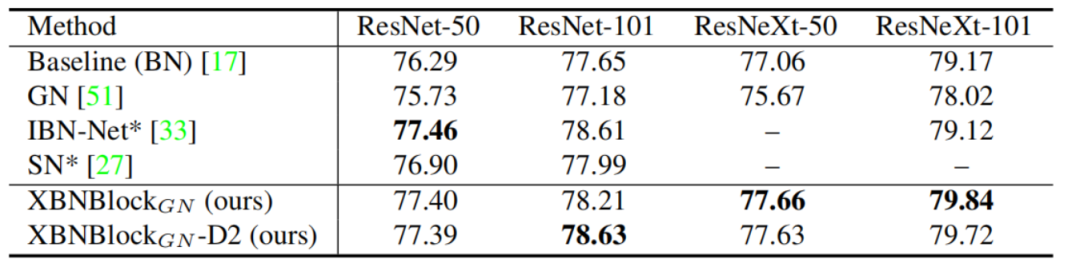
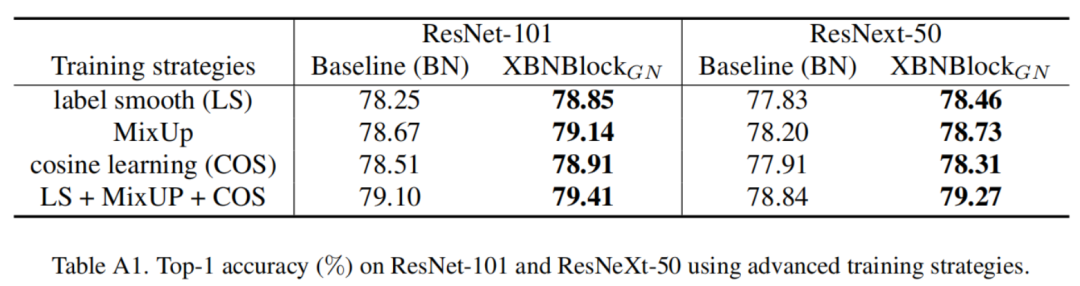
BN是深度学习中的一项里程碑技术。它在训练过程中使用small-batch-size统计来标准化激活的输出,但在推理过程中使用的是总体统计。
本文主要研究统计数据的估计。定义了BN的估计偏移的幅度来定量地测量其估计的统计量和预期的统计量之间的差异。本文的主要观察结果是:由于网络中BN的堆栈作用,估计偏移会被累积,这对测试性能有不利的影响。
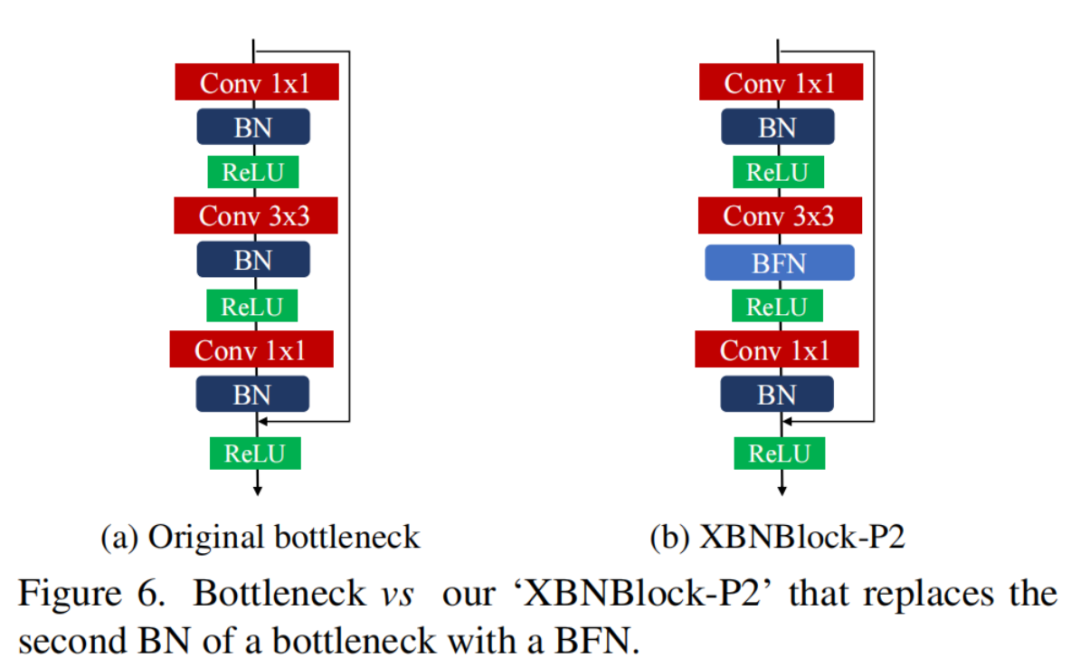
作者进一步发现,batch-free normalization(BFN)可以阻止这种估计偏移的累计。这些观察结果也促使了XBNBlock的设计,该模块可以在残差网络的bottleneck块中用BFN替换一个BN。
在ImageNet和COCO基准测试上的实验表明,XBNBlock持续地提高了不同架构的性能,包括ResNet和ResNeXt,并且似乎对分布式偏移更稳健。
输入标准化在神经网络训练中广泛应用了几十年,在线性模型优化中显示了良好的理论特性。它使用统计数据进行标准化,而这些统计量可以直接从可用的训练数据中计算出来。
一个很自然的想法是扩展网络中激活输出的标准化。然而,由于内部激活的分布不同,标准化激活更具有挑战性,因为激活导致了对标准化的统计量估计不准确。通过总体统计标准化的激活网络显示了训练不稳定性。
BN在训练期间使用mini-Batch统计来对激活输出进行标准化,但在推理/测试期间使用估计的总体统计。BN确保了每次迭代的标准化mini-Batch输出标准化,实现了稳定的训练、高效的优化和潜在的泛化。它已被广泛应用于各种体系结构,并成功地在的不同领域扩散。
尽管BN取得了普遍的成功,但在某些场景时仍然存在问题。BN的限制是它的mini-Batch问题——随着Batch规模变小,BN的误差迅速增加。此外,如果训练数据和测试数据之间存在协变量偏差,则具有朴素BN的网络就会得到显著的退化性能。虽然这些问题在不同的场景和上下文中提出,但用于推理的BN的统计量估计似乎是它们之间的联系:
本文系统地研究了统计量的估计问题。作者引入了BN的预期统计数据,考虑到在训练过程中具有不同分布激活的模糊统计数据。如果BN的估计总体统计量不等于其期望的总体统计量,将其称为估计偏差,并设计实验来定量研究估计偏差如何对批量归一化网络的影响。
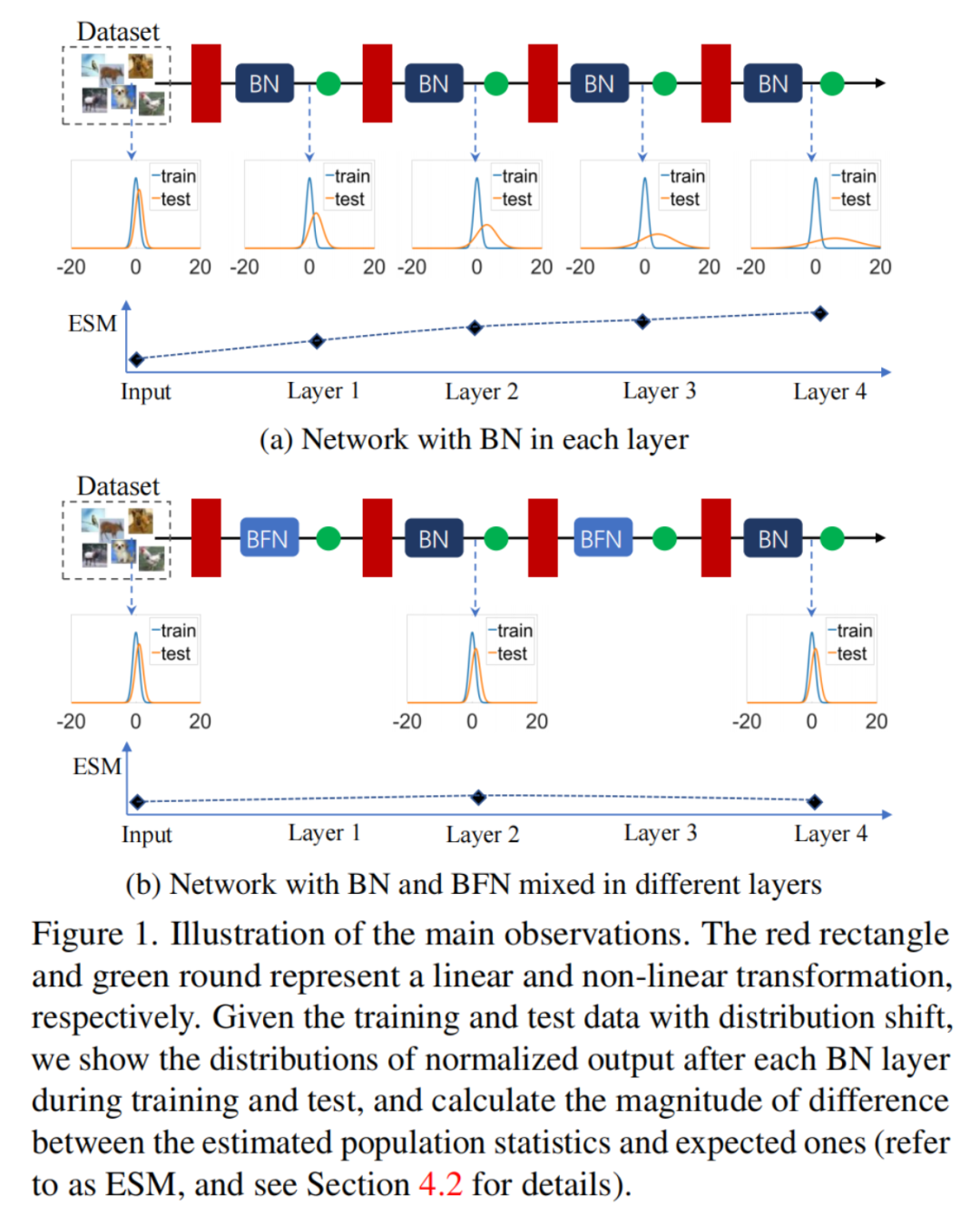
