优先级(100-139)对应普通进程/** Convert user-nice values [ -20 ... 0 ... 19 ]* to static priority [ MAX_RT_PRIO..MAX_PRIO-1 ],* and back.*/#define NICE_TO_PRIO(nice) (MAX_RT_PRIO + (nice) + 20) // nice(0)对应优先级120,nice(-20)对应优先级100,nice(19)对应优先级139#define PRIO_TO_NICE(prio) ((prio) - MAX_RT_PRIO - 20)#define TASK_NICE(p) PRIO_TO_NICE((p)->static_prio)/** 'User priority' is the nice value converted to something we* can work with better when scaling various scheduler parameters,* it's a [ 0 ... 39 ] range.*/#define USER_PRIO(p) ((p)-MAX_RT_PRIO)#define TASK_USER_PRIO(p) USER_PRIO((p)->static_prio)#define MAX_USER_PRIO (USER_PRIO(MAX_PRIO))
O(1)调度算法主要包含以下内容:
(1)、每个cpu的rq包含两个140个成员的链表数组rq->active、rq->expired;
任务根据优先级挂载到不同的数组当中,时间片没有用完放在rq->active,时间片用完后放到rq->expired,在rq->active所有任务时间片用完为空后rq->active和rq->expired相互反转。
在schedule()中pcik next task时,首先会根据array->bitmap找出哪个最先优先级还有任务需要调度,然后根据index找到 对应的优先级任务链表。因为查找bitmap的在IA处理器上可以通过bsfl等一条指令来实现,所以他的复杂度为O(1)。
asmlinkage void __sched schedule(void){idx = sched_find_first_bit(array->bitmap);queue = array->queue + idx;next = list_entry(queue->next, task_t, run_list);}
(2)、进程优先级分为静态优先级(p->static_prio)、动态优先级(p->prio);
静态优先级(p->static_prio)决定进程时间片的大小:
/** task_timeslice() scales user-nice values [ -20 ... 0 ... 19 ]* to time slice values: [800ms ... 100ms ... 5ms]** The higher a thread's priority, the bigger timeslices* it gets during one round of execution. But even the lowest* priority thread gets MIN_TIMESLICE worth of execution time.*//* 根据算法如果nice(0)的时间片为100mS,那么nice(-20)时间片为800ms、nice(19)时间片为5ms */#define SCALE_PRIO(x, prio) \max(x * (MAX_PRIO - prio) / (MAX_USER_PRIO/2), MIN_TIMESLICE)static unsigned int task_timeslice(task_t *p){if (p->static_prio < NICE_TO_PRIO(0))return SCALE_PRIO(DEF_TIMESLICE*4, p->static_prio);elsereturn SCALE_PRIO(DEF_TIMESLICE, p->static_prio);}#define MIN_TIMESLICE max(5 * HZ / 1000, 1)#define DEF_TIMESLICE (100 * HZ / 1000)
动态优先级决定进程在rq->active、rq->expired进程链表中的index:
static void enqueue_task(struct task_struct *p, prio_array_t *array){sched_info_queued(p);list_add_tail(&p->run_list, array->queue + p->prio); // 根据动态优先级p->prio作为index,找到对应链表__set_bit(p->prio, array->bitmap);array->nr_active++;p->array = array;}
动态优先级和静态优先级之间的转换函数:动态优先级=max(100 , min(静态优先级 – bonus + 5) , 139)
/** effective_prio - return the priority that is based on the static* priority but is modified by bonuses/penalties.** We scale the actual sleep average [0 .... MAX_SLEEP_AVG]* into the -5 ... 0 ... +5 bonus/penalty range.** We use 25% of the full 0...39 priority range so that:** 1) nice +19 interactive tasks do not preempt nice 0 CPU hogs.* 2) nice -20 CPU hogs do not get preempted by nice 0 tasks.** Both properties are important to certain workloads.*/static int effective_prio(task_t *p){int bonus, prio;if (rt_task(p))return p->prio;bonus = CURRENT_BONUS(p) - MAX_BONUS / 2; // MAX_BONUS = 10prio = p->static_prio - bonus;if (prio < MAX_RT_PRIO)prio = MAX_RT_PRIO;if (prio > MAX_PRIO-1)prio = MAX_PRIO-1;return prio;}
从上面看出动态优先级是以静态优先级为基础,再加上相应的惩罚或奖励(bonus)。这个bonus并不是随机的产生,而是根据进程过去的平均睡眠时间做相应的惩罚或奖励。所谓平均睡眠时间(sleep_avg,位于task_struct结构中)就是进程在睡眠状态所消耗的总时间数,这里的平均并不是直接对时间求平均数。
(3)、根据平均睡眠时间判断进程是否是交互式进程(INTERACTIVE);
交互式进程的好处?交互式进程时间片用完会重新进入active队列;
void scheduler_tick(void){if (!--p->time_slice) { // (1) 时间片用完dequeue_task(p, rq->active); // (2) 退出actice队列set_tsk_need_resched(p);p->prio = effective_prio(p);p->time_slice = task_timeslice(p);p->first_time_slice = 0;if (!rq->expired_timestamp)rq->expired_timestamp = jiffies;if (!TASK_INTERACTIVE(p) || EXPIRED_STARVING(rq)) {enqueue_task(p, rq->expired); // (3) 普通进程进入expired队列if (p->static_prio < rq->best_expired_prio)rq->best_expired_prio = p->static_prio;} elseenqueue_task(p, rq->active); // (4) 如果是交互式进程,重新进入active队列}}
判断进程是否是交互式进程(INTERACTIVE)的公式:动态优先级≤3*静态优先级/4 + 28
#define TASK_INTERACTIVE(p) \((p)->prio <= (p)->static_prio - DELTA(p))
平均睡眠时间的算法和交互进程的思想,我没有详细去看大家可以参考一下的一些描述:
所谓平均睡眠时间(sleep_avg,位于task_struct结构中)就是进程在睡眠状态所消耗的总时间数,这里的平均并不是直接对时间求平均数。平均睡眠时间随着进程的睡眠而增长,随着进程的运行而减少。因此,平均睡眠时间记录了进程睡眠和执行的时间,它是用来判断进程交互性强弱的关键数据。如果一个进程的平均睡眠时间很大,那么它很可能是一个交互性很强的进程。反之,如果一个进程的平均睡眠时间很小,那么它很可能一直在执行。另外,平均睡眠时间也记录着进程当前的交互状态,有很快的反应速度。比如一个进程在某一小段时间交互性很强,那么sleep_avg就有可能暴涨(当然它不能超过 MAX_SLEEP_AVG),但如果之后都一直处于执行状态,那么sleep_avg就又可能一直递减。理解了平均睡眠时间,那么bonus的含义也就显而易见了。交互性强的进程会得到调度程序的奖励(bonus为正),而那些一直霸占CPU的进程会得到相应的惩罚(bonus为负)。其实bonus相当于平均睡眠时间的缩影,此时只是将sleep_avg调整成bonus数值范围内的大小。
O(1)调度器区分交互式进程和批处理进程的算法与以前虽大有改进,但仍然在很多情况下会失效。有一些著名的程序总能让该调度器性能下降,导致交互式进程反应缓慢。例如fiftyp.c, thud.c, chew.c, ring-test.c, massive_intr.c等。而且O(1)调度器对NUMA支持也不完善。
1.2、CFS调度算法
针对O(1)算法出现的问题(具体是哪些问题我也理解不深说不上来),linux推出了CFS(Completely Fair Scheduler)完全公平调度算法。该算法从楼梯调度算法(staircase scheduler)和RSDL(Rotating Staircase Deadline Scheduler)发展而来,抛弃了复杂的active/expire数组和交互进程计算,把所有进程一视同仁都放到一个执行时间的红黑树中,实现了完全公平的思想。
CFS的主要思想如下:
根据普通进程的优先级nice值来定一个比重(weight),该比重用来计算进程的实际运行时间到虚拟运行时间(vruntime)的换算;不言而喻优先级高的进程运行更多的时间和优先级低的进程运行更少的时间在vruntime上市等价的;
根据rq->cfs_rq中进程的数量计算一个总的period周期,每个进程再根据自己的weight占整个的比重来计算自己的理想运行时间(ideal_runtime),在scheduler_tick()中判断如果进程的实际运行时间(exec_runtime)已经达到理想运行时间(ideal_runtime),则进程需要被调度test_tsk_need_resched(curr)。有了period,那么cfs_rq中所有进程在period以内必会得到调度;
根据进程的虚拟运行时间(vruntime),把rq->cfs_rq中的进程组织成一个红黑树(平衡二叉树),那么在pick_next_entity时树的最左节点就是运行时间最少的进程,是最好的需要调度的候选人;
1.2.1、vruntime
每个进程的vruntime = runtime * (NICE_0_LOAD/nice_n_weight)
/* 该表的主要思想是,高一个等级的weight是低一个等级的 1.25 倍 *//** Nice levels are multiplicative, with a gentle 10% change for every* nice level changed. I.e. when a CPU-bound task goes from nice 0 to* nice 1, it will get ~10% less CPU time than another CPU-bound task* that remained on nice 0.** The "10% effect" is relative and cumulative: from _any_ nice level,* if you go up 1 level, it's -10% CPU usage, if you go down 1 level* it's +10% CPU usage. (to achieve that we use a multiplier of 1.25.* If a task goes up by ~10% and another task goes down by ~10% then* the relative distance between them is ~25%.)*/static const int prio_to_weight[40] = {/* -20 */ 88761, 71755, 56483, 46273, 36291,/* -15 */ 29154, 23254, 18705, 14949, 11916,/* -10 */ 9548, 7620, 6100, 4904, 3906,/* -5 */ 3121, 2501, 1991, 1586, 1277,/* 0 */ 1024, 820, 655, 526, 423,/* 5 */ 335, 272, 215, 172, 137,/* 10 */ 110, 87, 70, 56, 45,/* 15 */ 36, 29, 23, 18, 15,};
nice(0)对应的weight是NICE_0_LOAD(1024),nice(-1)对应的weight是NICE_0_LOAD*1.25,nice(1)对应的weight是NICE_0_LOAD/1.25。
NICE_0_LOAD(1024)在schedule计算中是一个非常神奇的数字,他的含义就是基准”1”。因为kernel不能表示小数,所以把1放大称为1024。
