
Vision Transformers在一系列的视觉任务中取得了巨大的成功。然而,它们通常都需要大量的计算来实现高性能,这在部署在资源有限的设备上这是一个负担。
为了解决这些问题,作者受深度可分离卷积启发设计了深度可分离Vision Transformers,缩写为SepViT。SepViT通过一个深度可分离Self-Attention促进Window内部和Window之间的信息交互。并群欣设计了新的Window Token Embedding和分组Self-Attention方法,分别对计算成本可忽略的Window之间的注意力关系进行建模,并捕获多个Window的长期视觉依赖关系。
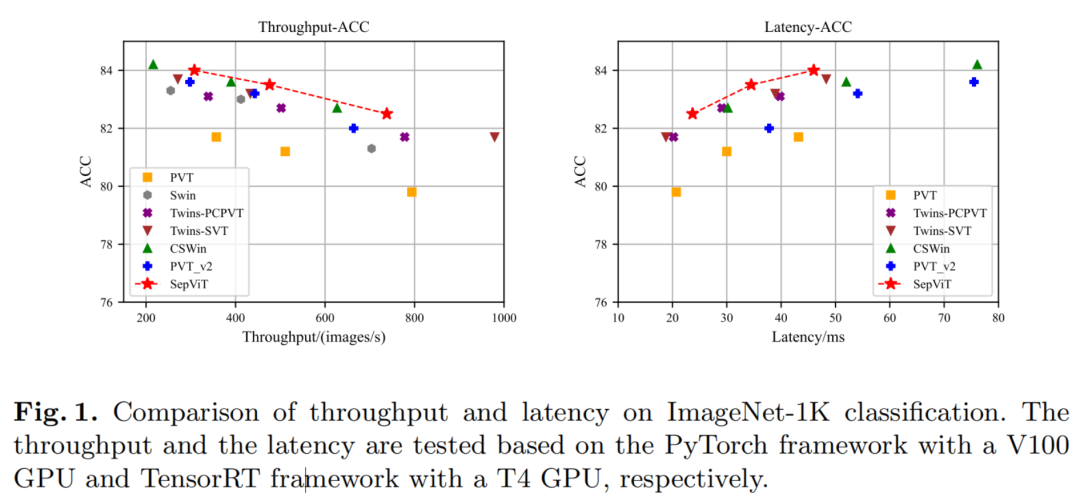
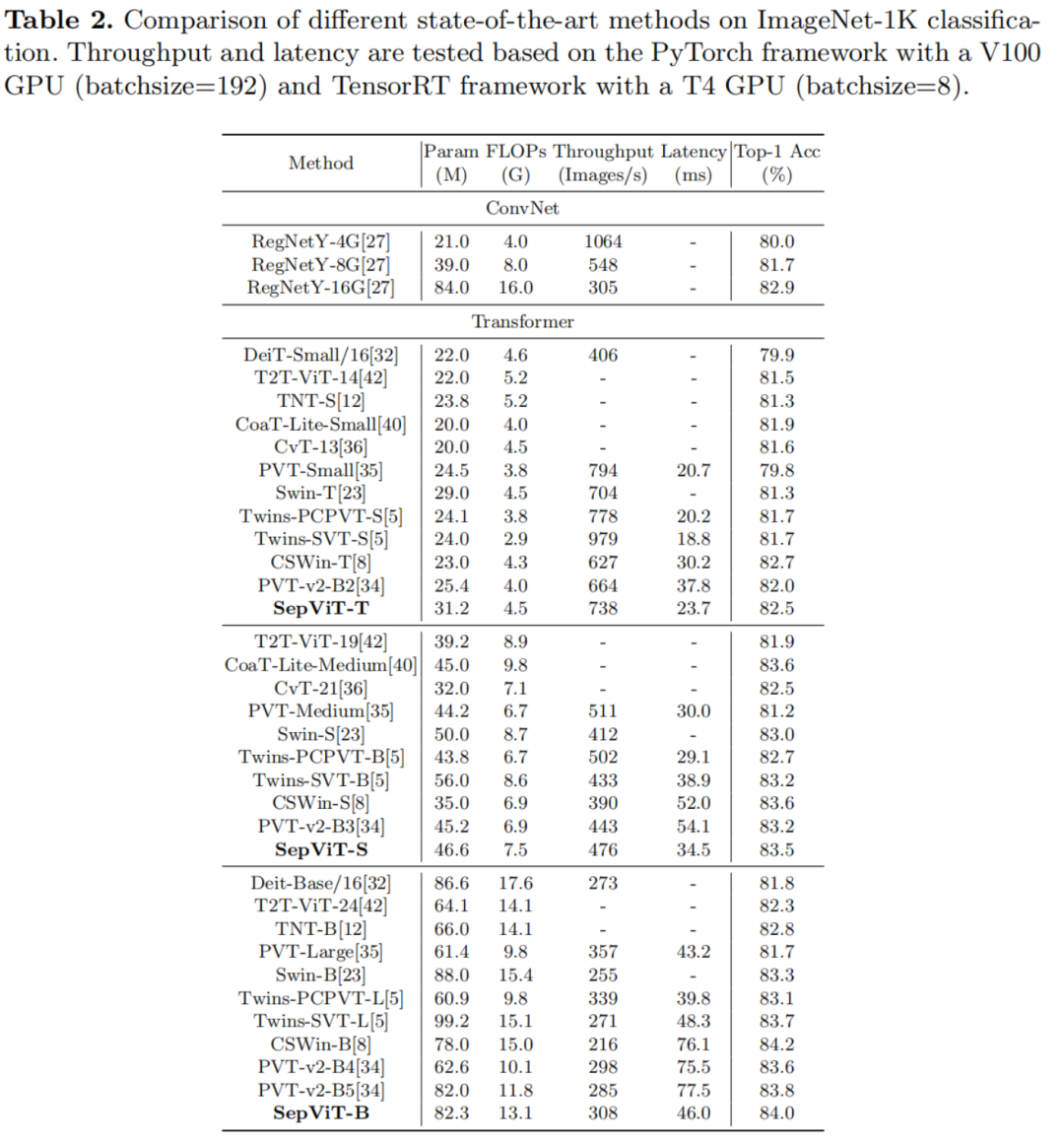
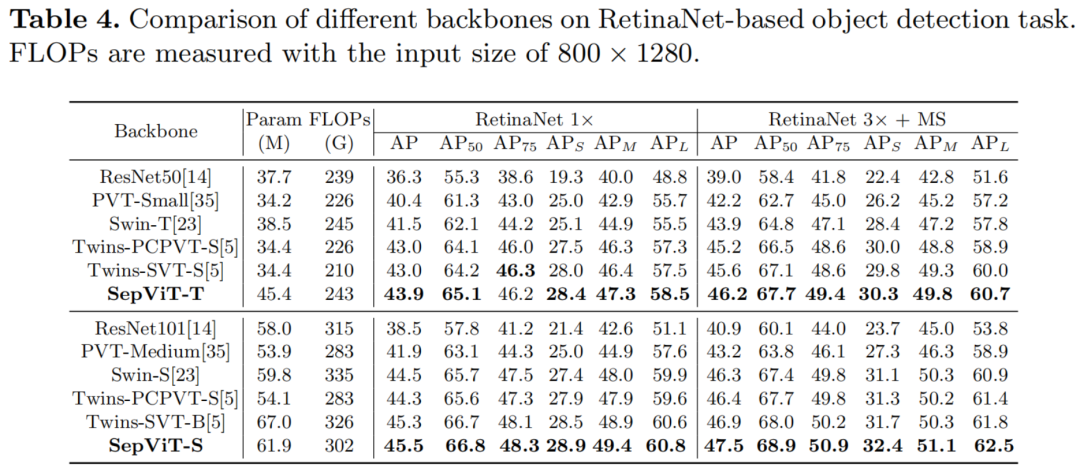
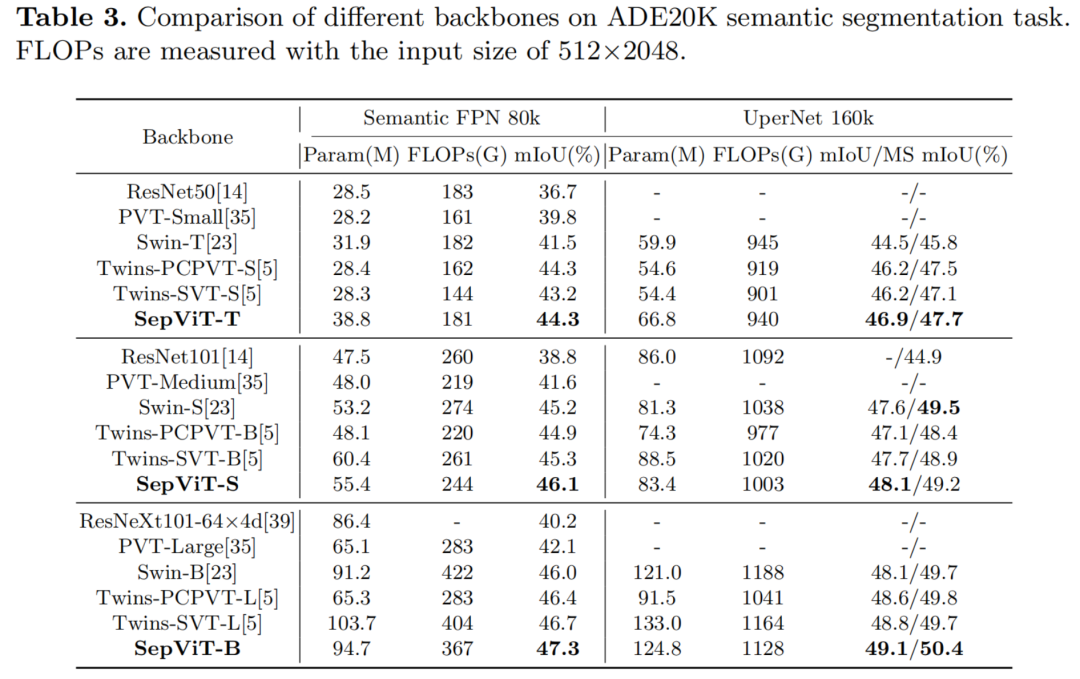
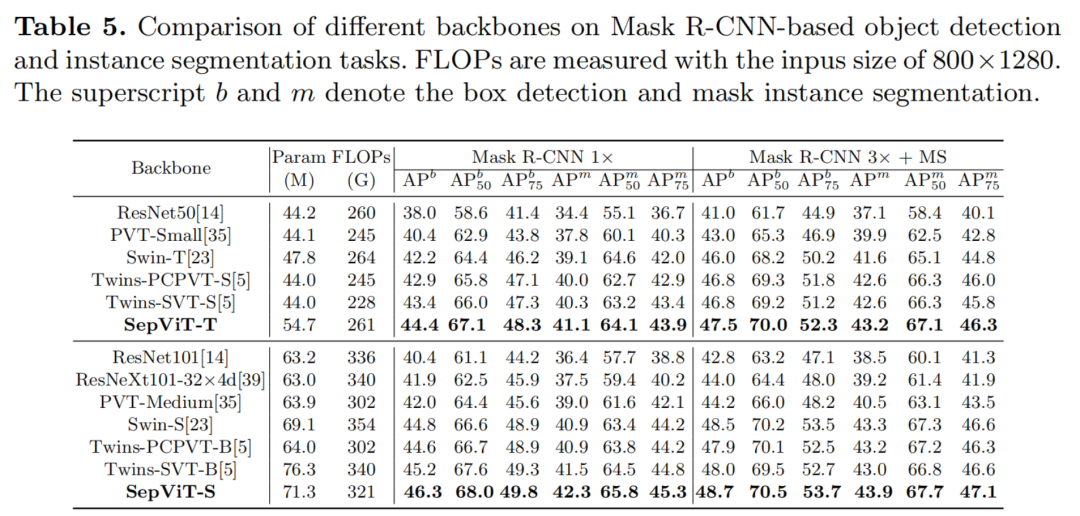
在各种基准测试任务上进行的大量实验表明,SepViT可以在准确性和延迟之间的权衡方面达到最先进的结果。其中,SepViT在ImageNet-1K分类上的准确率达到了84.0%,而延迟率降低了40%。在下游视觉任务中,SepViT在ADE20K语义分割任务达到50.4%的mIoU,基于RetinaNet的COCO目标检测任务达到47.5AP,基于Mask R-CNCN的48.7 box AP检测和分割任务实现43.9 mask AP。
近年来,许多计算机视觉(CV)研究人员致力于设计面向CV的Vision Transformers,以超过卷积神经网络(CNNs)的性能。Vision Transformers具有较高的远距离依赖建模能力,在图像分类、语义分割、目标检测等多种视觉任务中取得了显著的效果。然而,强大的性能通常是以计算复杂度为代价的。
最初,ViT首先将Transformer引入图像识别任务中。它将整个图像分割为几个Patches,并将每个Patch作为一个Token提供给Transformer。然而,由于计算效率低下的Self-Attention,基于Patch的Transformer很难部署。