主要观察结果是,BN的估计偏差可以在一个网络中积累(图1(a))。
这一观察结果为解释为什么具有BN的网络在small-batch-size训练下的性能显著退化,以及为什么如果在测试过程中存在输入数据的分布偏移,则需要调整BN的总体统计数据提供了线索。
作者进一步发现BFN对每个样本进行独立归一化,而不需要跨Batch维数,可以阻止BN估计偏差的积累。如果发生了分布偏移,这就缓解了网络的性能退化。
这些观察结果促使了XBNBlock的诞生,可以在残差网络的bottleneck中用BFN取代了一个BN。
作者将所提出的XBNBlock应用于ResNet和ResNeXt体系结构,并在ImageNet和COCO基准测试上进行了实验。XBNBlock持续提高架构的性能。
BN存在小批量的问题,因为统计量的估计可能不准确。为了解决这个问题,很多研究提出了各种BFN,例如,层归一化(LN)和组归一化(GN)。这些工作在训练和推理过程中对每个样本都执行相同的归一化操作。
另一种减少训练和推理之间差异的方法是将估计的总体统计量与小批量统计数据结合起来,在训练期间进行归一化。这些工作可能优于在small-batch-size下训练的BN,其中估计是主要问题,但当批处理大小中等时,它们的性能通常较差。
一些工作只集中在推理过程中估计校正后的归一化统计量,无论是领域自适应、鲁棒性还是小批量训练。这些策略并不影响模型的训练方案。
Li等人提出了域自适应的自适应批归一化(AdaBN),其中在测试过程中对可用目标域的BN统计量的估计进行调制。进一步利用这一思想提高输入数据在协变量偏移下的鲁棒性。
另一种工作通过在推理过程中优化样本权重来纠正小批量训练的归一化统计,寻求总体统计的归一化输出与在训练过程中使用小批量统计观察到的相似。
此外,还考虑了深度生成模型的预测时间batch量设置,并防止测试数据的协变量偏移,其中使用来自测试数据的小批量统计数据进行推断。
与上面显示的工作相比,本文的工作重点是研究网络中BN的估计偏移。设计了将BN和BFN混合的XBN-Block,以阻止BNs估计偏移的积累。
研究人员还通过结合不同的标准化策略来构建一层的标准化模块。
Luo等人提出了可切换归一化(SN),它通过学习不同的Softmax的重要性权重,将引入的稀疏性约束、白化操作等操作进行动态计算。
其他方法解决了特定场景中归一化方法的组合,包括图像风格转移、图像到图像转换、域泛化和元学习场景。
