


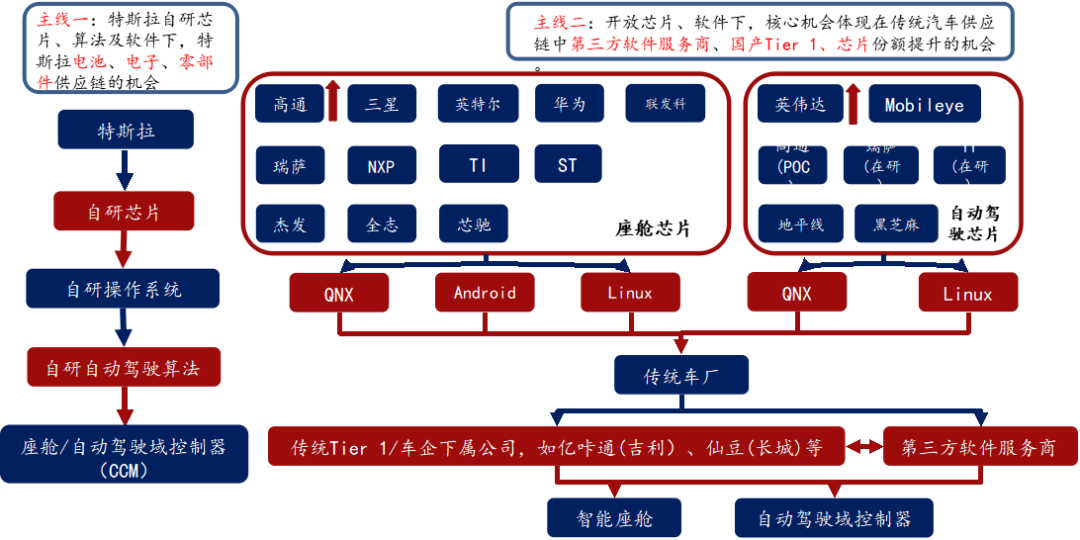
L3 +:英伟达 > 高通 > 华为
L3 以下:Mobileye 市占率最高,但黑盒子交付模式越来越不受车厂喜欢,未来开放模式将更受大家欢迎;地平线、黑芝麻等国产厂商有机会。
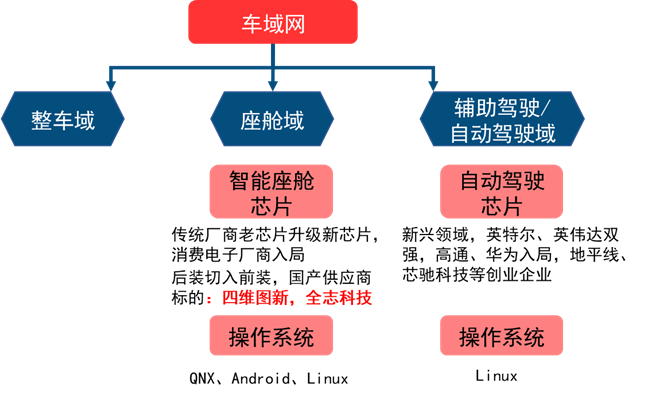