为了解决这个问题,Swin提出了基于Window的Self-Attention,限制了非重叠子Window中Self-Attention的计算。显然,基于Window的Self-Attention在很大程度上降低了复杂性,但构建Window间连接的Shift操作符给ONNX或TensorRT的部署带来了困难。
Twins利用基于Window的Self-Attention和PVT的Spatial Reduction Attention,提出了空间可分离Self-Attention。尽管Twins是部署友好型的,并且具有出色的性能,但它的计算复杂度几乎没有降低。
CSWin通过Cross-Shaped Window Self-Attention得到了最先进的性能,但吞吐量较低。
尽管在这些著名的Transformer中取得了不同程度的进展,但它最近的大部分成功都伴随着巨大的资源需求。
为了克服上述问题本文提出了一种高效的Transformer Backbone,称为可分离Vision Transformers (SepViT),它可以按顺序捕获局部和全局依赖。SepViT的一个关键设计元素是深度可分离的Self-Attention模块,如图2所示。
受MobileNet中深度可分卷积的启发重新设计了Self-Attention模块,并提出了深度可分离Self-Attention,它由Depthwise Self-Attention和Pointwise Self-Attention组成,分别对应于MobileNet中的Depthwise和PointWise卷积。Depthwise Self-Attention用于捕获每个Window内的局部特征,Pointwise Self-Attention用于构建Window间的连接,提高表达能力。
此外,为了得到局部Window的全局表示开发了一种新的Window Token Embedding方法,该方法可以在极小的计算代价下模拟Window间的注意力关系。此外,还将AlexNet的分组卷积思想扩展到深度可分离Self-Attention,并提出了分组的Self-Attention以进一步提高性能。