与这些旨在在一个层中构建规范化模块的方法不同,本文提出的XBN-Block是一个混合在不同层中的BN和BFN的构建块。此外,作者观察到,BFN可以阻断网络中BNs估计偏移的积累,这为解释上述方法与其他归一化方法相结合的成功提供了一个新的观点。
本文工作与IBN-Net密切相关,它仔细地将实例规范化(IN)和BN集成为构建块,并可以封装到几个深度网络中,以提高它们的性能。
请注意,IBNNet仔细设计了IN的位置及其通道号,而XBNBlock的设计被简化了。此外,IBN-Net的动机是IN可以学习样式不变特征,从而有利于泛化,而XBNBlock的动机是BFN可以缓解BN的估计偏移,从而避免其在估计不准确时的测试性能退化的问题。
在这里,作者强调了BFN(例如,IN)可以阻止BNs估计偏移的累计,这也为IBN-Net测试性能的成功提供了一个合理的解释,特别是在分布位移的情况下。
设是给定的多层感知器(MLP)的输入。在训练过程中,批归一化将m个小批数据中的每个神经元/通道归一化为:
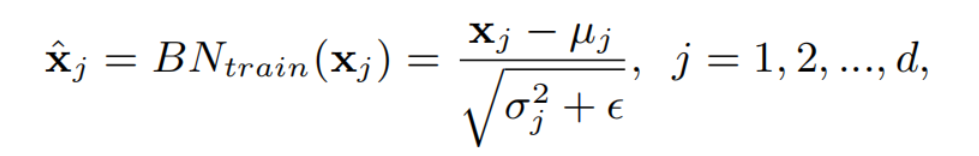
其中,和分别是每个神经元的均值和方差,是一个很小的数字,以防止数值不稳定。
在推理/测试过程中,BN需要层输入的总体均值和方差来进行确定性预测为:
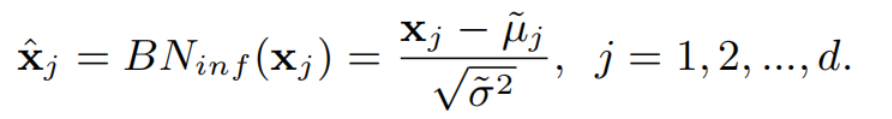
尽管层输入的总体统计量{,˜}是不明确的,它们的估计量{,˜}通常在上式中使用。通过计算更新因子α在不同训练迭代t上的小批统计数据的运行平均值,如下:
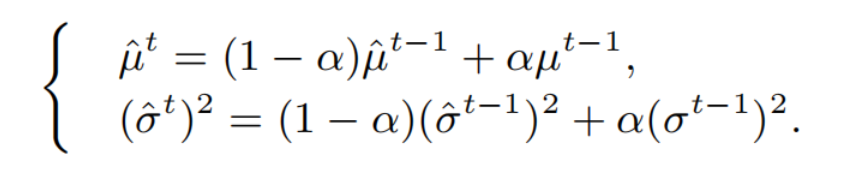
BN在训练和推理过程中的差异限制了其在递归神经网络中的使用,或者有损小批量训练的性能,因为估计可能不准确。
Batch-free normalization避免沿Batch维度归一化,从而避免了统计量估计的问题。这些方法在训练和推理过程中使用了一致的操作。一种代表性的方法是层归一化(LN),它对每个训练样本神经元的层输入进行标准化,如下:
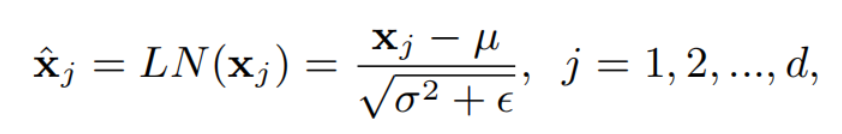
式中,和分别为每个样本的均值和方差。LN通过进一步推广为组归一化(GN),将神经元划分为组,并分别在各组神经元内进行标准化。
通过改变组数,GN比LN更灵活,使其能够在小批量训练(如目标检测和分割)上获得良好的性能。虽然这些BFN方法可以在某些场景中很好地工作,但在大多数情况下,它们无法匹配BN的性能,并且在CNN架构中并不常用。
设S是训练集,是训练过程中采样的小批量数据。考虑一个带有BN的神经网络,这里定义和。