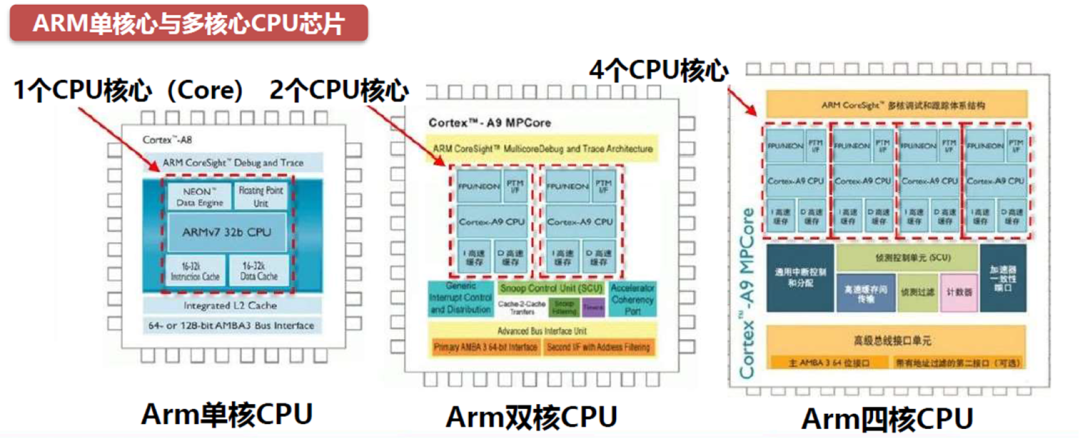

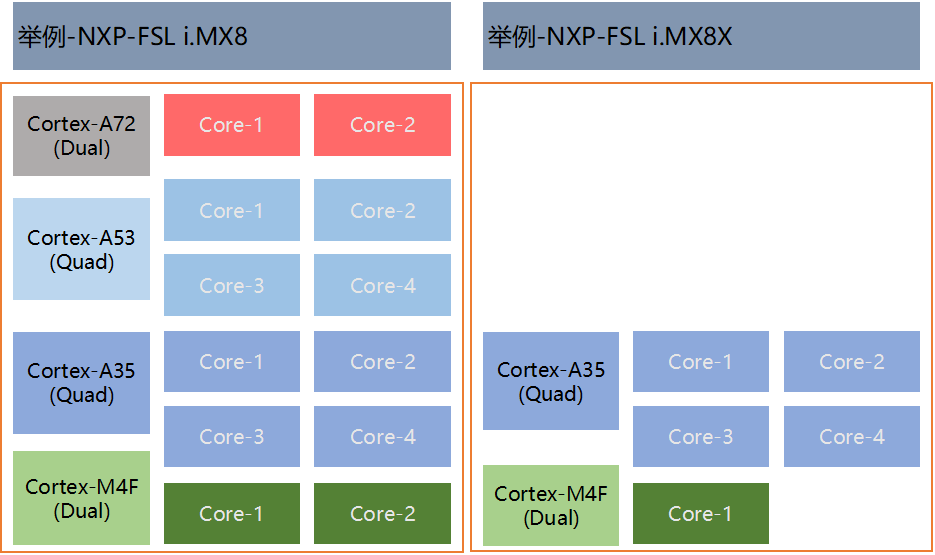
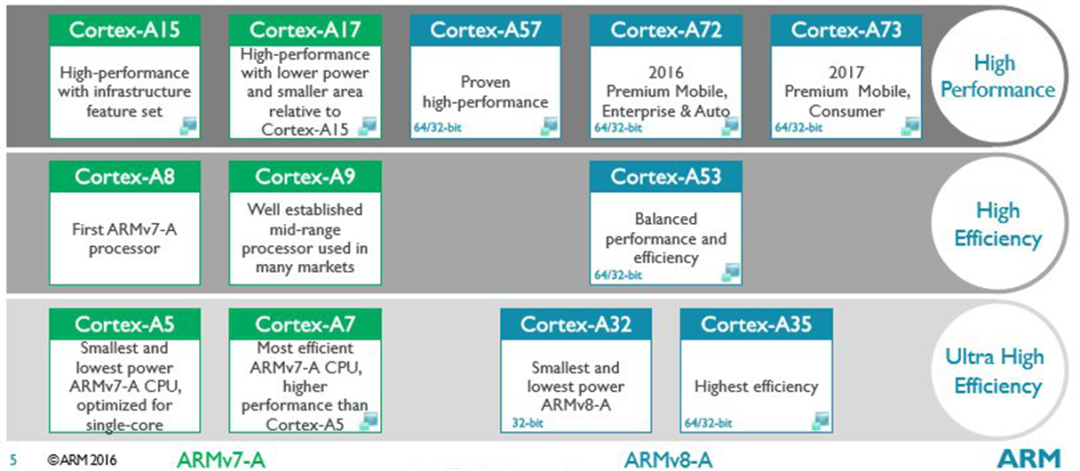

传统汽车芯片厂商,主打中低端市场:NXP、德州仪器、瑞萨电子等;
手机领域的厂商,主打高端市场:联发科、三星、高通等。