为了验证SepViT的有效性,作者对一些典型的视觉任务进行了一系列实验,包括ImageNet-1K分类、ADE20K语义分割、目标检测和实例分割。
实验结果表明,与其他Vision Transformer相比,SepViT能够在性能和延迟之间实现更好的权衡。如图1所示,与具有相同精度的方法相比,在相同延迟约束下,SepViT获得了更好的精度,且推理时间更少。此外,SepViT可以方便地应用和部署,因为它只包含一些通用运算符(例如转置和矩阵乘法等)。综上所述,本文工作的贡献可以总结如下:
在计算机视觉领域,CNN由于其空间归纳偏差的优势而占主导地位。之后,为了模拟像素的全局依赖性,ViT首次将Transformer引入到计算机视觉中,并在图像分类任务上取得了良好的性能。很快,一系列基于ViT技术制作了Vision Transformer。
DeiT介绍了知识蒸馏方案,并提出了数据高效的图像Transformer。
T2T-ViT通过递归地将相邻的Token聚合为一个Token,逐步将图像结构化为Token。
TNT提出了内部和外部的Transformer来分别建模词嵌入和句子嵌入之间的关系。
CPVT产生条件位置编码,该编码基于输入Token的局部邻域,并能适应任意的输入大小。
最近,PVT和Swin同步提出了对密集预测任务(如目标检测、语义和实例分割)友好的层次结构。同时,Swin作为先锋提出了基于Window的Self-Attention来计算Local Window内的注意。
随后,Twins和CSWin相继提出了基于层次结构的空间可分Self-Attention和十字形窗口Self-Attention。
另一方面,一些研究者将CNN的空间感应偏差引入到Transformer中。CoaT、CVT和LeViT在引入了Self-Attention前后引入了卷积,得到了满意的结果。
关于轻量级Transformer的设计,MobileFormer和MobileViT将Transformer块与MobileNet-V2中的Inverted Bottleneck Blocks串联和并行结合。另一个研究方向是利用神经结构搜索技术自动搜索Transformer的结构细节。