某些训练集S的总体统计量是定义良好的,并且可以利用的小批量统计量直接很好地估计它们。然而,激活的总体统计量是不明确的,因为X在训练过程中由于每次迭代中参数θ的更新而发生变化。
事实上,X的小批样本是,,它不仅依赖于小批输入,还依赖于模型序列。因此,X的期望统计量应该是训练集S和训练过程中变化的模型序列的函数。
尽管很难从统计视图中明确定义X的总体统计量,但注意到子网络的小批输入总是每次迭代的标准化分布。因此,X的期望统计量应该确保在测试集上的标准化输出的标准化。作者隐式地定义了BN的期望统计量如下。

设是训练集S上的训练模型。给定测试集,参考是BN的期望统计量,其中分别是BN的输入的均值(方差)。
注意,期望统计量的定义在训练模型条件输入测试集S的而不是训练集S',因为统计量只考虑最后训练的模型,而不是模型序列。
事实上,一旦模型被训练好,的统计数据就可以很容易地计算出来。然而,它们的泛化性能通常比Eqn3中显示的运行平均性能要差。
给定定义的BN的期望统计量,如果其估计的统计量不等于其期望的统计量,称为BN的估计偏移。
研究BN的估计偏移如何影响批处理归一化网络的性能是很重要的。因此,作者尝试寻求定量地衡量估计的统计量与其预期的统计量之间的差异的大小。
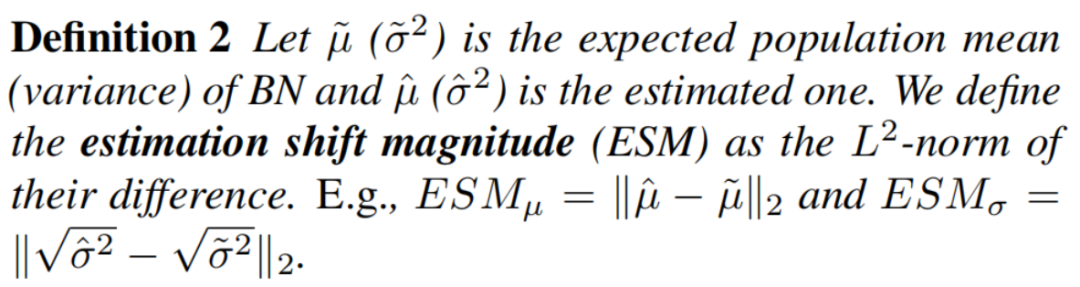
设为BN的期望均值(方差),是估计的BN的期望均值(方差)。将估计偏移幅度(ESM)定义为它们的差值的l2-范数。例如,和。
在接下来的部分中,将设计实验来研究BN的估计偏移如何影响批处理归一化网络的性能,以及如何对其进行修正。
作者考虑了2个实验设置:
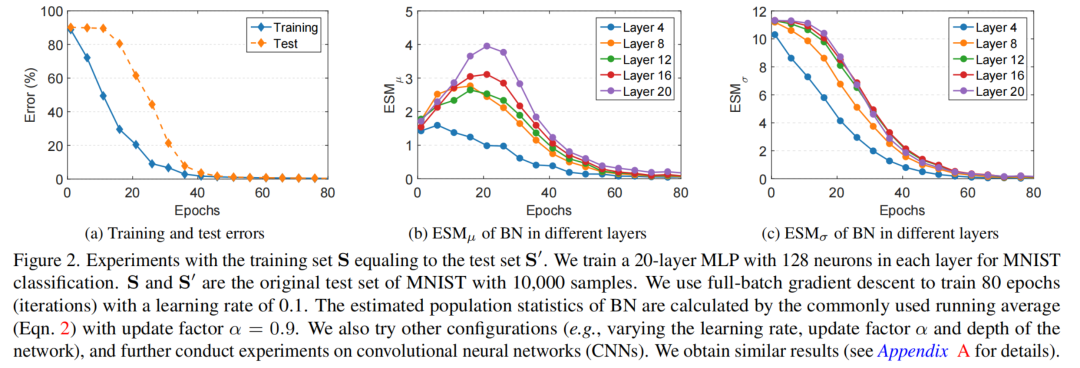
实验配置的细节和结果如图2所示。可以观察到,在前30个Epoch,训练误差和测试误差之间存在显著的差距。
请注意,如果BN在训练和推理过程中采用了相同的操作,那么这个设置中的训练和测试误差应该是相同的。
在图2(b)和(c)中,某些层中BN的和在前30个Epoch显著大于0,然后逐渐收敛到0。这一现象清楚地表明,训练和测试之间的误差差距主要是由于BN的总体统计量估计不准确造成的。
一个重要的观察结果是:较深层BN的和在前30个Epoch可能具有更高的值。这意味着浅层的估计会影响深层的估计。如果浅层的BN发生估计偏移,则深层的BN的估计偏移就会被放大。因此,由于BN层的堆栈,对统计数据的不准确估计可能会被积累放大。
在这个设置中,训练集S从测试集S'中采样,改变训练集|S|的大小来调节训练集和测试集之间的分布位移。希望看到不同的分布变化如何影响在一个网络中对BN的统计量的估计。