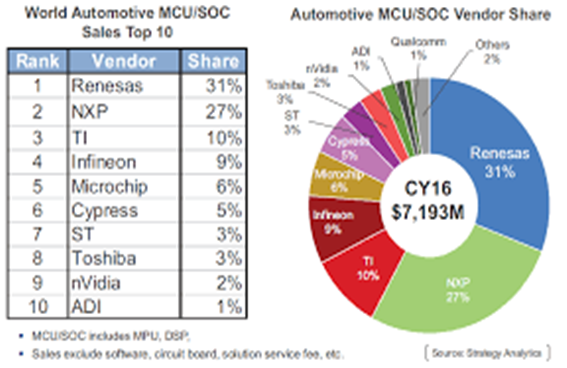
2015 年前:以瑞萨、NXP、TI 等传统汽车芯片主导市场,这三家占据市场 60% 的份额。
2015 年开始:越来越多的消费级芯片巨头参与汽车片芯片生产商重组并购。

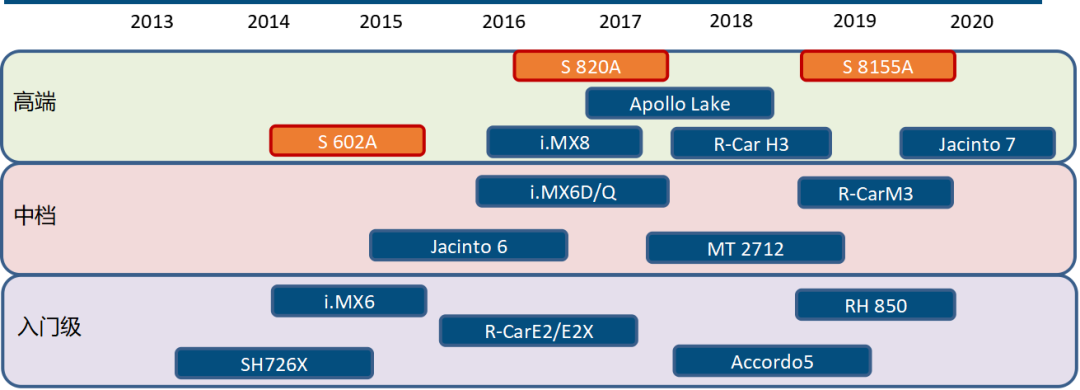
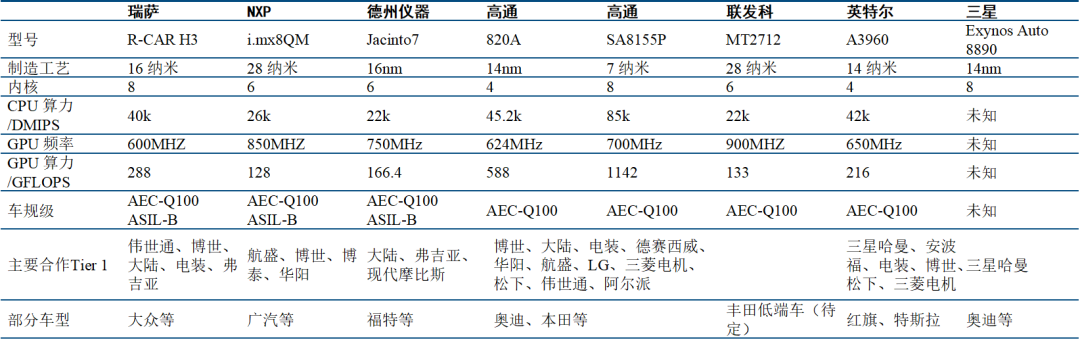