针对移动端视觉任务,提出了许多轻量级和移动端友好的卷积方案。其中,分组卷积是由AlexNet首次提出的分组卷积,它对特征映射进行分组并进行分布式训练。
那么,移动端友好卷积的代表性工作必须是具有深度可分离卷积的MobileNet。深度可分离卷积包括用于空间信息通信的Depthwise卷积和用于跨通道信息交换的Pointwise卷积。随着时间的推移,许多基于上述工作的变体被开发出来。在本文的工作中,作者将深度可分离卷积的思想应用到Transformer中,旨在在不牺牲性能的情况下降低Transformer的计算复杂度。
在本节中,首先说明SepViT的设计概述,然后讨论SepViT Block中的一些关键模块。最后,提供了具有不同flop的体系结构。
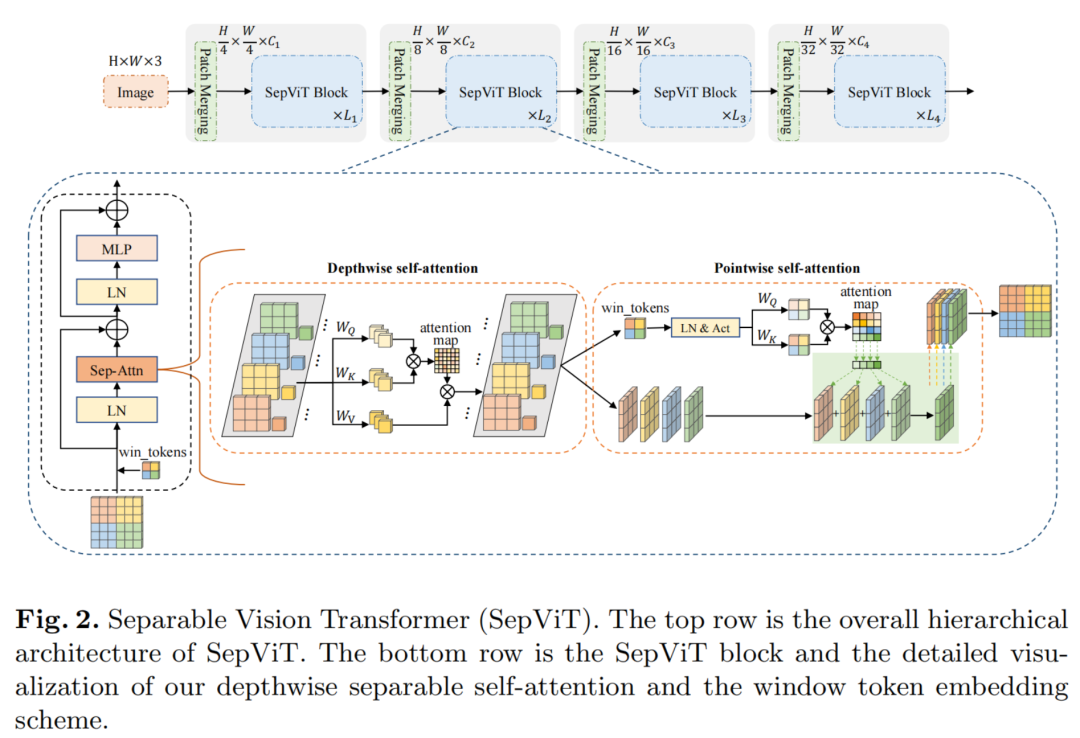
如图2所示,SepViT遵循了广泛使用的层次体系结构和基于Window的Self-Attention。
此外,SepViT还采用了条件位置编码(CPE)。对于每个阶段,都有一个重叠的Patch合并层用于特征图降采样,然后是一系列的SepViT Block。空间分辨率将以stride=4步或stride=2步逐步进行下采样,最终达到32倍下采样,通道尺寸也逐步增加一倍。
值得注意的是,局部上下文和全局信息都可以在单个SepViT Block中捕获,而其他工作应该使用2个连续的Block来完成这种局部-全局建模。
在SepViT块中,每个Window内的局部信息通信是通过DepthWise Self-Attention(DWA)实现的,Window间的全局信息交换是通过PointWise Self-Attention(PWA)进行。
与一些开创性的作品类似,SepViT是建立在基于Window的Self-Attention方案之上的。首先,对输入特征图执行一个Window划分。每个Window都可以看作是特征映射的一个输入通道,而不同的Window包含不同的信息。与之前的工作不同,本文为每个Window创建了一个Window Token,作为一个全局表示,用于在下面的PointWise Self-Attention模块中建模注意力关系。