实验设置和结果的细节如图3所示。当减少图3(b)中采样训练集的大小时,分布差异可能更大,所有BN层的都显著大于零,而在样本较少的模型中,BN层的更高。
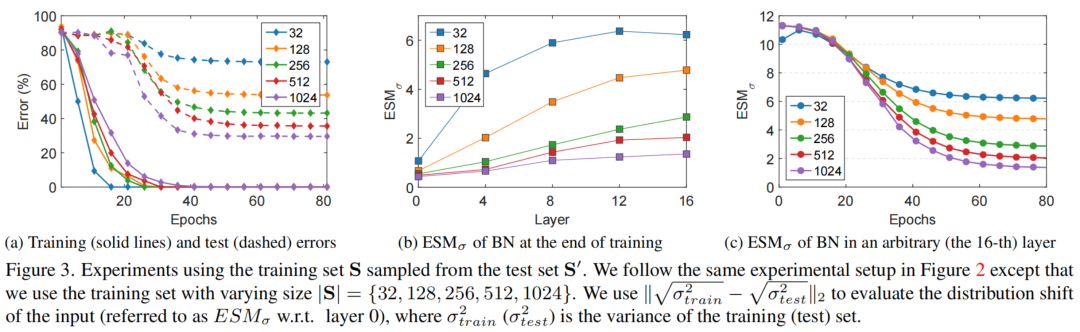
此外,在图3(a)中,可以看到所有的模型都可以用零训练误差进行训练,而如果一个模型在样本较少的训练集上进行训练,测试误差显著更高。这些观察结果表明,训练集和测试集之间的输入分布偏差会导致BN的估计偏差,从而对测试性能产生不利影响。
例如,作者发现不使用BN的模型的检验误差为57.73%,而使用BN模型的检验误差为73.02%。
一个重要的观察结果是,更深层的BN的在训练结束时可能具有更高的价值。这一观察结果显示了显著的证据,支持BN的估计偏移可以由于BN层的叠加而积累。此外,如果训练样本较少,输入数据的分布偏移更强,估计偏移更严重。
在这里,作者强调了定义而不是上的BN的期望统计量是很重要的。作者注意到,在这个实验中,BN的逐渐收敛到一个稳定的值(图3(c)),这表明均值所使用的估计收敛于在训练集上对训练模型的估计。如果在上定义了,则将为零。这不是所期望的,因为它没有提供任何信息来诊断在训练集上训练的模型的退化测试性能,并且在测试集上遭受更大的分布偏移。
综上所述,根据上述实验,作者认为BN的估计偏移可能会在具有BN叠加的网络中累积,这可能会对网络的测试性能产生不利影响,特别是在发生分布不同的情况下。
实验表明,如果在网络中插入一个BFN,则可以一定程度上缓解BN估计偏移的积累问题。作者把奇数层的BN替换为GN,并将这个网络称为“GNBN”。遵循第4.2.1节中所示的前2个实验设置,分别显示图4和图5的结果。

在图4(a)中的前30个Epoch,训练和测试之间的误差差距显著减少,重要的是图4(b)中观察到,在训练过程中,所有层中BN的几乎相同这意味着奇数层中的GN可能会阻碍其相邻2层中BN的估计偏移的积累。
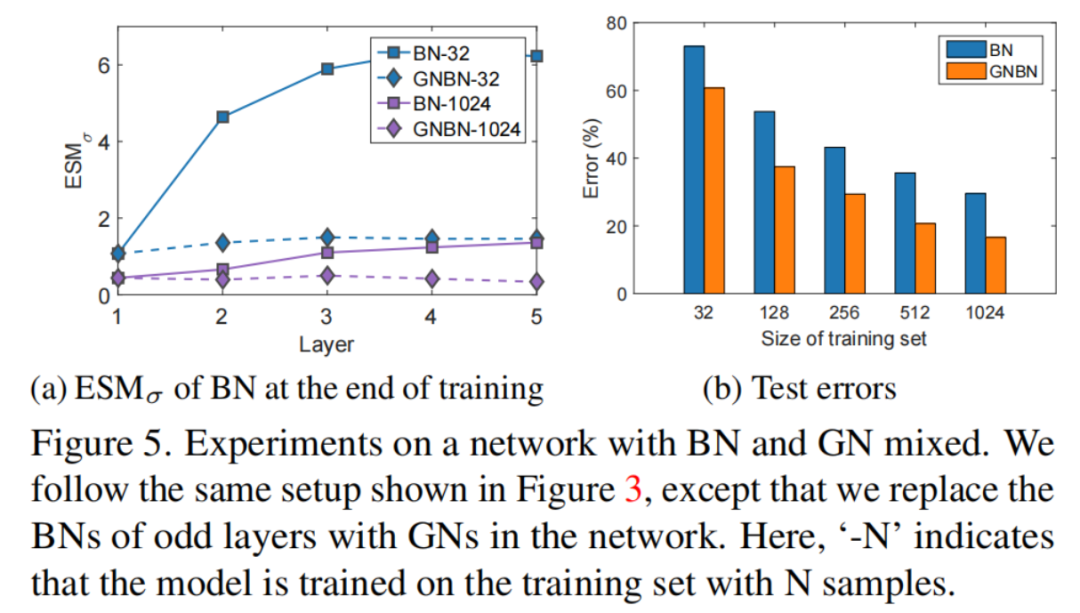
在图5(a)中可以观察到“GNBN”中的BNs的显著低于原始网络(“BN”)。此外,在训练结束时,不同层间BN的没有显著差异。这些观察结果进一步证实了GN可以阻断相邻2层BN的估计位移的积累。
作者将此归因于训练和推理之间(对于每个样本)的GN的一致操作,这确保了后期层的输入具有几乎相同的分布。如图5(b)中的“GNBN”和“BN”的比较所示,估计位移的阻塞积累确保了网络性能的显著提高。