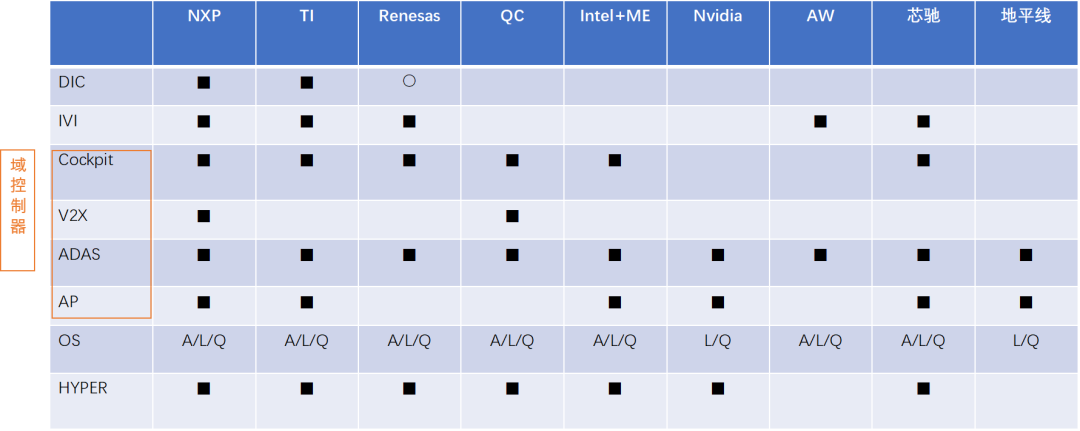
智能座舱芯片:高端以高通、英特尔、瑞萨为主(还要看其第四代产品竞争力),高通领先。
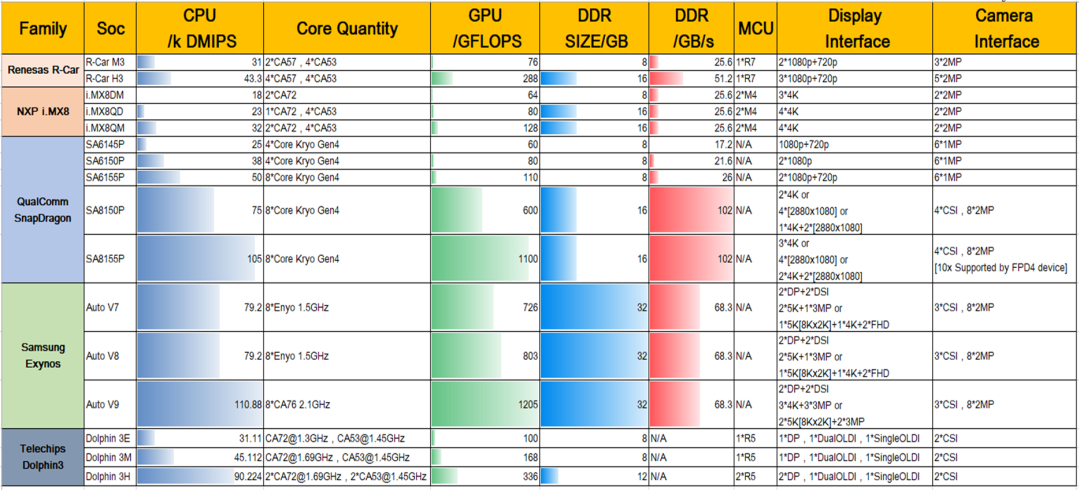
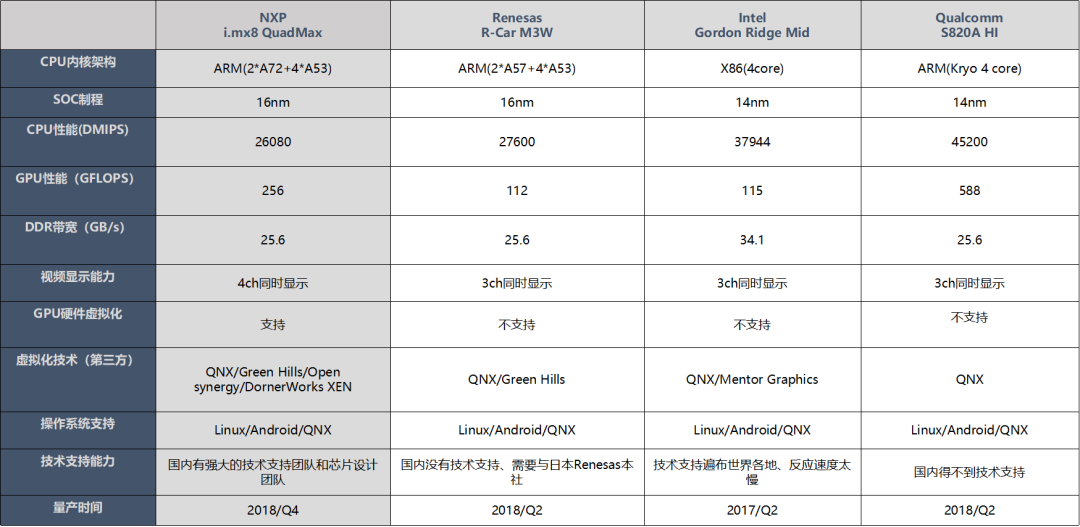