scheduler_tick() -> task_tick_fair() -> update_curr():↓static void update_curr(struct cfs_rq *cfs_rq){curr->sum_exec_runtime += delta_exec; // (1) 累计当前进程的实际运行时间schedstat_add(cfs_rq, exec_clock, delta_exec);curr->vruntime += calc_delta_fair(delta_exec, curr); // (2) 累计当前进程的vruntimeupdate_min_vruntime(cfs_rq);}↓static inline u64 calc_delta_fair(u64 delta, struct sched_entity *se){// (2.1) 根据进程的weight折算vruntimeif (unlikely(se->load.weight != NICE_0_LOAD))delta = __calc_delta(delta, NICE_0_LOAD, &se->load);return delta;}
1.2.2、period和ideal_runtime
scheduler_tick()中根据cfs_rq中的se数量计算period和ideal_time,判断当前进程时间是否用完需要调度:
scheduler_tick() -> task_tick_fair() -> entity_tick() -> check_preempt_tick():↓static voidcheck_preempt_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr){unsigned long ideal_runtime, delta_exec;struct sched_entity *se;s64 delta;/* (1) 计算period和ideal_time */ideal_runtime = sched_slice(cfs_rq, curr);/* (2) 计算实际运行时间 */delta_exec = curr->sum_exec_runtime - curr->prev_sum_exec_runtime;/* (3) 如果实际运行时间已经超过ideal_time,当前进程需要被调度,设置TIF_NEED_RESCHED标志*/if (delta_exec > ideal_runtime) {resched_curr(rq_of(cfs_rq));/** The current task ran long enough, ensure it doesn't get* re-elected due to buddy favours.*/clear_buddies(cfs_rq, curr);return;}/** Ensure that a task that missed wakeup preemption by a* narrow margin doesn't have to wait for a full slice.* This also mitigates buddy induced latencies under load.*/if (delta_exec < sysctl_sched_min_granularity)return;se = __pick_first_entity(cfs_rq);delta = curr->vruntime - se->vruntime;if (delta < 0)return;if (delta > ideal_runtime)resched_curr(rq_of(cfs_rq));}↓static u64 sched_slice(struct cfs_rq *cfs_rq, struct sched_entity *se){/* (1.1) 计算period值 */u64 slice = __sched_period(cfs_rq->nr_running + !se->on_rq);/* 疑问:这里是根据最底层se和cfq_rq来计算ideal_runtime,然后逐层按比重折算到上层时间这种方法是不对的,应该是从顶层到底层分配时间下来才比较合理。庆幸的是,在task_tick_fair()中会调用task_tick_fair递归的每层递归的计算时间,所以最上面的一层也是判断的*/for_each_sched_entity(se) {struct load_weight *load;struct load_weight lw;cfs_rq = cfs_rq_of(se);load = &cfs_rq->load;if (unlikely(!se->on_rq)) {lw = cfs_rq->load;update_load_add(&lw, se->load.weight);load = &lw;}/* (1.2) 根据period值和进程weight在cfs_rq weight中的比重计算ideal_runtime*/slice = __calc_delta(slice, se->load.weight, load);}return slice;}↓/* (1.1.1) period的计算方法,从默认值看:如果cfs_rq中的进程大于8(sched_nr_latency)个,则period=n*0.75ms(sysctl_sched_min_granularity)如果小于等于8(sched_nr_latency)个,则period=6ms(sysctl_sched_latency)*//** The idea is to set a period in which each task runs once.** When there are too many tasks (sched_nr_latency) we have to stretch* this period because otherwise the slices get too small.** p = (nr <= nl) ? l : l*nr/nl*/static u64 __sched_period(unsigned long nr_running){if (unlikely(nr_running > sched_nr_latency))return nr_running * sysctl_sched_min_granularity;elsereturn sysctl_sched_latency;}/** Minimal preemption granularity for CPU-bound tasks:* (default: 0.75 msec * (1 + ilog(ncpus)), units: nanoseconds)*/unsigned int sysctl_sched_min_granularity = 750000ULL;unsigned int normalized_sysctl_sched_min_granularity = 750000ULL;/** is kept at sysctl_sched_latency / sysctl_sched_min_granularity*/static unsigned int sched_nr_latency = 8;/** Targeted preemption latency for CPU-bound tasks:* (default: 6ms * (1 + ilog(ncpus)), units: nanoseconds)** NOTE: this latency value is not the same as the concept of* 'timeslice length' - timeslices in CFS are of variable length* and have no persistent notion like in traditional, time-slice* based scheduling concepts.** (to see the precise effective timeslice length of your workload,* run vmstat and monitor the context-switches (cs) field)*/unsigned int sysctl_sched_latency = 6000000ULL;unsigned int normalized_sysctl_sched_latency = 6000000ULL;
1.2.3、红黑树(Red Black Tree)

红黑树又称为平衡二叉树,它的特点:
1、平衡。从根节点到叶子节点之间的任何路径,差值不会超过1。所以pick_next_task()复杂度为O(log n)。可以看到pick_next_task()复杂度是大于o(1)算法的,但是最大路径不会超过log2(n) - 1,复杂度是可控的。
2、排序。左边的节点一定小于右边的节点,所以最左边节点是最小值。
按照进程的vruntime组成了红黑树:
enqueue_task_fair() -> enqueue_entity() -> __enqueue_entity():↓static void __enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se){struct rb_node **link = &cfs_rq->tasks_timeline.rb_node;struct rb_node *parent = NULL;struct sched_entity *entry;int leftmost = 1;/** Find the right place in the rbtree:*//* (1) 根据vruntime的值在rbtree中找到合适的插入点 */while (*link) {parent = *link;entry = rb_entry(parent, struct sched_entity, run_node);/** We dont care about collisions. Nodes with* the same key stay together.*/if (entity_before(se, entry)) {link = &parent->rb_left;} else {link = &parent->rb_right;leftmost = 0;}}/** Maintain a cache of leftmost tree entries (it is frequently* used):*//* (2) 更新最左值最小值cache */if (leftmost)cfs_rq->rb_leftmost = &se->run_node;/* (3) 将节点插入rbtree */rb_link_node(&se->run_node, parent, link);rb_insert_color(&se->run_node, &cfs_rq->tasks_timeline);}
1.2.4、sched_entity和task_group
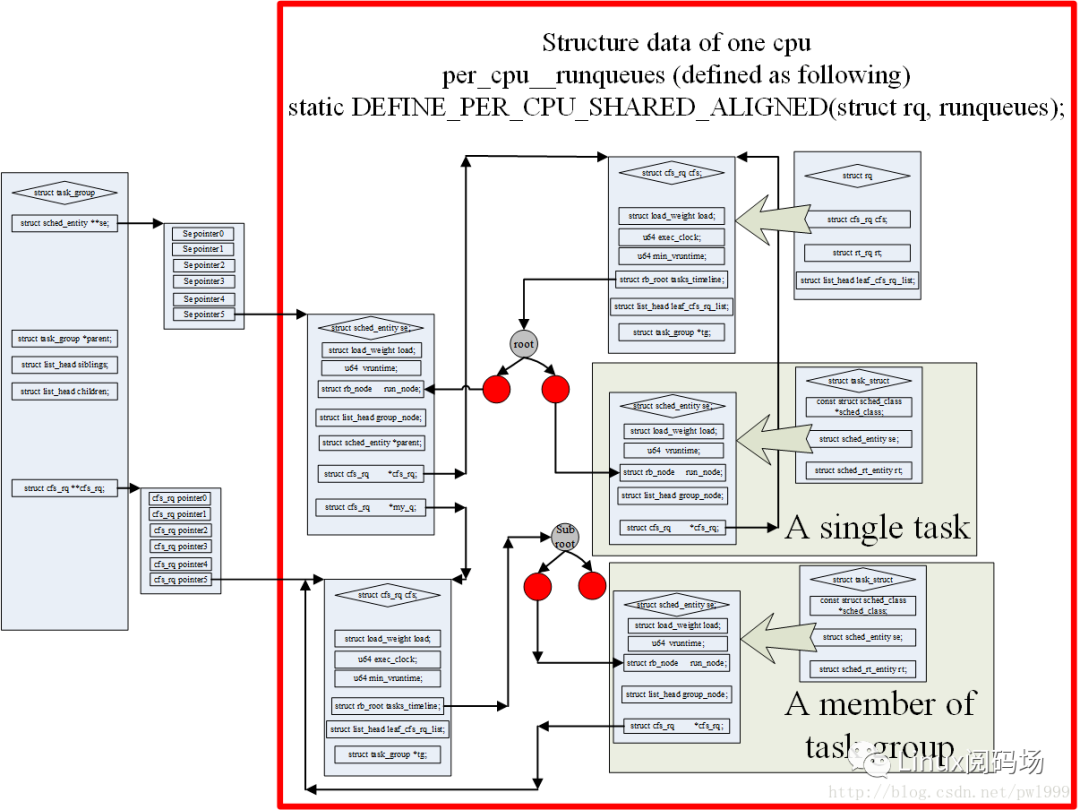
因为新的内核加入了task_group的概念,所以现在不是使用task_struct结构直接参与到schedule计算当中,而是使用sched_entity结构。一个sched_entity结构可能是一个task也可能是一个task_group->se[cpu]。上图非常好的描述了这些结构之间的关系。
其中主要的层次关系如下:
1、一个cpu只对应一个rq;
2、一个rq有一个cfs_rq;
3、cfs_rq使用红黑树组织多个同一层级的sched_entity;
4、如果sched_entity对应的是一个task_struct,那sched_entity和task是一对一的关系;
5、如果sched_entity对应的是task_group,那么他是一个task_group多个sched_entity中的一个。task_group有一个数组se[cpu],在每个cpu上都有一个sched_entity。这种类型的sched_entity有自己的cfs_rq,一个sched_entity对应一个cfs_rq(se->my_q),cfs_rq再继续使用红黑树组织多个同一层级的sched_entity;3-5的层次关系可以继续递归下去。
1.2.5、scheduler_tick()
关于算法,最核心的部分都在scheduler_tick()函数当中,所以我们来详细的解析这部分代码。
void scheduler_tick(void){int cpu = smp_processor_id();struct rq *rq = cpu_rq(cpu);struct task_struct *curr = rq->curr;/* (1) sched_tick()的校准,x86 bug的修复 */sched_clock_tick();mt_trace_rqlock_start(&rq->lock);raw_spin_lock(&rq->lock);mt_trace_rqlock_end(&rq->lock);/* (2) 计算cpu级别(rq)的运行时间 :rq->clock是cpu总的运行时间 (疑问:这里没有考虑cpu hotplug??)rq->clock_task是进程的实际运行时间,= rq->clock总时间 - rq->prev_irq_time中断消耗的时间*/update_rq_clock(rq);/* (3) 调用进程所属sched_class的tick函数cfs对应的是task_tick_fair()rt对应的是task_tick_rt()*/curr->sched_class->task_tick(rq, curr, 0);/* (4) 更新cpu级别的负载 */update_cpu_load_active(rq);/* (5) 更新系统级别的负载 */calc_global_load_tick(rq);/* (6) cpufreq_sched governor,计算负载来进行cpu调频 */sched_freq_tick(cpu);raw_spin_unlock(&rq->lock);perf_event_task_tick();mt_save_irq_counts(SCHED_TICK);/* (7) 负载均衡 */rq->idle_balance = idle_cpu(cpu);trigger_load_balance(rq);rq_last_tick_reset(rq);}|→static void task_tick_fair(struct rq *rq, struct task_struct *curr, int queued){struct cfs_rq *cfs_rq;struct sched_entity *se = &curr->se;/* (3.1) 按照task_group组织的se父子关系,逐级对se 和 se->parent 进行递归计算*/for_each_sched_entity(se) {cfs_rq = cfs_rq_of(se);/* (3.2) se对应的tick操作 */entity_tick(cfs_rq, se, queued);}/* (3.3) NUMA负载均衡 */if (static_branch_unlikely(&sched_numa_balancing))task_tick_numa(rq, curr);if (!rq->rd->overutilized && cpu_overutilized(task_cpu(curr)))rq->rd->overutilized = true;}||→static voidentity_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr, int queued){/** Update run-time statistics of the 'current'.