根据以上实验,作者认为BFN(如GN)可以阻断网络中BN估计位移的积累,如果存在分布偏移,也可以缓解网络的性能退化。
def GroupNorm(num_features, num_groups=64, eps=1e-5, affine=True, *args, **kwargs):
if num_groups > num_features:
print('------arrive maxum groub numbers of:', num_features)
num_groups = num_features
return nn.GroupNorm(num_groups, num_features, eps=eps, affine=affine)
class BasicBlock_XBNBlock_P2(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock_XBNBlock_P2, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
# 原始ResNet
#self.bn1 = nn.BatchNorm2d(planes)
# ResNet XBNBlock
self.bn1 = GroupNorm(planes, num_groups=32)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
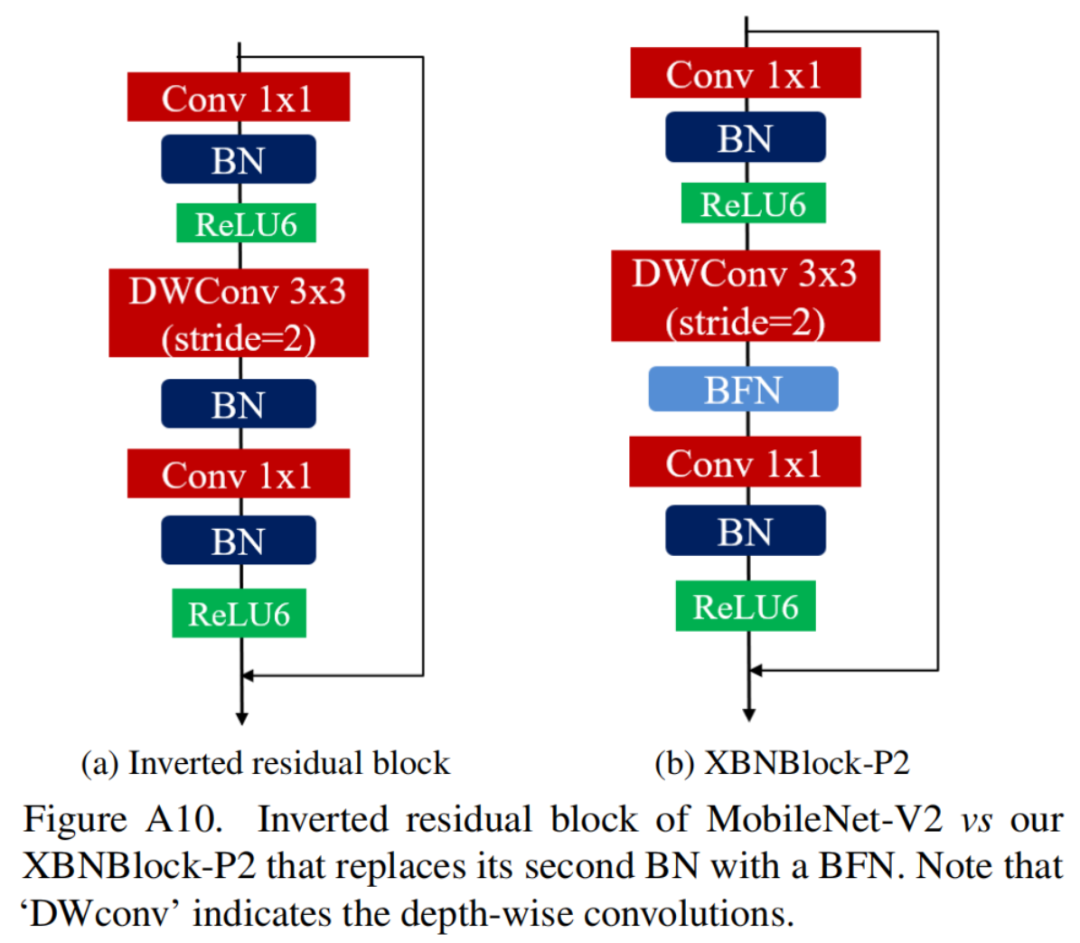
class InvertedResidual_XBNBlock(nn.Module):
def __init__(self, inp, oup, stride, expand_ratio):
super(InvertedResidual_XBNBlock, self).__init__()
self.stride = stride
assert stride in [1, 2]
hidden_dim = int(inp * expand_ratio)
self.use_res_connect = self.stride == 1 and inp == oup
if expand_ratio == 1:
self.conv = nn.Sequential(
# dw
nn.Conv2d(hidden_dim, hidden_dim, 3, stride, 1, groups=hidden_dim, bias=False),