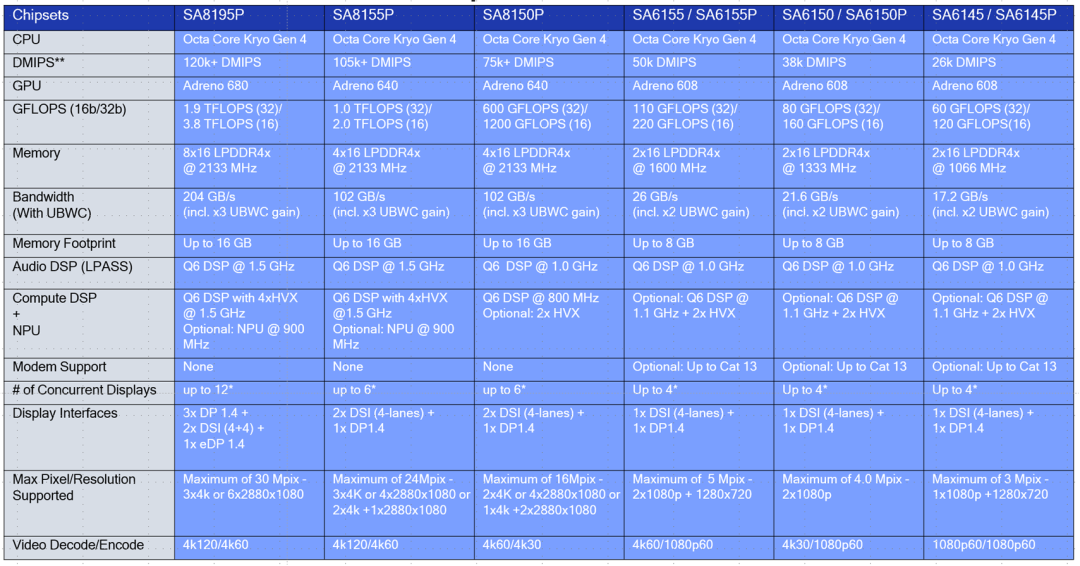
CPU 性能对比:高通 820A CPU 性能与英特尔、瑞萨基本一致。但 8155 具备全方面的性能优势,8.5 万 DMIPS 同代产品领先。
GPU 性能:目前浮点性能上,高通相比于瑞萨、英特尔领先较多,比如 820A的GPU性能为588 GFLOPS,而英特尔为 216 GFLOPS,瑞萨为115.2 GFLOPS。