然后,对每个Window内的所有像素Token及其对应的Window Token执行DepthWise Self-Attention(DWA)。这个Window操作非常类似于MobileNets中的深度卷积层,旨在融合每个通道内的空间信息。
DWA的实现可以总结如下:
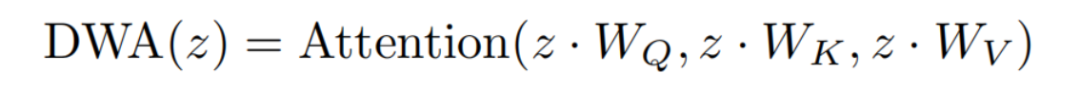
其中z是特征Token,由像素和Window Token组成。、和表示3个线性层,分别用于query、key和value计算的常规Self-Attention。
注意是指在local Window上工作的标准Self-Attention操作符。
建模Window之间的注意力关系的一个直接解决方案是使用所有像素Token。然而,这也将带来巨大的计算成本,使整个模型非常复杂。
为了更好地建立Window之间的注意力关系,提出了一种Window Token Embedding方案,该方案利用单个Token来封装每个子Window的核心信息。这个Window Token可以初始化为固定的零向量,也可以初始化为零的可学习向量。
在通过DWA时,每个Window中的Window Token和像素Token之间存在信息交互。因此,Window Token可以学习此Window的全局表示。由于有效的Window Token,可以用可以忽略的计算代价来建模Window之间的注意关系。
MobileNets中著名的Pointwise Convolution被用来融合来自不同通道的信息。在本文的工作中模仿Pointwise Convolution来设计Pointwise Self-Attention(PWA)模块来建立Window之间的连接。
PWA还主要用于跨Window融合信息,并获得输入特征图的最终表示。更具体地说,从DWA的输出中提取特征映射和Window Token。然后,利用Window Token对Window间的注意力关系进行建模,并在层归一化(LN)层和Gelu激活函数后生成注意力图。同时,直接将特征映射视为PWA的value分支,而不进行任何其他额外的操作。
利用注意力图和特征图的形式,在Window之间进行注意力计算,进行全局信息交换。在形式上,PWA的实现可以描述如下:
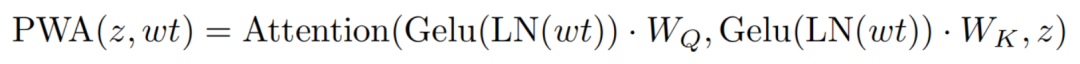
其中,wt表示Window Token。
在这里,注意是一个标准的Self-Attention操作符,但可以在所有的Window z上工作。
给定一个大小为H×W×C的输入特征,在ViT的全局Transformer Block中,Multi-Head Self-Attention(MSA)的计算复杂度为。
Window Size为M×M基于Window的Transformer(通常M是H和WM的共同因素,所以Window的数量为)的复杂性可以在Swin中减少到。
对于SepViT中的深度可分离Self-Attention,其复杂性包括DWA和PWA两部分。
在基于Window的Self-Attention的基础上,DWA具有类似的计算成本。此外,Window Token的引入将会导致额外的成本,但与DWA的总成本相比,这一点可以忽略不计。DWA的复杂度计算方法如下:
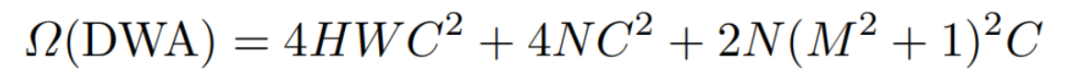
其中是线性层中编码Window Token的额外成本。2N(M2+1)2C表示N个Token的Self-Attention所涉及的矩阵乘法,其中M2+1表示Window中的M2像素Token及其对应的Window Token。由于子Token数量N通常是一个很小的值,Window Token造成的额外开销可以忽略。
由于Window Token总结了本地窗口的全局信息,因此所提出的PWA有助于在窗口级而不是像素级上有效地执行窗口之间的信息交换。具体地说,PWA的复杂性如下:
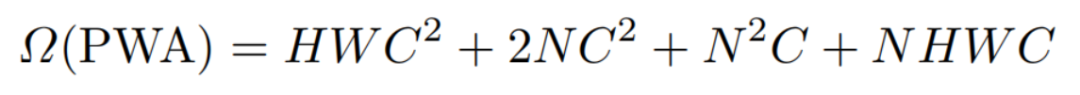
其中,表示用N个Window Token计算query和key的小成本,而value分支为零成本。表示在一个Window上计算生成具有N个Window Token的注意力映射,这在很大程度上节省了PWA的计算成本。最后,NHWC表示注意映射和特征映射之间的矩阵乘法。
介于组卷积在视觉识别中的优异表现,于是作者利用组卷积对深度可分离Self-Attention进行了扩展,并提出了分组Self-Attention。