*//* (3.2.1) 更新cfs_rq->curr的se的实际运行时间curr->sum_exec_runtime和虚拟运行时间curr->vruntime更新cfs_rq的运行时间*/update_curr(cfs_rq);/** Ensure that runnable average is periodically updated.*//* (3.2.2) 更新entity级别的负载,PELT计算 */update_load_avg(curr, 1);/* (3.2.3) 更新task_group的shares */update_cfs_shares(cfs_rq);/** queued ticks are scheduled to match the slice, so don't bother* validating it and just reschedule.*/if (queued) {resched_curr(rq_of(cfs_rq));return;}/** don't let the period tick interfere with the hrtick preemption*/if (!sched_feat(DOUBLE_TICK) &&hrtimer_active(&rq_of(cfs_rq)->hrtick_timer))return;/* (3.2.4) check当前任务的理想运行时间ideal_runtime是否已经用完,是否需要重新调度*/if (cfs_rq->nr_running > 1)check_preempt_tick(cfs_rq, curr);}|||→static void update_curr(struct cfs_rq *cfs_rq){struct sched_entity *curr = cfs_rq->curr;u64 now = rq_clock_task(rq_of(cfs_rq));u64 delta_exec;if (unlikely(!curr))return;/* (3.2.1.1) 计算cfs_rq->curr se的实际执行时间 */delta_exec = now - curr->exec_start;if (unlikely((s64)delta_exec <= 0))return;curr->exec_start = now;schedstat_set(curr->statistics.exec_max,max(delta_exec, curr->statistics.exec_max));curr->sum_exec_runtime += delta_exec;// 更新cfs_rq的实际执行时间cfs_rq->exec_clockschedstat_add(cfs_rq, exec_clock, delta_exec);/* (3.2.1.2) 计算cfs_rq->curr se的虚拟执行时间vruntime */curr->vruntime += calc_delta_fair(delta_exec, curr);update_min_vruntime(cfs_rq);/* (3.2.1.3) 如果se对应的是task,而不是task_group,更新task对应的时间统计*/if (entity_is_task(curr)) {struct task_struct *curtask = task_of(curr);trace_sched_stat_runtime(curtask, delta_exec, curr->vruntime);// 更新task所在cgroup之cpuacct的某个cpu运行时间ca->cpuusage[cpu]->cpuusagecpuacct_charge(curtask, delta_exec);// 统计task所在线程组(thread group)的运行时间:// tsk->signal->cputimer.cputime_atomic.sum_exec_runtimeaccount_group_exec_runtime(curtask, delta_exec);}/* (3.2.1.4) 计算cfs_rq的运行时间,是否超过cfs_bandwidth的限制:cfs_rq->runtime_remaining*/account_cfs_rq_runtime(cfs_rq, delta_exec);}
1.2.6、几个特殊时刻vruntime的变化
关于cfs调度和vruntime,除了正常的scheduler_tick()的计算,还有些特殊时刻需要特殊处理。这些细节用一些疑问来牵引出来:
1、新进程的vruntime是多少?
假如新进程的vruntime初值为0的话,比老进程的值小很多,那么它在相当长的时间内都会保持抢占CPU的优势,老进程就要饿死了,这显然是不公平的。
CFS的做法是:取父进程vruntime(curr->vruntime) 和 (cfs_rq->min_vruntime + 假设se运行过一轮的值)之间的最大值,赋给新创建进程。把新进程对现有进程的调度影响降到最小。
_do_fork() -> copy_process() -> sched_fork() -> task_fork_fair():↓static void task_fork_fair(struct task_struct *p){/* (1) 如果cfs_rq->current进程存在,se->vruntime的值暂时等于curr->vruntime*/if (curr)se->vruntime = curr->vruntime;/* (2) 设置新的se->vruntime */place_entity(cfs_rq, se, 1);/* (3) 如果sysctl_sched_child_runs_first标志被设置,确保fork子进程比父进程先执行*/if (sysctl_sched_child_runs_first && curr && entity_before(curr, se)) {/** Upon rescheduling, sched_class::put_prev_task() will place* 'current' within the tree based on its new key value.*/swap(curr->vruntime, se->vruntime);resched_curr(rq);}/* (4) 防止新进程运行时是在其他cpu上运行的,这样在加入另一个cfs_rq时再加上另一个cfs_rq队列的min_vruntime值即可(具体可以看enqueue_entity函数)*/se->vruntime -= cfs_rq->min_vruntime;raw_spin_unlock_irqrestore(&rq->lock, flags);}|→static voidplace_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int initial){u64 vruntime = cfs_rq->min_vruntime;/** The 'current' period is already promised to the current tasks,* however the extra weight of the new task will slow them down a* little, place the new task so that it fits in the slot that* stays open at the end.*//* (2.1) 计算cfs_rq->min_vruntime + 假设se运行过一轮的值,这样的做法是把新进程se放到红黑树的最后 */if (initial && sched_feat(START_DEBIT))vruntime += sched_vslice(cfs_rq, se);/* sleeps up to a single latency don't count. */if (!initial) {unsigned long thresh = sysctl_sched_latency;/** Halve their sleep time's effect, to allow* for a gentler effect of sleepers:*/if (sched_feat(GENTLE_FAIR_SLEEPERS))thresh >>= 1;vruntime -= thresh;}/* (2.2) 在 (curr->vruntime) 和 (cfs_rq->min_vruntime + 假设se运行过一轮的值),之间取最大值*//* ensure we never gain time by being placed backwards. */se->vruntime = max_vruntime(se->vruntime, vruntime);}static voidenqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags){/** Update the normalized vruntime before updating min_vruntime* through calling update_curr().*//* (4.1) 在enqueue时给se->vruntime重新加上cfs_rq->min_vruntime */if (!(flags & ENQUEUE_WAKEUP) || (flags & ENQUEUE_WAKING))se->vruntime += cfs_rq->min_vruntime;}
2、休眠进程的vruntime一直保持不变吗、
如果休眠进程的 vruntime 保持不变,而其他运行进程的 vruntime 一直在推进,那么等到休眠进程终于唤醒的时候,它的vruntime比别人小很多,会使它获得长时间抢占CPU的优势,其他进程就要饿死了。这显然是另一种形式的不公平。
CFS是这样做的:在休眠进程被唤醒时重新设置vruntime值,以min_vruntime值为基础,给予一定的补偿,但不能补偿太多。
static voidenqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags){if (flags & ENQUEUE_WAKEUP) {/* (1) 计算进程唤醒后的vruntime */place_entity(cfs_rq, se, 0);enqueue_sleeper(cfs_rq, se);}}|→static voidplace_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int initial){/* (1.1) 初始值是cfs_rq的当前最小值min_vruntime */u64 vruntime = cfs_rq->min_vruntime;/** The 'current' period is already promised to the current tasks,* however the extra weight of the new task will slow them down a* little, place the new task so that it fits in the slot that* stays open at the end.*/if (initial && sched_feat(START_DEBIT))vruntime += sched_vslice(cfs_rq, se);/* sleeps up to a single latency don't count. *//* (1.2) 在最小值min_vruntime的基础上给予补偿,默认补偿值是6ms(sysctl_sched_latency)*/if (!initial) {unsigned long thresh = sysctl_sched_latency;/** Halve their sleep time's effect, to allow* for a gentler effect of sleepers:*/if (sched_feat(GENTLE_FAIR_SLEEPERS))thresh >>= 1;vruntime -= thresh;}/* ensure we never gain time by being placed backwards. */se->vruntime = max_vruntime(se->vruntime, vruntime);}
3、休眠进程在唤醒时会立刻抢占CPU吗?
进程被唤醒默认是会马上检查是否库抢占,因为唤醒的vruntime在cfs_rq的最小值min_vruntime基础上进行了补偿,所以他肯定会抢占当前的进程。
CFS可以通过禁止WAKEUP_PREEMPTION来禁止唤醒抢占,不过这也就失去了抢占特性。
try_to_wake_up() -> ttwu_queue() -> ttwu_do_activate() -> ttwu_do_wakeup() -> check_preempt_curr() -> check_preempt_wakeup()↓static void check_preempt_wakeup(struct rq *rq, struct task_struct *p, int wake_flags){/** Batch and idle tasks do not preempt non-idle tasks (their preemption* is driven by the tick):*//* (1) 如果WAKEUP_PREEMPTION没有被设置,不进行唤醒时的抢占 */if (unlikely(p->policy != SCHED_NORMAL) || !sched_feat(WAKEUP_PREEMPTION))return;preempt:resched_curr(rq);}
4、进程从一个CPU迁移到另一个CPU上的时候vruntime会不会变?