# nn.BatchNorm2d(hidden_dim),
GroupNorm(hidden_dim, num_groups=16),
nn.ReLU6(inplace=True),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
else:
self.conv = nn.Sequential(
# pw
nn.Conv2d(inp, hidden_dim, 1, 1, 0, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.ReLU6(inplace=True),
# dw
nn.Conv2d(hidden_dim, hidden_dim, 3, stride, 1, groups=hidden_dim, bias=False),
# nn.BatchNorm2d(hidden_dim),
GroupNorm(hidden_dim, num_groups=16),
nn.ReLU6(inplace=True),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
if self.use_res_connect:
return x + self.conv(x)
else:
return self.conv(x)
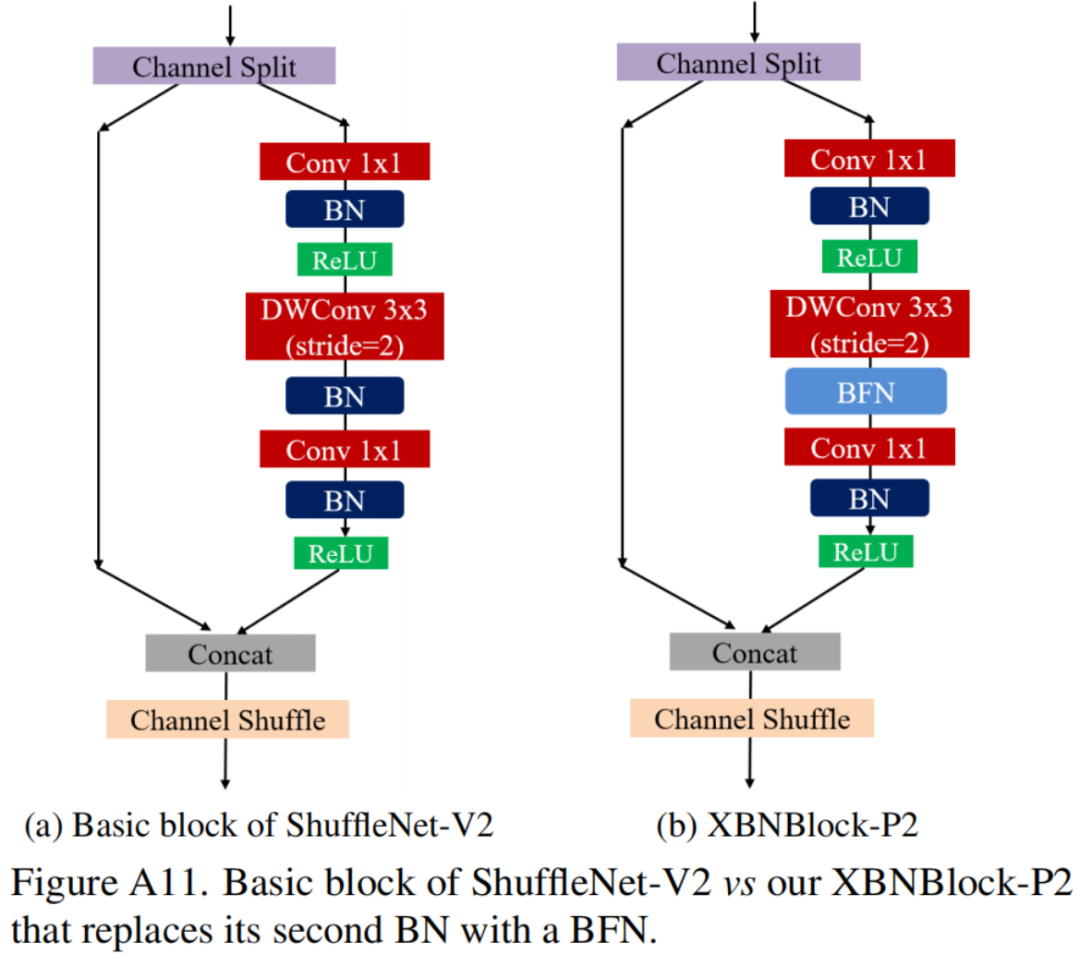
class ShuffleV2XBNBlock(nn.Module):
def __init__(self, inp, oup, mid_channels, *, ksize, stride):
super(ShuffleV2XBNBlock, self).__init__()
self.stride = stride
assert stride in [1, 2]
self.mid_channels = mid_channels
self.ksize = ksize
pad = ksize // 2
self.pad = pad
self.inp = inp
outputs = oup - inp
branch_main = [
# pw
nn.Conv2d(inp, mid_channels, 1, 1, 0, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
# dw
nn.Conv2d(mid_channels, mid_channels, ksize, stride, pad, groups=mid_channels, bias=False),