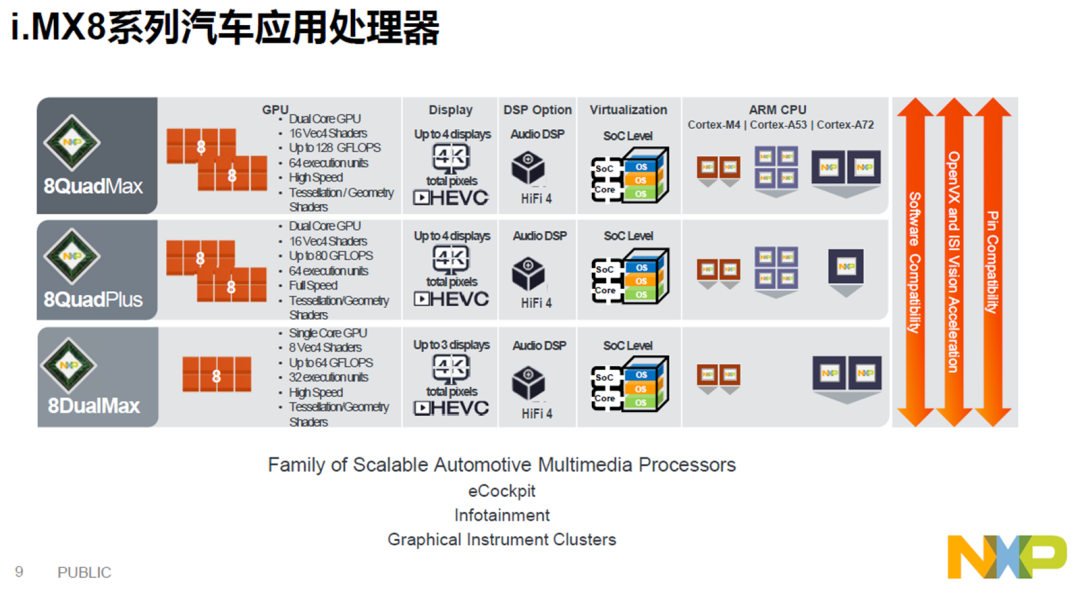
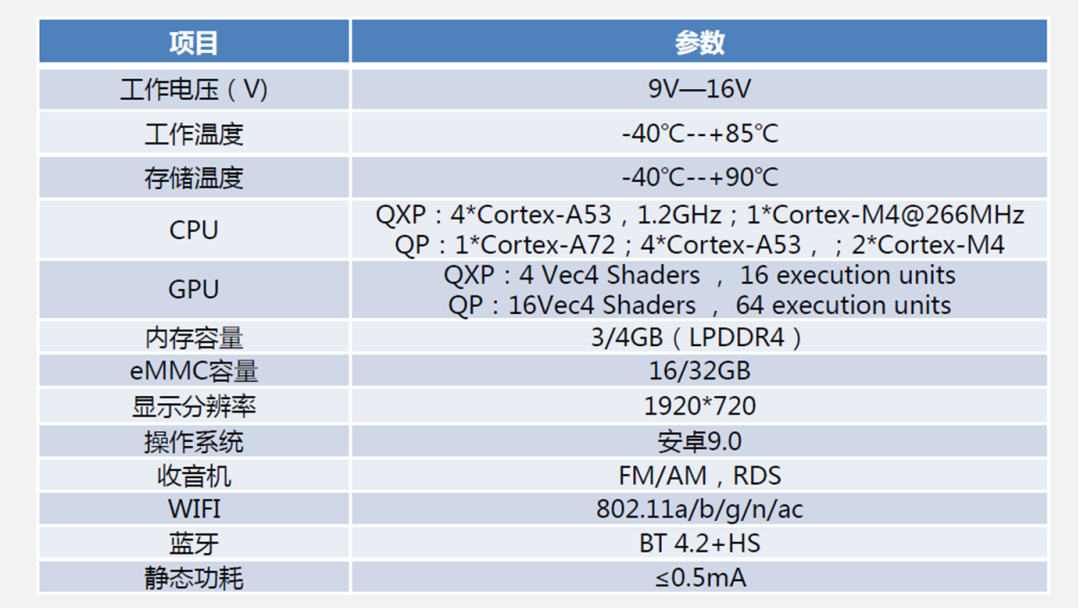
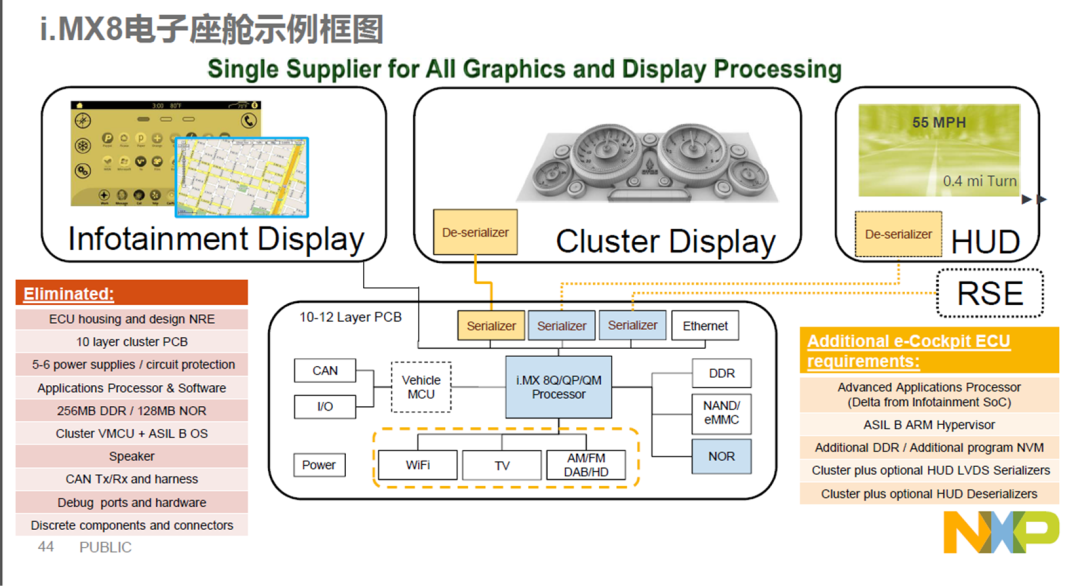
中低端玩家:恩智浦(i.MX6/i.MX8)、德州仪器(Jacinto 6/ Jacinto 8)
低端产品:意法半导体(A5/A6)