不同cpu的负载时不一样的,所以不同cfs_rq里se的vruntime水平是不一样的。如果进程迁移vruntime不变也是非常不公平的。
CFS使用了一个很聪明的做法:在退出旧的cfs_rq时减去旧cfs_rq的min_vruntime,在加入新的cfq_rq时重新加上新cfs_rq的min_vruntime。
static voiddequeue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags){/** Normalize the entity after updating the min_vruntime because the* update can refer to the ->curr item and we need to reflect this* movement in our normalized position.*//* (1) 退出旧的cfs_rq时减去旧cfs_rq的min_vruntime */if (!(flags & DEQUEUE_SLEEP))se->vruntime -= cfs_rq->min_vruntime;}static voidenqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags){/** Update the normalized vruntime before updating min_vruntime* through calling update_curr().*//* (2) 加入新的cfq_rq时重新加上新cfs_rq的min_vruntime */if (!(flags & ENQUEUE_WAKEUP) || (flags & ENQUEUE_WAKING))se->vruntime += cfs_rq->min_vruntime;}
1.2.7、cfs bandwidth
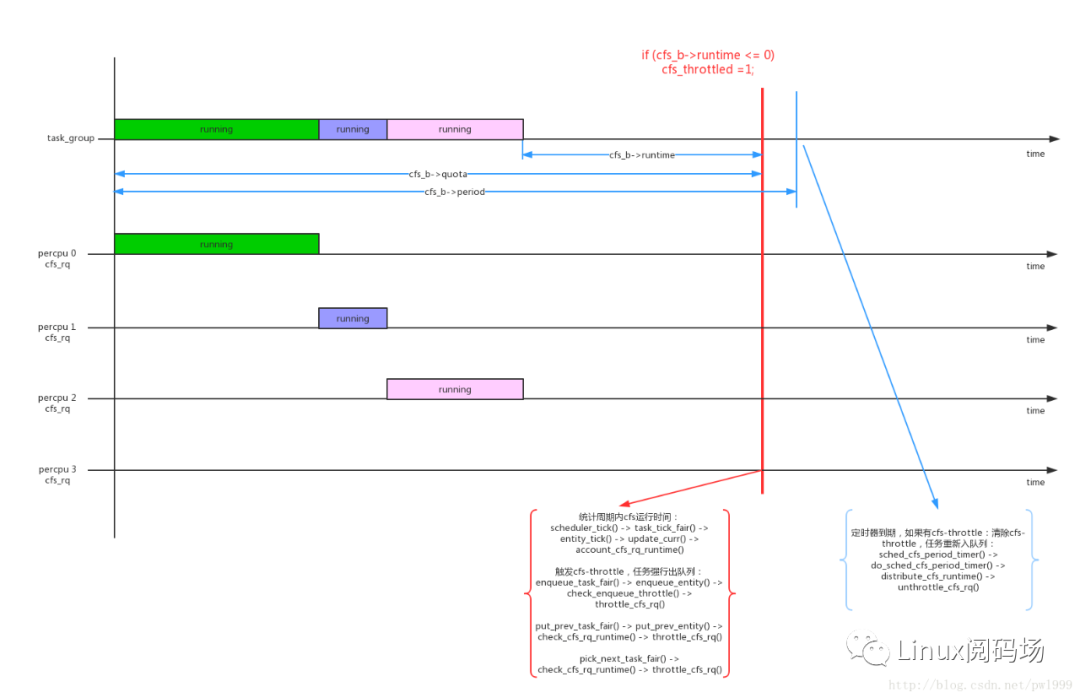
1、cfs bandwidth是针对task_group的配置,一个task_group的bandwidth使用一个struct cfs_bandwidth *cfs_b数据结构来控制。
struct cfs_bandwidth {raw_spinlock_t lock;ktime_t period; // cfs bandwidth的监控周期,默认值是default_cfs_period() 0.1su64 quota; // cfs task_group 在一个监控周期内的运行时间配额,默认值是RUNTIME_INF,无限大u64 runtime; // cfs task_group 在一个监控周期内剩余可运行的时间s64 hierarchical_quota;u64 runtime_expires;int idle, period_active;struct hrtimer period_timer;struct hrtimer slack_timer;struct list_head throttled_cfs_rq;/* statistics */int nr_periods, nr_throttled;u64 throttled_time;};
其中几个关键的数据结构:cfs_b->period是监控周期,cfs_b->quota是tg的运行配额,cfs_b->runtime是tg剩余可运行的时间。cfs_b->runtime在监控周期开始的时候等于cfs_b->quota,随着tg不断运行不断减少,如果cfs_b->runtime < 0说明tg已经超过bandwidth,触发流量控制;
cfs bandwidth是提供给CGROUP_SCHED使用的,所以cfs_b->quota的初始值都是RUNTIME_INF无限大,所以在使能CGROUP_SCHED以后需要自己配置这些参数。
2、因为一个task_group是在percpu上都创建了一个cfs_rq,所以cfs_b->quota的值是这些percpu cfs_rq中的进程共享的,每个percpu cfs_rq在运行时需要向tg->cfs_bandwidth->runtime来申请;
scheduler_tick() -> task_tick_fair() -> entity_tick() -> update_curr() -> account_cfs_rq_runtime()↓static __always_inlinevoid account_cfs_rq_runtime(struct cfs_rq *cfs_rq, u64 delta_exec){if (!cfs_bandwidth_used() || !cfs_rq->runtime_enabled)return;__account_cfs_rq_runtime(cfs_rq, delta_exec);}|→static void __account_cfs_rq_runtime(struct cfs_rq *cfs_rq, u64 delta_exec){/* (1) 用cfs_rq已经申请的时间配额(cfs_rq->runtime_remaining)减去已经消耗的时间 *//* dock delta_exec before expiring quota (as it could span periods) */cfs_rq->runtime_remaining -= delta_exec;/* (2) expire超期时间的判断 */expire_cfs_rq_runtime(cfs_rq);/* (3) 如果cfs_rq已经申请的时间配额还没用完,返回 */if (likely(cfs_rq->runtime_remaining > 0))return;/** if we're unable to extend our runtime we resched so that the active* hierarchy can be throttled*//* (4) 如果cfs_rq申请的时间配额已经用完,尝试向tg的cfs_b->runtime申请新的时间片如果申请新时间片失败,说明整个tg已经没有可运行时间了,把本进程设置为需要重新调度,在中断返回,发起schedule()时,发现cfs_rq->runtime_remaining<=0,会调用throttle_cfs_rq()对cfs_rq进行实质的限制*/if (!assign_cfs_rq_runtime(cfs_rq) && likely(cfs_rq->curr))resched_curr(rq_of(cfs_rq));}||→static int assign_cfs_rq_runtime(struct cfs_rq *cfs_rq){struct task_group *tg = cfs_rq->tg;struct cfs_bandwidth *cfs_b = tg_cfs_bandwidth(tg);u64 amount = 0, min_amount, expires;/* (4.1) cfs_b的分配时间片的默认值是5ms *//* note: this is a positive sum as runtime_remaining <= 0 */min_amount = sched_cfs_bandwidth_slice() - cfs_rq->runtime_remaining;raw_spin_lock(&cfs_b->lock);if (cfs_b->quota == RUNTIME_INF)/* (4.2) RUNTIME_INF类型,时间是分配不完的 */amount = min_amount;else {start_cfs_bandwidth(cfs_b);/* (4.3) 剩余时间cfs_b->runtime减去分配的时间片 */if (cfs_b->runtime > 0) {amount = min(cfs_b->runtime, min_amount);cfs_b->runtime -= amount;cfs_b->idle = 0;}}expires = cfs_b->runtime_expires;raw_spin_unlock(&cfs_b->lock);/* (4.4) 分配的时间片赋值给cfs_rq */cfs_rq->runtime_remaining += amount;/** we may have advanced our local expiration to account for allowed* spread between our sched_clock and the one on which runtime was* issued.*/if ((s64)(expires - cfs_rq->runtime_expires) > 0)cfs_rq->runtime_expires = expires;/* (4.5) 判断分配时间是否足够? */return cfs_rq->runtime_remaining > 0;}
3、在enqueue_task_fair()、put_prev_task_fair()、pick_next_task_fair()这几个时刻,会check cfs_rq是否已经达到throttle,如果达到cfs throttle会把cfs_rq dequeue停止运行;
enqueue_task_fair() -> enqueue_entity() -> check_enqueue_throttle() -> throttle_cfs_rq()put_prev_task_fair() -> put_prev_entity() -> check_cfs_rq_runtime() -> throttle_cfs_rq()pick_next_task_fair() -> check_cfs_rq_runtime() -> throttle_cfs_rq()static void check_enqueue_throttle(struct cfs_rq *cfs_rq){if (!cfs_bandwidth_used())return;/* an active group must be handled by the update_curr()->put() path */if (!cfs_rq->runtime_enabled || cfs_rq->curr)return;/* (1.1) 如果已经throttle,直接返回 *//* ensure the group is not already throttled */if (cfs_rq_throttled(cfs_rq))return;/* update runtime allocation *//* (1.2) 更新最新的cfs运行时间 */account_cfs_rq_runtime(cfs_rq, 0);/* (1.3) 如果cfs_rq->runtime_remaining<=0,启动throttle */if (cfs_rq->runtime_remaining <= 0)throttle_cfs_rq(cfs_rq);}/* conditionally throttle active cfs_rq's from put_prev_entity() */static bool check_cfs_rq_runtime(struct cfs_rq *cfs_rq){if (!cfs_bandwidth_used())return false;/* (2.1) 如果cfs_rq->runtime_remaining还有运行时间,直接返回 */if (likely(!cfs_rq->runtime_enabled || cfs_rq->runtime_remaining > 0))return false;/** it's possible for a throttled entity to be forced into a running* state (e.g. set_curr_task), in this case we're finished.*//* (2.2) 如果已经throttle,直接返回 */if (cfs_rq_throttled(cfs_rq))return true;/* (2.3) 已经throttle,执行throttle动作 */throttle_cfs_rq(cfs_rq);return true;}static void throttle_cfs_rq(struct cfs_rq *cfs_rq){struct rq *rq = rq_of(cfs_rq);struct cfs_bandwidth *cfs_b = tg_cfs_bandwidth(cfs_rq->tg);struct sched_entity *se;long task_delta, dequeue = 1;bool empty;se = cfs_rq->tg->se[cpu_of(rq_of(cfs_rq))];/* freeze hierarchy runnable averages while throttled */rcu_read_lock();walk_tg_tree_from(cfs_rq->tg, tg_throttle_down, tg_nop, (void *)rq);rcu_read_unlock();task_delta = cfs_rq->h_nr_running;for_each_sched_entity(se) {struct cfs_rq *qcfs_rq = cfs_rq_of(se);/* throttled entity or throttle-on-deactivate */if (!se->on_rq)break;/* (3.1) throttle的动作1:将cfs_rq dequeue停止运行 */if (dequeue)dequeue_entity(qcfs_rq, se, DEQUEUE_SLEEP);qcfs_rq->h_nr_running -= task_delta;if (qcfs_rq->load.weight)dequeue = 0;}if (!se)sub_nr_running(rq, task_delta);/* (3.2) throttle的动作2:将cfs_rq->throttled置位 */cfs_rq->throttled = 1;cfs_rq->throttled_clock = rq_clock(rq);raw_spin_lock(&cfs_b->lock);empty = list_empty(&cfs_b->throttled_cfs_rq);/** Add to the _head_ of the list, so that an already-started* distribute_cfs_runtime will not see us*/list_add_rcu(&cfs_rq->throttled_list, &cfs_b->throttled_cfs_rq);/** If we're the first throttled task, make sure the bandwidth* timer is running.*/if (empty)start_cfs_bandwidth(cfs_b);raw_spin_unlock(&cfs_b->lock);}
4、对每一个tg的cfs_b,系统会启动一个周期性定时器cfs_b->period_timer,运行周期为cfs_b->period。主要作用是period到期后检查是否有cfs_rq被throttle,如果被throttle恢复它,并进行新一轮的监控;