#nn.BatchNorm2d(mid_channels),
GroupNorm(mid_channels, num_groups=8),
# pw-linear
nn.Conv2d(mid_channels, outputs, 1, 1, 0, bias=False),
nn.BatchNorm2d(outputs),
nn.ReLU(inplace=True),
]
self.branch_main = nn.Sequential(*branch_main)
if stride == 2:
branch_proj = [
# dw
nn.Conv2d(inp, inp, ksize, stride, pad, groups=inp, bias=False),
#nn.BatchNorm2d(inp),
GroupNorm(inp, num_groups=8),
# pw-linear
nn.Conv2d(inp, inp, 1, 1, 0, bias=False),
nn.BatchNorm2d(inp),
nn.ReLU(inplace=True),
]
self.branch_proj = nn.Sequential(*branch_proj)
else:
self.branch_proj = None
def forward(self, old_x):
if self.stride==1:
x_proj, x = self.channel_shuffle(old_x)
return torch.cat((x_proj, self.branch_main(x)), 1)
elif self.stride==2:
x_proj = old_x
x = old_x
return torch.cat((self.branch_proj(x_proj), self.branch_main(x)), 1)
def channel_shuffle(self, x):
batchsize, num_channels, height, width = x.data.size()
assert (num_channels % 4 == 0)
x = x.reshape(batchsize * num_channels // 2, 2, height * width)
x = x.permute(1, 0, 2)
x = x.reshape(2, -1, num_channels // 2, height, width)
return x[0], x[1]