待进入玩家:华为、三星、联发科。

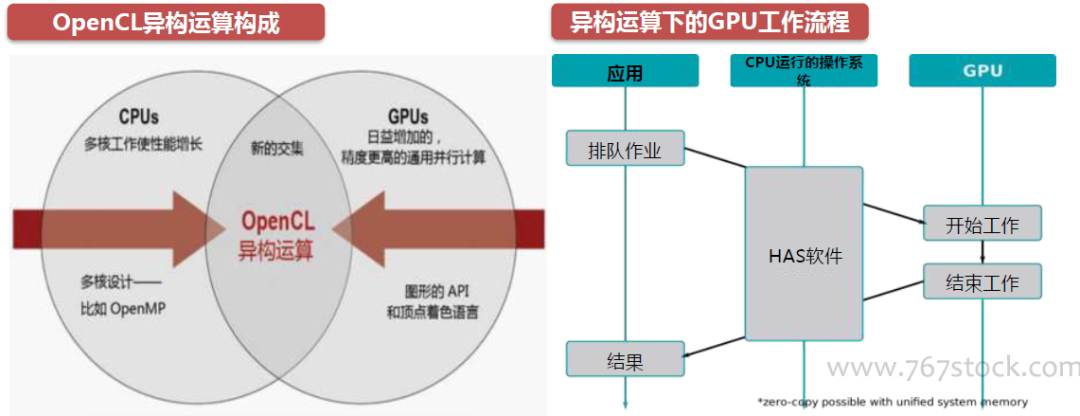
DMIPS:主要用于测整数计算能力;
MFLOPS:主要用于测浮点计算能力。
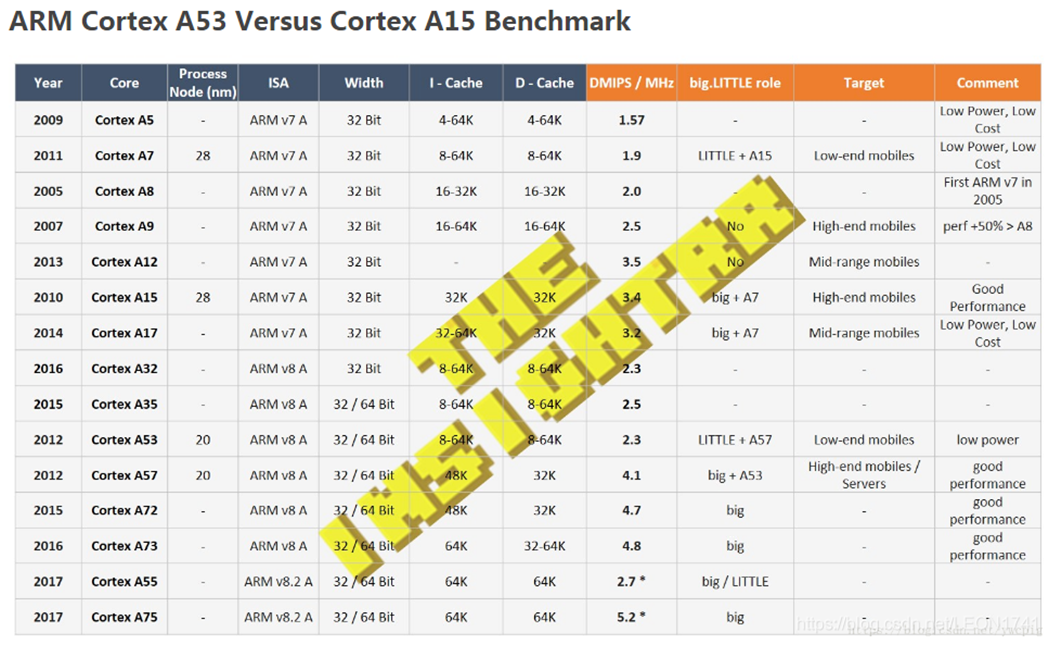


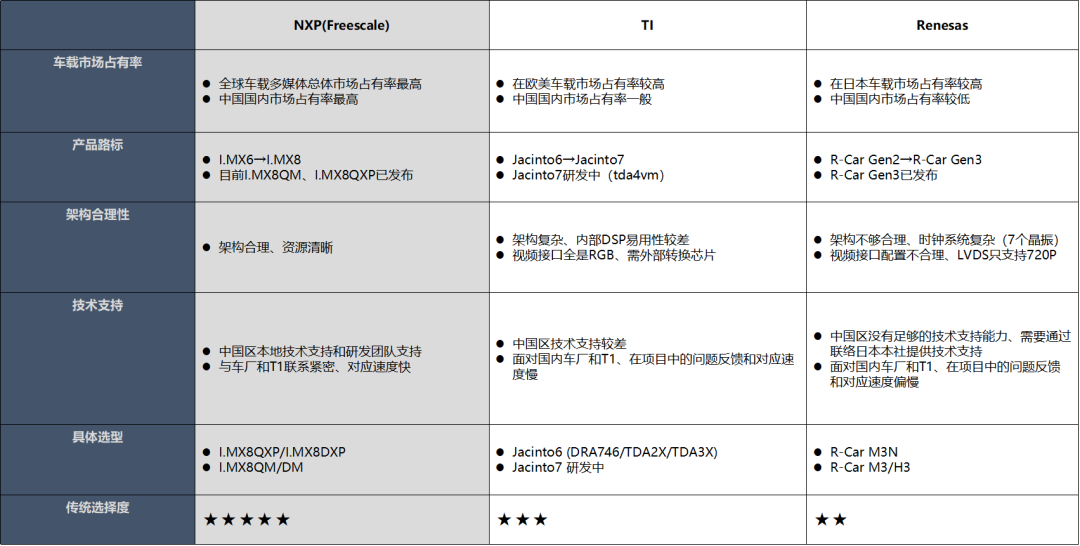