sched_cfs_period_timer() -> do_sched_cfs_period_timer()↓static int do_sched_cfs_period_timer(struct cfs_bandwidth *cfs_b, int overrun){u64 runtime, runtime_expires;int throttled;/* no need to continue the timer with no bandwidth constraint */if (cfs_b->quota == RUNTIME_INF)goto out_deactivate;throttled = !list_empty(&cfs_b->throttled_cfs_rq);cfs_b->nr_periods += overrun;/** idle depends on !throttled (for the case of a large deficit), and if* we're going inactive then everything else can be deferred*/if (cfs_b->idle && !throttled)goto out_deactivate;/* (1) 新周期的开始,给cfs_b->runtime重新赋值为cfs_b->quota */__refill_cfs_bandwidth_runtime(cfs_b);if (!throttled) {/* mark as potentially idle for the upcoming period */cfs_b->idle = 1;return 0;}/* account preceding periods in which throttling occurred */cfs_b->nr_throttled += overrun;runtime_expires = cfs_b->runtime_expires;/** This check is repeated as we are holding onto the new bandwidth while* we unthrottle. This can potentially race with an unthrottled group* trying to acquire new bandwidth from the global pool. This can result* in us over-using our runtime if it is all used during this loop, but* only by limited amounts in that extreme case.*//* (2) 解除cfs_b->throttled_cfs_rq中所有被throttle住的cfs_rq */while (throttled && cfs_b->runtime > 0) {runtime = cfs_b->runtime;raw_spin_unlock(&cfs_b->lock);/* we can't nest cfs_b->lock while distributing bandwidth */runtime = distribute_cfs_runtime(cfs_b, runtime,runtime_expires);raw_spin_lock(&cfs_b->lock);throttled = !list_empty(&cfs_b->throttled_cfs_rq);cfs_b->runtime -= min(runtime, cfs_b->runtime);}/** While we are ensured activity in the period following an* unthrottle, this also covers the case in which the new bandwidth is* insufficient to cover the existing bandwidth deficit. (Forcing the* timer to remain active while there are any throttled entities.)*/cfs_b->idle = 0;return 0;out_deactivate:return 1;}|→static u64 distribute_cfs_runtime(struct cfs_bandwidth *cfs_b,u64 remaining, u64 expires){struct cfs_rq *cfs_rq;u64 runtime;u64 starting_runtime = remaining;rcu_read_lock();list_for_each_entry_rcu(cfs_rq, &cfs_b->throttled_cfs_rq,throttled_list) {struct rq *rq = rq_of(cfs_rq);raw_spin_lock(&rq->lock);if (!cfs_rq_throttled(cfs_rq))goto next;runtime = -cfs_rq->runtime_remaining + 1;if (runtime > remaining)runtime = remaining;remaining -= runtime;cfs_rq->runtime_remaining += runtime;cfs_rq->runtime_expires = expires;/* (2.1) 解除throttle *//* we check whether we're throttled above */if (cfs_rq->runtime_remaining > 0)unthrottle_cfs_rq(cfs_rq);next:raw_spin_unlock(&rq->lock);if (!remaining)break;}rcu_read_unlock();return starting_runtime - remaining;}||→void unthrottle_cfs_rq(struct cfs_rq *cfs_rq){struct rq *rq = rq_of(cfs_rq);struct cfs_bandwidth *cfs_b = tg_cfs_bandwidth(cfs_rq->tg);struct sched_entity *se;int enqueue = 1;long task_delta;se = cfs_rq->tg->se[cpu_of(rq)];cfs_rq->throttled = 0;update_rq_clock(rq);raw_spin_lock(&cfs_b->lock);cfs_b->throttled_time += rq_clock(rq) - cfs_rq->throttled_clock;list_del_rcu(&cfs_rq->throttled_list);raw_spin_unlock(&cfs_b->lock);/* update hierarchical throttle state */walk_tg_tree_from(cfs_rq->tg, tg_nop, tg_unthrottle_up, (void *)rq);if (!cfs_rq->load.weight)return;task_delta = cfs_rq->h_nr_running;for_each_sched_entity(se) {if (se->on_rq)enqueue = 0;cfs_rq = cfs_rq_of(se);/* (2.1.1) 重新enqueue运行 */if (enqueue)enqueue_entity(cfs_rq, se, ENQUEUE_WAKEUP);cfs_rq->h_nr_running += task_delta;if (cfs_rq_throttled(cfs_rq))break;}if (!se)add_nr_running(rq, task_delta);/* determine whether we need to wake up potentially idle cpu */if (rq->curr == rq->idle && rq->cfs.nr_running)resched_curr(rq);}
1.2.8、sched sysctl参数
系统在sysctl中注册了很多sysctl参数供我们调优使用,在”/proc/sys/kernel/”目录下可以看到:
# ls /proc/sys/kernel/sched_*sched_cfs_boostsched_child_runs_first // fork子进程后,子进程是否先于父进程运行sched_latency_ns // 计算cfs period,如果runnable数量小于sched_nr_latency,返回的最小period值,单位nssched_migration_cost_nssched_min_granularity_ns // 计算cfs period,如果runnable数量大于sched_nr_latency,每个进程可占用的时间,单位nscfs period = nr_running * sysctl_sched_min_granularity;sched_nr_migratesched_rr_timeslice_ms // SCHED_RR类型的rt进程每个时间片的大小,单位mssched_rt_period_us // rt-throttle的计算周期sched_rt_runtime_us // 一个rt-throttle计算周期内,rt进程可运行的时间sched_shares_window_nssched_time_avg_ms // rt负载(rq->rt_avg)的老化周期sched_tunable_scalingsched_wakeup_granularity_ns
kern_table[]中也有相关的定义:
static struct ctl_table kern_table[] = {{.procname = "sched_child_runs_first",.data = &sysctl_sched_child_runs_first,.maxlen = sizeof(unsigned int),.mode = 0644,.proc_handler = proc_dointvec,},{.procname = "sched_min_granularity_ns",.data = &sysctl_sched_min_granularity,.maxlen = sizeof(unsigned int),.mode = 0644,.proc_handler = sched_proc_update_handler,.extra1 = &min_sched_granularity_ns,.extra2 = &max_sched_granularity_ns,},{.procname = "sched_latency_ns",.data = &sysctl_sched_latency,.maxlen = sizeof(unsigned int),.mode = 0644,.proc_handler = sched_proc_update_handler,.extra1 = &min_sched_granularity_ns,.extra2 = &max_sched_granularity_ns,},{.procname = "sched_wakeup_granularity_ns",.data = &sysctl_sched_wakeup_granularity,.maxlen = sizeof(unsigned int),.mode = 0644,.proc_handler = sched_proc_update_handler,.extra1 = &min_wakeup_granularity_ns,.extra2 = &max_wakeup_granularity_ns,},{.procname = "sched_tunable_scaling",.data = &sysctl_sched_tunable_scaling,.maxlen = sizeof(enum sched_tunable_scaling),.mode = 0644,.proc_handler = sched_proc_update_handler,.extra1 = &min_sched_tunable_scaling,.extra2 = &max_sched_tunable_scaling,},{.procname = "sched_migration_cost_ns",.data = &sysctl_sched_migration_cost,.maxlen = sizeof(unsigned int),.mode = 0644,.proc_handler = proc_dointvec,},{.procname = "sched_nr_migrate",.data = &sysctl_sched_nr_migrate,.maxlen = sizeof(unsigned int),.mode = 0644,.proc_handler = proc_dointvec,},{.procname = "sched_time_avg_ms",.data = &sysctl_sched_time_avg,.maxlen = sizeof(unsigned int),.mode = 0644,.proc_handler = proc_dointvec,},{.procname = "sched_shares_window_ns",.data = &sysctl_sched_shares_window,.maxlen = sizeof(unsigned int),.mode = 0644,.proc_handler = proc_dointvec,},{.procname = "sched_rt_period_us",.data = &sysctl_sched_rt_period,.maxlen = sizeof(unsigned int),.mode = 0644,.proc_handler = sched_rt_handler,},{.procname = "sched_rt_runtime_us",.data = &sysctl_sched_rt_runtime,.maxlen = sizeof(int),.mode = 0644,.proc_handler = sched_rt_handler,},{.procname = "sched_rr_timeslice_ms",.data = &sched_rr_timeslice,.maxlen = sizeof(int),.mode = 0644,.proc_handler = sched_rr_handler,},{.procname = "sched_autogroup_enabled",.data = &sysctl_sched_autogroup_enabled,.maxlen = sizeof(unsigned int),.mode = 0644,.proc_handler = proc_dointvec_minmax,.extra1 = &zero,.extra2 = &one,},{.procname = "sched_cfs_bandwidth_slice_us",.data = &sysctl_sched_cfs_bandwidth_slice,.maxlen = sizeof(unsigned int),.mode = 0644,.proc_handler = proc_dointvec_minmax,.extra1 = &one,},{.procname = "sched_cfs_boost",.data = &sysctl_sched_cfs_boost,.maxlen = sizeof(sysctl_sched_cfs_boost),.mode = 0444,.mode = 0644,.proc_handler = &sysctl_sched_cfs_boost_handler,.extra1 = &zero,.extra2 = &one_hundred,},}
1.2.9、”/proc/sched_debug”
在/proc/sched_debug中会打印出详细的schedule相关的信息,对应的代码在”kernel/sched/debug.c”中实现:
# cat /proc/sched_debugSched Debug Version: v0.11, 4.4.22+ #95ktime : 1036739325.473178sched_clk : 1036739500.521349cpu_clk : 1036739500.521888jiffies : 4554077128sysctl_sched: 10.000000: 2.250000: 2.000000: 0: 233275: 0 (none): Online: 1 // rq->nr_running,rq中总的可运行进程数,包括cfs_rq + cfs_rq + dl_rq: 1024 // rq->load.weight,rq总的weight值: 288653745: 102586831: 386195: 4554.077177: 5839 // rq->curr当前进程的pid: 1036739583.441965 // rq总的运行时间,单位s: 1036739583.441965 // rq总的task运行时间,单位s: 178 // cpu级别的负载值,rq->cpu_load[]: 341: 646: 633: 448: 495661: 290639530: 95041623: 66000: 33000: 169556205: 156832675:/bg_non_interactive // 叶子cfs_rq,“/bg_non_interactive ”: 2008394.796159 // cfs_rq->exec_clock): 0.000001: 4932671.018182: 0.000001: 0.000000: -148755265.877002: 5018: 0 // cfs_rq->nr_running,cfs_rq中总的可运行进程数: 0 // cfs_rq->load.weight: 0 // cfs_rq->avg.load_avg: 0 // cfs_rq->runnable_load_avg: 0 // cfs_rq->avg.util_avg: 0: 0: 0: 943: 1036739470.724118 // print_cfs_group_stats(),se = cfs_rq->tg->se[cpu]: 153687902.677263: 2008952.798927: 0.000000: 0.000000: 0.000000: 0.000000: 0.000000: 384.672539: 110.416539: 461.053539: 4583320.426021: 4310369: 2: 0: 0:/ // 根cfs_rq,“/”: 148912219.736328: 0.000001: 153687936.895184: 0.000001: 0.000000: 0.000000: 503579: 1: 1024: 4815: 168: 63: 0: 0: 4815: 9051:/bg_non_interactive // 叶子rt_rq,“/bg_non_interactive ”: 0: 0: 0.000000: 700.000000:/ // 根rt_rq,“/”: 0: 0: 0.000000: 800.000000: // dl_rq: 0runnable tasks: // 并不是rq中现在的runnable进程,而是逐个遍历进程,看看哪个进程最后是在当前cpu上运行。很多进程现在是睡眠状态;上述的rq->nr_running=1,只有一个进程处于runnable状态。但是打印出了几十条睡眠状态的进程;第一列"R",说明是当前运行的进程rq->curr"tree-key",p->se.vruntime // 进程的vruntime"wait-time",p->se.statistics.wait_sum // 进程在整个运行队列中的时间,runnable+running时间"sum-exec",p->se.sum_exec_runtime // 进程的执行累加时间,running时间"sum-sleep",p->se.statistics.sum_sleep_runtime // 进程的睡眠时间task PID tree-key switches prio wait-time sum-exec sum-sleep----------------------------------------------------------------------------------------------------------init 1 153554847.251576 11927 120 23938.628500 23714.949808 1036236697.068574 /kthreadd 2 153613100.582264 7230 120 4231.780138 11601.352220 1036459940.732829 /3 153687920.598799 2123535 120 2612543.672044 485896.233949 1033641057.952048 /:0H 5 867.040456 6 100 1.690538 2.306692 13011.504340 /rcu_preempt 7 153687932.055261 38012901 120 19389366.435276 4762068.709434 1012596083.722693 /rcu_sched 8 153687932.006723 9084101 120 9536442.439335 832973.285818 1026372474.208896 /rcu_bh 9 44.056109 2 120 3.062001 0.071692 0.000000 /10 0.000000 810915 0 0.157999 1405490.418215 0.000000 /writeback 41 75740016.734657 11 100 6.979694 22.657923 515725974.508217 /cfg80211 68 145389776.829002 16 100 19.614385 22.409536 981346170.111828 /pmic_thread 69 -4.853692 59 1 0.000000 416.570075 90503.424677 /cfinteractive 70 0.000000 6128239 0 0.000000 835706.912900 0.000000 /ion_history 74 153687775.391059 1077475 120 598925.096753 155563.560671 1035979729.028569 /vmstat 88 153613102.428420 581 100 628.318084 213.543232 1036470246.848623 /: Online: 2: 2048: 50330891: 18465962: -282929: 4554.077177: 5914: 1036739631.224580: 1036739631.224580: 304: 271: 371: 442: 451: 328297: 52031170: 13402190: 157078: 78539: 28394891: 19995708:/bg_non_interactive: 577939.399761: 0.000001: 879925.689476: 0.000001: 0.000000: -152808035.003624: 3440: 0: 0: 0: 0: 0: 0: 0: 0: 943: 1036722623.319617: 56084769.222524: 578346.130491: 0.000000: 0.000000: 0.000000: 0.000000: 0.000000: 268.577308: 158.383846: 449.603155: 474626.775818: 405003: 2: 0: 1:/: 42386409.280566: 0.000001: 56084976.869536: 0.000001: 0.000000: -97602983.874333: 104638: 1: 1024: 2629: 303: 194: 230: 55: 2629: 8008:/bg_non_interactive: 0: 0: 0.000000: 700.000000:/: 0: 0: 0.240462: 800.000000:: 0runnable tasks:task PID tree-key switches prio wait-time sum-exec sum-sleep----------------------------------------------------------------------------------------------------------kthreadd 2 56084963.882383 7231 120 4231.780138 11602.057297 1036723552.983919 /rcu_preempt 7 56084971.464306 38012914 120 19389373.432429 4762070.363433 1012596123.004465 /11 0.000000 920361 0 0.195462 1119760.329035 0.000000 /12 56084941.917306 1503624 120 2051568.246464 208690.852721 84770006.156114 /:0 13 56084928.574845 1593806 120 2819612.156152 3042907.328028 1030879705.296110 /:0H 14 56084928.506641 769028 100 87134.568064 44580.172387 1036607480.393581 /66 56032835.789987 1290 120 897.904397 265.639693 1035373385.155010 /ion_mm_heap 71 33752638.207281 11146 120 880.444199 1770.794336 525416463.703157 /gpu_dvfs_host_r 134 33752390.546093 127 120 1065.321542 11.329230 525417797.621171 /
# cat /proc/schedstatversion 15timestamp 4555707576cpu0 498206 0 292591647 95722605 170674079 157871909 155819980602662 147733290481281 195127878 /* runqueue-specific stats */domain0 003 5 5 0 0 0 0 0 5 0 0 0 0 0 0 0 0 7 7 0 0 0 0 7 0 0 0 0 0 0 0 0 0 0 14 1 0 /* domain-specific stats */domain1 113 5 5 0 0 0 0 0 5 0 0 0 0 0 0 0 0 7 7 0 0 0 0 0 7 0 0 0 0 0 0 0 0 0 17 0 0cpu1 329113 0 52366034 13481657 28584254 20127852 44090575379688 34066018366436 37345579domain0 003 4 4 0 0 0 0 1 3 0 0 0 0 0 0 0 0 4 3 0 2 1 0 2 1 0 0 0 0 0 0 0 0 0 9 3 0domain1 113 4 4 0 0 0 0 0 1 0 0 0 0 0 0 0 0 3 3 0 0 0 0 0 3 0 0 0 0 0 0 0 0 0 7 0 0cpu4 18835 0 13439942 5205662 8797513 2492988 14433736408037 4420752361838 7857723domain0 113 0 0 0 0 1 0 0 0 1 1 0 0 0 0 0 1 3 2 1 201 0 0 0 2 1 0 1 0 0 0 0 0 0 8 7 0cpu8 32417 0 13380391 4938475 9351290 2514217 10454988559488 3191584640696 7933881domain0 113 1 1 0 0 0 0 0 1 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 7 8 0
可以通过”/proc/pid/schedstat”读出进程级别的调度统计,具体的代码在fs/proc/base.c proc_pid_schedstat()中:
29099619 5601999 20 /* task->se.sum_exec_runtime, task->sched_info.run_delay, task->sched_info.pcount */
1.3、RT调度算法
分析完normal进程的cfs调度算法,我们再来看看rt进程(SCHED_RR/SCHED_FIFO)的调度算法。RT的调度算法改动很小,组织形式还是以前的链表数组,rq->rt_rq.active.queue[MAX_RT_PRIO]包含100个(0-99)个数组链表用来存储runnable的rt线程。rt进程的调度通过rt_sched_class系列函数来实现。
SCHED_FIFO类型的rt进程调度比较简单,优先级最高的一直运行,直到主动放弃运行。
SCHED_RR类型的rt进程在相同优先级下进行时间片调度,每个时间片的时间长短可以通过sched_rr_timeslice变量来控制:
25
1.3.1、task_tick_rt()
scheduler_tick() -> task_tick_rt()↓static void task_tick_rt(struct rq *rq, struct task_struct *p, int queued){struct sched_rt_entity *rt_se = &p->rt;/* (1) 更新时间统计、rt-throttle计算 */update_curr_rt(rq);/* (2) 更新rt的capacity request */sched_rt_update_capacity_req(rq);watchdog(rq, p);/** RR tasks need a special form of timeslice management.* FIFO tasks have no timeslices.*//* (3) 如果是SCHED_FIFO类型的rt进行,不进行时间片调度直接返回 */if (p->policy != SCHED_RR)return;if (--p->rt.time_slice)return;/* (4) SCHED_RR类型的时间片用完重置时间片,时间片大小为sched_rr_timeslice*/p->rt.time_slice = sched_rr_timeslice;/** Requeue to the end of queue if we (and all of our ancestors) are not* the only element on the queue*//* (5) 如果SCHED_RR类型的时间片已经用完,进行Round-Robin,将当前进程移到本优先级的链表尾部,换链表头部进程运行*/for_each_sched_rt_entity(rt_se) {if (rt_se->run_list.prev != rt_se->run_list.next) {requeue_task_rt(rq, p, 0);resched_curr(rq);return;}}}|→static void update_curr_rt(struct rq *rq){struct task_struct *curr = rq->curr;struct sched_rt_entity *rt_se = &curr->rt;u64 delta_exec;int cpu = rq_cpu(rq);#ifdef CONFIG_MTK_RT_THROTTLE_MONstruct rt_rq *cpu_rt_rq;u64 runtime;u64 old_exec_start;old_exec_start = curr->se.exec_start;#endifif (curr->sched_class != &rt_sched_class)return;per_cpu(update_exec_start, rq->cpu) = curr->se.exec_start;/* (1.1) 计算距离上一次的delta时间 */delta_exec = rq_clock_task(rq) - curr->se.exec_start;if (unlikely((s64)delta_exec <= 0))return;schedstat_set(curr->se.statistics.exec_max,max(curr->se.statistics.exec_max, delta_exec));/* sched:update rt exec info*//* (1.2) 记录当前rt的exec info,在故障时吐出 */per_cpu(exec_task, cpu).pid = curr->pid;per_cpu(exec_task, cpu).prio = curr->prio;strncpy(per_cpu(exec_task, cpu).comm, curr->comm, sizeof(per_cpu(exec_task, cpu).comm));per_cpu(exec_delta_time, cpu) = delta_exec;per_cpu(clock_task, cpu) = rq->clock_task;per_cpu(exec_start, cpu) = curr->se.exec_start;/* (1.3) 统计task所在线程组(thread group)的运行时间:tsk->signal->cputimer.cputime_atomic.sum_exec_runtime*/curr->se.sum_exec_runtime += delta_exec;account_group_exec_runtime(curr, delta_exec);/* (1.4) 更新task所在cgroup之cpuacct的某个cpu运行时间ca->cpuusage[cpu]->cpuusage */curr->se.exec_start = rq_clock_task(rq);cpuacct_charge(curr, delta_exec);/* (1.5) 累加时间*freq_capacity到rq->rt_avg */sched_rt_avg_update(rq, delta_exec);per_cpu(sched_update_exec_start, rq->cpu) = per_cpu(update_curr_exec_start, rq->cpu);per_cpu(update_curr_exec_start, rq->cpu) = sched_clock_cpu(rq->cpu);/* (1.6) 流控使能则进行流控计算 */if (!rt_bandwidth_enabled())return;#ifdef CONFIG_MTK_RT_THROTTLE_MONcpu_rt_rq = rt_rq_of_se(rt_se);runtime = sched_rt_runtime(cpu_rt_rq);if (cpu_rt_rq->rt_time == 0 && !