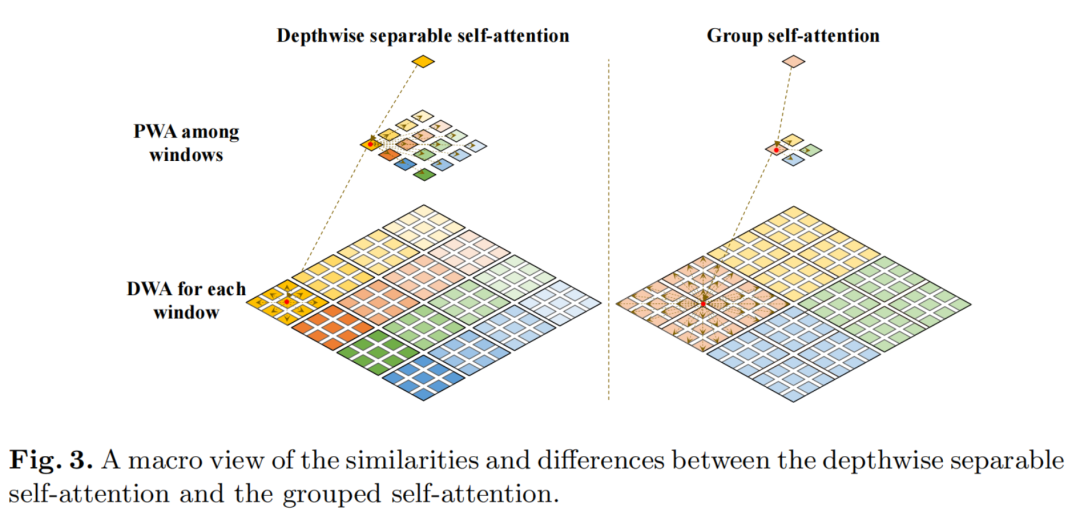
如图3所示,将相邻的子Window拼接,形成更大的Window,类似于将Window分成组,在一组Window内进行深度的Self-Attention通信。通过这种方式,Grouped Self-Attention可以捕获多个Window的长期视觉依赖关系。
在计算成本和性能增益方面,Grouped Self-Attention比深度可分离Self-Attention具有一定的额外成本,但也具有更好的性能。最终,我们将具有Grouped Self-Attention的块应用于SepViT,并在网络的后期与深度可分Self-Attention块交替运行。
综上所述,SepViT块可以表述如下:
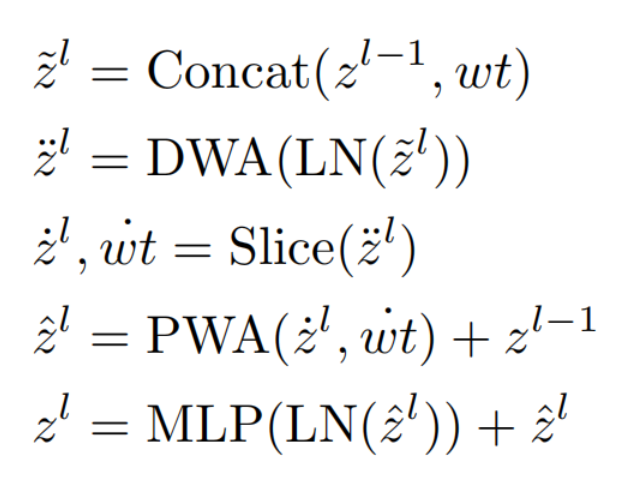
其中,¨zl、ˆzl和zl分别表示DWA、PWA和SepViT块l的输出。˙zl和˙wt是特征映射和学习到的窗口令牌。Concat表示连接操作,而Slice表示切片操作。
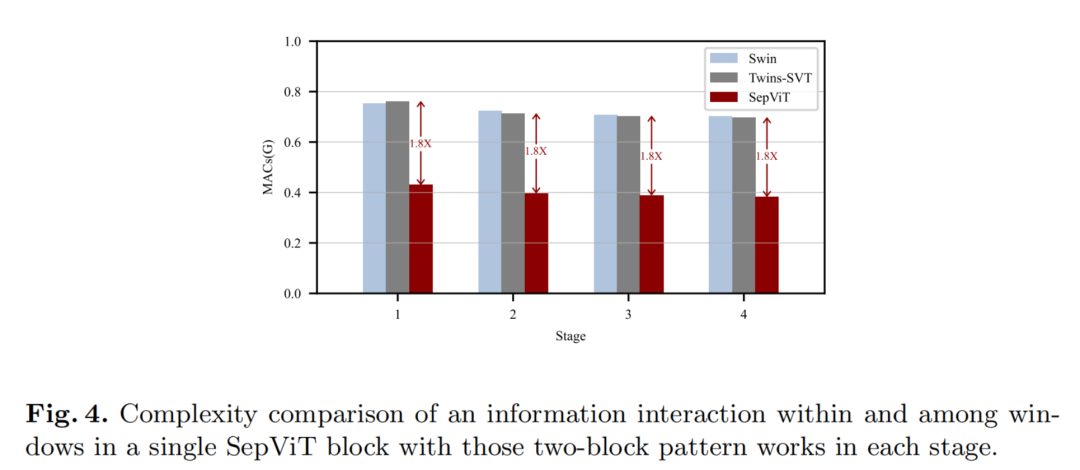
我们比较了我们提出的SepViT块与其他两个SOTA块(Swin,Twins)的复杂性。正如之前所述,Window内和窗口之间的信息交互是在一个SepViT块中完成的,而Swin和Twins需要两个连续的块。
如图4所示,可以观察到,在网络的每个阶段,SepViT块只花费了其竞争对手的Mac的一半左右。原因在于2个方面:
例如,在一个SepViT块中只有一个MLP层和2个LN层,而在2个连续的双块或双块中有双MLP和LN层。
为了与其他vision Transformers进行公平的比较,作者提出了SepVit-t(Tiny)、SepVit-s(Small)和SepVit-b(Base)变种。
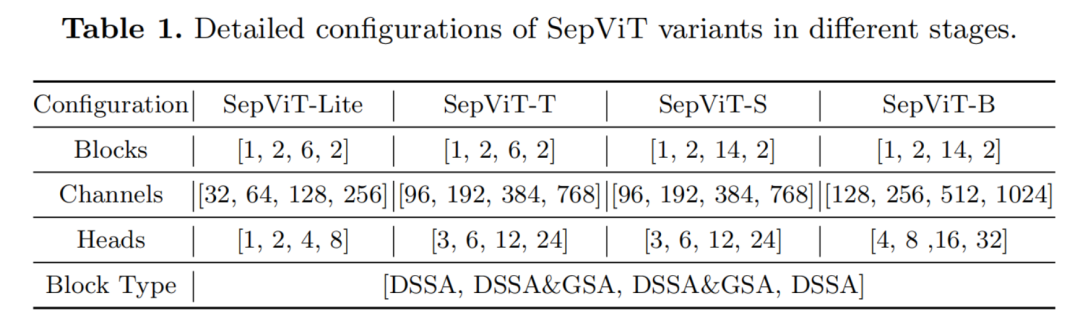
此外,还设计了SepViT-Lite变体与一个非常轻的模型尺寸。SepViT变体的具体配置如表1所示,由于SepViT的效率更高,因此在某些阶段,SepViT的Embedding块深度比竞争对手要小。