(cpu_rt_rq->rt_throttled)) {if (old_exec_start < per_cpu(rt_period_time, cpu) &&(per_cpu(old_rt_time, cpu) + delta_exec) > runtime) {save_mt_rt_mon_info(cpu, delta_exec, curr);mt_rt_mon_switch(MON_STOP, cpu);mt_rt_mon_print_task(cpu);}mt_rt_mon_switch(MON_RESET, cpu);mt_rt_mon_switch(MON_START, cpu);update_mt_rt_mon_start(cpu, delta_exec);}save_mt_rt_mon_info(cpu, delta_exec, curr);#endiffor_each_sched_rt_entity(rt_se) {struct rt_rq *rt_rq = rt_rq_of_se(rt_se);if (sched_rt_runtime(rt_rq) != RUNTIME_INF) {raw_spin_lock(&rt_rq->rt_runtime_lock);/* (1.7) 流控计算:rt_rq->rt_time:为rt_rq在本周期内已经运行的时间rt_rq->rt_runtime:为rt_rq在本周期内可以运行的时间 //950msrt_rq->tg->rt_bandwidth.rt_period:为一个周期的大小 //1s如果rt_rq->rt_time > rt_rq->rt_runtime,则发生rt-throttle了*/rt_rq->rt_time += delta_exec;if (sched_rt_runtime_exceeded(rt_rq))resched_curr(rq);raw_spin_unlock(&rt_rq->rt_runtime_lock);}}}|→static inline void sched_rt_avg_update(struct rq *rq, u64 rt_delta){/* (1.5.1) 累加时间*freq_capacity到rq->rt_avg ,注意时间单位都是ns*/rq->rt_avg += rt_delta * arch_scale_freq_capacity(NULL, cpu_of(rq));}
1.3.2、rq->rt_avg
我们计算rq->rt_avg(累加时间*freq_capacity),主要目的是给CPU_FREQ_GOV_SCHED使用。
CONFIG_CPU_FREQ_GOV_SCHED的主要思想是cfs和rt分别计算cpu_sched_capacity_reqs中的rt、cfs部分,在update_cpu_capacity_request()中综合cfs和rt的freq_capacity request,调用cpufreq框架调整一个合适的cpu频率。CPU_FREQ_GOV_SCHED是用来取代interactive governor的。
/* (1) cfs对cpu freq capcity的request,per_cpu(cpu_sched_capacity_reqs, cpu).cfs*/static inline void set_cfs_cpu_capacity(int cpu, bool request,unsigned long capacity, int type){if (true) {if (per_cpu(cpu_sched_capacity_reqs, cpu).cfs != capacity) {per_cpu(cpu_sched_capacity_reqs, cpu).cfs = capacity;update_cpu_capacity_request(cpu, request, type);}}/* (2) rt对cpu freq capcity的request,per_cpu(cpu_sched_capacity_reqs, cpu).rt*/static inline void set_rt_cpu_capacity(int cpu, bool request,unsigned long capacity,int type){if (true) {if (per_cpu(cpu_sched_capacity_reqs, cpu).rt != capacity) {per_cpu(cpu_sched_capacity_reqs, cpu).rt = capacity;update_cpu_capacity_request(cpu, request, type);}}|→/* (3) 综合cfs、rt的request,调整cpu频率*/void update_cpu_capacity_request(int cpu, bool request, int type){unsigned long new_capacity;struct sched_capacity_reqs *scr;/* The rq lock serializes access to the CPU's sched_capacity_reqs. */lockdep_assert_held(&cpu_rq(cpu)->lock);scr = &per_cpu(cpu_sched_capacity_reqs, cpu);new_capacity = scr->cfs + scr->rt;new_capacity = new_capacity * capacity_margin_dvfs/ SCHED_CAPACITY_SCALE;new_capacity += scr->dl;if (new_capacity == scr->total)return;scr->total = new_capacity;if (request)update_fdomain_capacity_request(cpu, type);}
针对CONFIG_CPU_FREQ_GOV_SCHED,rt有3条关键计算路径:
1、rt负载的(rq->rt_avg)的累加:scheduler_tick() -> task_tick_rt() -> update_curr_rt() -> sched_rt_avg_update()
2、rt负载的老化:scheduler_tick() -> __update_cpu_load() -> __update_cpu_load() -> sched_avg_update()
或者scheduler_tick() -> task_tick_rt() -> sched_rt_update_capacity_req() -> sched_avg_update()
3、rt request的更新:scheduler_tick() -> task_tick_rt() -> sched_rt_update_capacity_req() -> set_rt_cpu_capacity()
同样,cfs也有3条关键计算路径:
1、cfs负载的(rq->rt_avg)的累加:
2、cfs负载的老化:
3、cfs request的更新:scheduler_tick() -> sched_freq_tick() -> set_cfs_cpu_capacity()
在进行smp的loadbalance时也有相关计算:run_rebalance_domains() -> rebalance_domains() -> load_balance() -> find_busiest_group() -> update_sd_lb_stats() -> update_group_capacity() -> update_cpu_capacity() -> scale_rt_capacity()
我们首先对rt部分的路径进行分析:
rt负载老化sched_avg_update():
void sched_avg_update(struct rq *rq){/* (1) 默认老化周期为1s/2 = 500ms */s64 period = sched_avg_period();while ((s64)(rq_clock(rq) - rq->age_stamp) > period) {/** Inline assembly required to prevent the compiler* optimising this loop into a divmod call.* See __iter_div_u64_rem() for another example of this.*/asm("" : "+rm" (rq->age_stamp));rq->age_stamp += period;/* (2) 每个老化周期,负载老化为原来的1/2 */rq->rt_avg /= 2;rq->dl_avg /= 2;}}|→static inline u64 sched_avg_period(void){/* (1.1) 老化周期 = sysctl_sched_time_avg/2 = 500ms */return (u64)sysctl_sched_time_avg * NSEC_PER_MSEC / 2;}/** period over which we average the RT time consumption, measured* in ms.** default: 1s*/const_debug unsigned int sysctl_sched_time_avg = MSEC_PER_SEC;
rt frq_capability request的更新:scheduler_tick() -> task_tick_rt() -> sched_rt_update_capacity_req() -> set_rt_cpu_capacity()
static void sched_rt_update_capacity_req(struct rq *rq){u64 total, used, age_stamp, avg;s64 delta;if (!sched_freq())return;/* (1) 最新的负载进行老化 */sched_avg_update(rq);/** Since we're reading these variables without serialization make sure* we read them once before doing sanity checks on them.*/age_stamp = READ_ONCE(rq->age_stamp);/* (2) avg=老化后的负载 */avg = READ_ONCE(rq->rt_avg);delta = rq_clock(rq) - age_stamp;if (unlikely(delta < 0))delta = 0;/* (3) total时间=一个老化周期+上次老化剩余时间 */total = sched_avg_period() + delta;/* (4) avg/total=request,(最大频率=1024) */used = div_u64(avg, total);if (unlikely(used > SCHED_CAPACITY_SCALE))used = SCHED_CAPACITY_SCALE;/* (5) update request */set_rt_cpu_capacity(rq->cpu, true, (unsigned long)(used), SCHE_ONESHOT);}
1.3.3、rt bandwidth(rt-throttle)
基于时间我们还可以对的rt进程进行带宽控制(bandwidth),超过流控禁止进程运行。这也叫rt-throttle。
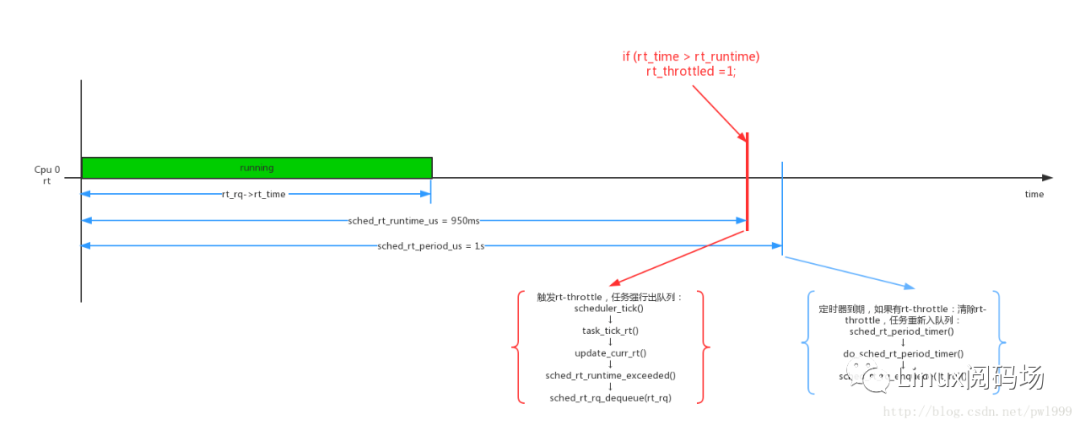
rt-throttle的原理是:规定一个监控周期,在这个周期里rt进程的运行时间不能超过一定时间,如果超过则进入rt-throttle状态,进程被强行停止运行退出rt_rq,且rt_rq也不能接受新的进程来运行,直到下一个周期开始才能退出rt-throttle状态,同时开始下一个周期的bandwidth计算。这样就达到了带宽控制的目的。
1000000950000
上面这个实例的意思就是rt-throttle的周期是1s,1s周期内可以运行的时间为950ms。rt进程在1s以内如果运行时间达到950ms则会被强行停止,1s时间到了以后才会被恢复,这样进程就被强行停止了50ms。
下面我们来具体分析一下具体代码:
scheduler_tick() -> task_tick_rt()↓static void task_tick_rt(struct rq *rq, struct task_struct *p, int queued){/* (1) 更新时间统计、rt-throttle计算 */update_curr_rt(rq);}|→static void update_curr_rt(struct rq *rq){/* (1.6) 流控使能则进行流控计算 */if (!rt_bandwidth_enabled())return;cpu_rt_rq = rt_rq_of_se(rt_se);runtime = sched_rt_runtime(cpu_rt_rq);if (cpu_rt_rq->rt_time == 0 && !(cpu_rt_rq->rt_throttled)) {if (old_exec_start < per_cpu(rt_period_time, cpu) &&(per_cpu(old_rt_time, cpu) + delta_exec) > runtime) {save_mt_rt_mon_info(cpu, delta_exec, curr);mt_rt_mon_switch(MON_STOP, cpu);mt_rt_mon_print_task(cpu);}mt_rt_mon_switch(MON_RESET, cpu);mt_rt_mon_switch(MON_START, cpu);update_mt_rt_mon_start(cpu, delta_exec);}save_mt_rt_mon_info(cpu, delta_exec, curr);for_each_sched_rt_entity(rt_se) {struct rt_rq *rt_rq = rt_rq_of_se(rt_se);if (sched_rt_runtime(rt_rq) != RUNTIME_INF) {raw_spin_lock(&rt_rq->rt_runtime_lock);/* (1.7) 流控计算:rt_rq->rt_time:为rt_rq在本周期内已经运行的时间rt_rq->rt_runtime:为rt_rq在本周期内可以运行的时间 //950msrt_rq->tg->rt_bandwidth.rt_period:为一个周期的大小 //1s如果rt_rq->rt_time > rt_rq->rt_runtime,则发生rt-throttle了*/rt_rq->rt_time += delta_exec;if (sched_rt_runtime_exceeded(rt_rq))resched_curr(rq);raw_spin_unlock(&rt_rq->rt_runtime_lock);}}}||→static int sched_rt_runtime_exceeded(struct rt_rq *rt_rq){u64 runtime = sched_rt_runtime(rt_rq);u64 runtime_pre;if (rt_rq->rt_throttled)return rt_rq_throttled(rt_rq);if (runtime >= sched_rt_period(rt_rq))return 0;/* sched:get runtime*//* (1.7.1) 如果已经达到条件(rt_rq->rt_time > rt_rq->rt_runtime)尝试向同一root_domain的其他cpu来借运行时间进行loadbalance,// 那其他cpu也必须在跑rt任务吧?借了时间以后其他cpu的实时额度会减少iter->rt_runtime -= diff,本cpu的实时额度会增大rt_rq->rt_runtime += diff,*/runtime_pre = runtime;balance_runtime(rt_rq);runtime = sched_rt_runtime(rt_rq);if (runtime == RUNTIME_INF)return 0;/* (1.7.2) 做完loadbalance以后,已运行时间还是超过了额度时间,说明已经达到rt-throttle*/if (rt_rq->rt_time > runtime) {struct rt_bandwidth *rt_b = sched_rt_bandwidth(rt_rq);int cpu = rq_cpu(rt_rq->rq);/* sched:print throttle*/printk_deferred("[name:rt&]sched: initial rt_time %llu, start at %llu\n",per_cpu(init_rt_time, cpu), per_cpu(rt_period_time, cpu));printk_deferred("[name:rt&]sched: cpu=%d rt_time %llu <-> runtime",cpu, rt_rq->rt_time);printk_deferred(" [%llu -> %llu], exec_task[%d:%s], prio=%d, exec_delta_time[%llu]",runtime_pre, runtime,per_cpu(exec_task, cpu).pid,per_cpu(exec_task, cpu).comm,per_cpu(exec_task, cpu).prio,per_cpu(exec_delta_time, cpu));printk_deferred(", clock_task[%llu], exec_start[%llu]\n",per_cpu(clock_task, cpu), per_cpu(exec_start, cpu));printk_deferred("[name:rt&]update[%llu,%llu], pick[%llu, %llu], set_curr[%llu, %llu]\n",per_cpu(update_exec_start, cpu), per_cpu(sched_update_exec_start, cpu),per_cpu(pick_exec_start, cpu), per_cpu(sched_pick_exec_start, cpu),per_cpu(set_curr_exec_start, cpu), per_cpu(sched_set_curr_exec_start, cpu));/** Don't actually throttle groups that have no runtime assigned* but accrue some time due to boosting.*/if (likely(rt_b->rt_runtime)) {/* (1.7.3) rt-throttle标志置位 */rt_rq->rt_throttled = 1;/* sched:print throttle every time*/printk_deferred("sched: RT throttling activated\n");mt_sched_printf(sched_rt_info, "cpu=%d rt_throttled=%d",cpu, rt_rq->rt_throttled);per_cpu(rt_throttling_start, cpu) = rq_clock_task(rt_rq->rq);/* sched:rt throttle monitor */mt_rt_mon_switch(MON_STOP, cpu);mt_rt_mon_print_task(cpu);} else {/** In case we did anyway, make it go away,* replenishment is a joke, since it will replenish us* with exactly 0 ns.*/rt_rq->rt_time = 0;}/* (1.7.4) 如果达到rt-throttle,将rt_rq强行退出运行 */if (rt_rq_throttled(rt_rq)) {sched_rt_rq_dequeue(rt_rq);return 1;}}return 0;}
从上面的代码中可以看到rt-throttle的计算方法大概如下:每个tick累加运行时间rt_rq->rt_time,周期内可运行的额度时间为rt_rq->rt_runtime(950ms),一个周期大小为rt_rq->tg->rt_bandwidth.rt_period(默认1s)。如果(rt_rq->rt_time > rt_rq->rt_runtime),则发生rt-throttle了。
发生rt-throttle以后,rt_rq被强行退出,rt进程被强行停止运行。如果period 1s, runtime 950ms,那么任务会被强制停止50ms。但是下一个周期到来以后,任务需要退出rt-throttle状态。系统把周期计时和退出rt-throttle状态的工作放在hrtimer do_sched_rt_period_timer()中完成。
每个rt进程组task_group公用一个hrtimer sched_rt_period_timer(),在rt task_group创建时分配,在有进程入tg任何一个rt_rq时启动,在没有任务运行时hrtimer会停止运行。
void init_rt_bandwidth(struct rt_bandwidth *rt_b, u64 period, u64 runtime){rt_b->rt_period = ns_to_ktime(period);rt_b->rt_runtime = runtime;raw_spin_lock_init(&rt_b->rt_runtime_lock);/* (1) 初始化hrtimer的到期时间为rt_period_timer,默认1s */hrtimer_init(&rt_b->rt_period_timer,CLOCK_MONOTONIC, HRTIMER_MODE_REL);rt_b->rt_period_timer.function = sched_rt_period_timer;}static void start_rt_bandwidth(struct rt_bandwidth *rt_b){if (!rt_bandwidth_enabled() || rt_b->rt_runtime == RUNTIME_INF)return;raw_spin_lock(&rt_b->rt_runtime_lock);if (!rt_b->rt_period_active) {rt_b->rt_period_active = 1;/* (2) 启动hrtimer */hrtimer_forward_now(&rt_b->rt_period_timer, rt_b->rt_period);hrtimer_start_expires(&rt_b->rt_period_timer, HRTIMER_MODE_ABS_PINNED);}raw_spin_unlock(&rt_b->rt_runtime_lock);}
我们看看timer时间到期后的操作:
static enum hrtimer_restart sched_rt_period_timer(struct hrtimer *timer){struct rt_bandwidth *rt_b =container_of(timer, struct rt_bandwidth, rt_period_timer);int idle = 0;int overrun;raw_spin_lock(&rt_b->rt_runtime_lock);for (;;) {overrun = hrtimer_forward_now(timer, rt_b->rt_period);if (!overrun)break;raw_spin_unlock(&rt_b->rt_runtime_lock);/* (1) 实际的timer处理 */idle = do_sched_rt_period_timer(rt_b, overrun);raw_spin_lock(&rt_b->rt_runtime_lock);}if (idle)rt_b->rt_period_active = 0;raw_spin_unlock(&rt_b->rt_runtime_lock);/* (2) 如果没有rt进程运行,idle状态,则hrtimer退出运行 */return idle ? HRTIMER_NORESTART : HRTIMER_RESTART;}|→static int do_sched_rt_period_timer(struct rt_bandwidth *rt_b, int overrun){int i, idle = 1, throttled = 0;const struct cpumask *span;span = sched_rt_period_mask();#ifdef CONFIG_RT_GROUP_SCHED/** FIXME: isolated CPUs should really leave the root task group,* whether they are isolcpus or were isolated via cpusets, lest* the timer run on a CPU which does not service all runqueues,* potentially leaving other CPUs indefinitely throttled. If* isolation is really required, the user will turn the throttle* off to kill the perturbations it causes anyway. Meanwhile,* this maintains functionality for boot and/or troubleshooting.*/if (rt_b == &root_task_group.rt_bandwidth)span = cpu_online_mask;#endif/* (1.1) 遍历root domain中的每一个cpu */for_each_cpu(i, span) {int enqueue = 0;struct rt_rq *rt_rq = sched_rt_period_rt_rq(rt_b, i);struct rq *rq = rq_of_rt_rq(rt_rq);raw_spin_lock(&rq->lock);per_cpu(rt_period_time, i) = rq_clock_task(rq);if (rt_rq->rt_time) {u64 runtime;/* sched:get runtime*/u64 runtime_pre = 0, rt_time_pre = 0;raw_spin_lock(&rt_rq->rt_runtime_lock);per_cpu(old_rt_time, i) = rt_rq->rt_time;/* (1.2) 如果已经rt_throttled,首先尝试进行load balance */if (rt_rq->rt_throttled) {runtime_pre = rt_rq->rt_runtime;balance_runtime(rt_rq);rt_time_pre = rt_rq->rt_time;}runtime = rt_rq->rt_runtime;/* (1.3) 减少rt_rq->rt_time,一般情况下经过减操作,rt_rq->rt_time=0,相当于新周期重新开始计数*/rt_rq->rt_time -= min(rt_rq->rt_time, overrun*runtime);per_cpu(init_rt_time, i) = rt_rq->rt_time;/* sched:print throttle*/if (rt_rq->rt_throttled) {printk_deferred("[name:rt&]sched: cpu=%d, [%llu -> %llu]",i, rt_time_pre, rt_rq->rt_time);printk_deferred(" -= min(%llu, %d*[%llu -> %llu])\n",rt_time_pre, overrun, runtime_pre, runtime);}/* (1.4)如果之前是rt-throttle,且throttle条件已经不成立(rt_rq->rt_time < runtime),退出rt-throttle*/if (rt_rq->rt_throttled && rt_rq->rt_time < runtime) {/* sched:print throttle*/printk_deferred("sched: RT throttling inactivated cpu=%d\n", i);rt_rq->rt_throttled = 0;mt_sched_printf(sched_rt_info, "cpu=%d rt_throttled=%d",rq_cpu(rq), rq->rt.rt_throttled);enqueue = 1;#ifdef CONFIG_MTK_RT_THROTTLE_MONif (rt_rq->rt_time != 0) {mt_rt_mon_switch(MON_RESET, i);mt_rt_mon_switch(MON_START, i);}#endif/** When we're idle and a woken (rt) task is* throttled check_preempt_curr() will set* skip_update and the time between the wakeup* and this unthrottle will get accounted as* 'runtime'.*/if (rt_rq->rt_nr_running && rq->curr == rq->idle)rq_clock_skip_update(rq, false);}if (rt_rq->rt_time || rt_rq->rt_nr_running)idle = 0;raw_spin_unlock(&rt_rq->rt_runtime_lock);} else if (rt_rq->rt_nr_running) {idle = 0;if (!rt_rq_throttled(rt_rq))enqueue = 1;}if (rt_rq->rt_throttled)throttled = 1;/* (1.5) 退出rt-throttle,将rt_rq重新入队列运行 */if (enqueue)sched_rt_rq_enqueue(rt_rq);raw_spin_unlock(&rq->lock);}if (!throttled && (!rt_bandwidth_enabled() || rt_b->rt_runtime == RUNTIME_INF))return 1;return idle;}
往期课程可扫以下二维码试听与购买