DSSA和GSA分别表示具有Depthwise Separable Self-Attention和Grouped Self-Attention Block。此外,每个MLP层的扩展比设置为4,在所有SepViT变体中,DSSA和GSA的Window Sizes分别为7×7和14×14。
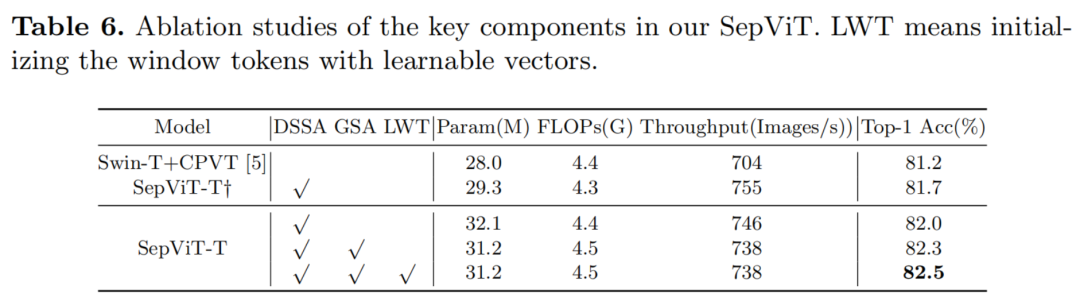
如上所述,SepViT采用了条件位置编码(CPE)和重叠贴片嵌入(OPE)。因此,以Swin-T+CPVT为baseline,并产生带有CPE但不带OPE的SepViT-T,以消除其他因素的影响。
如表6所示,每个组件依次添加以验证它们的作用,SepViT-T简单地配备了DSSA比Swin+CPVT强0.5%,它比755张图像/s的吞吐量快得多。同时,带有CPE、OPE和DSSA的SepViT-T达到了82.0%的top-1准确率。在第二阶段和第三阶段交替使用GSA和DSSA后,准确率提高了0.3%。
进一步研究了用固定的零向量或可学习向量初始化Window Token是否会有影响。与固定的零初始化方案相比,可学习的Window Token帮助SepViT-T将性能提高到82.5%,如表6的最后一行所示。
此外,验证学习的有效性的全局表示每个Window Token Embedding方案,进一步研究其他一些方法的全局表示直接从DWA的输出特性图,如平均池(平均池)和深度卷积(DWConv)。
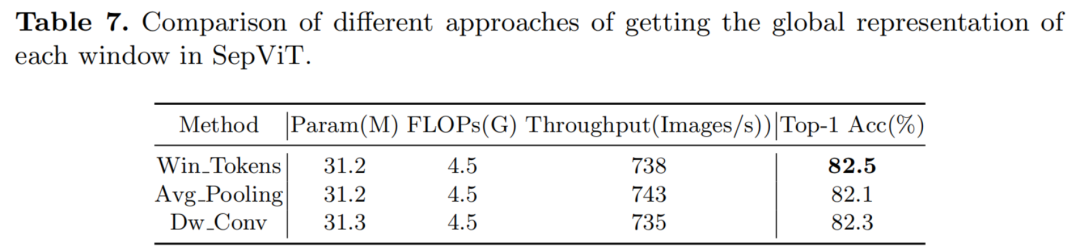
结果如表7所示,Window Token Embedding方案在这些方法中取得了最好的性能。同时,通过对Win token和Avg池化方法的参数和流量的比较,发现Window Token Embedding方案的计算成本可以忽略不计。
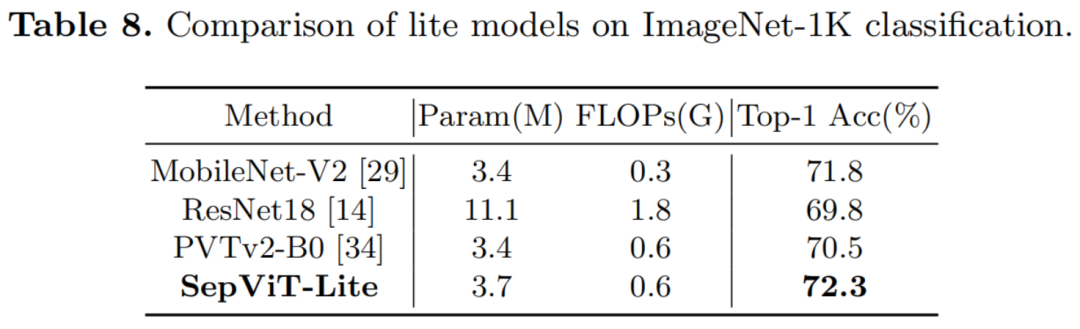
为了进一步探索SepViT的潜力,将SepViT缩小到一个精简版的模型尺寸(SepViT-Lite)。正如在表8中观察到的,SepViT-Lite获得了一个极好的最高精度,为72.3%,优于类似模型尺寸的同类算法。
[1].SepViT: Separable Vision Transformer