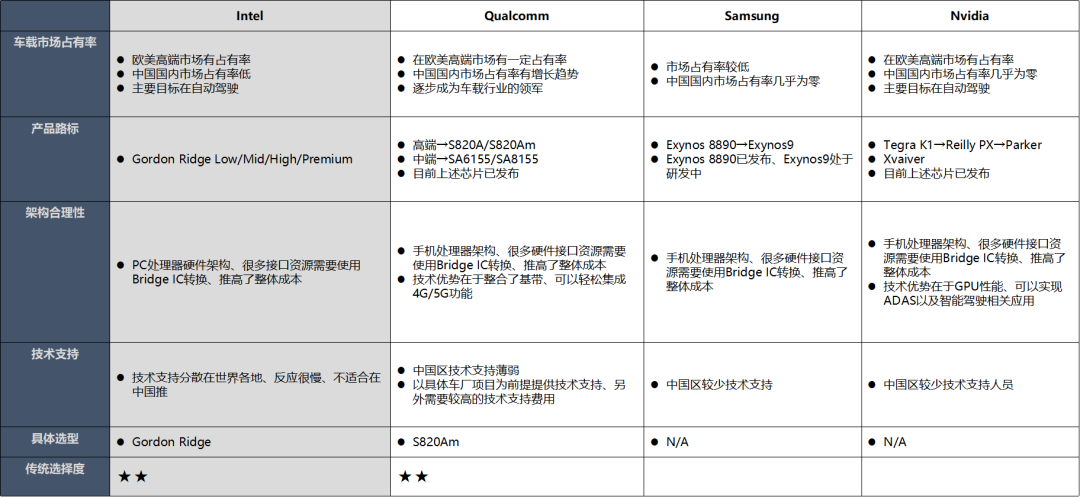
车载市场占有率 这个占有率越高,整体后面的成本才具有优势,同时采购周期或者调货的时候也比较方便,当然大家都用,就需要考虑到后面的技术支持的力度,从目前来看高通芯片的占有率非常高,其次是 NXP 和瑞萨。
还需要考虑芯片架构的合理性,特别是很多芯片公司都是手机处理器的架构,手机处理器架构、很多硬件接口资源需要使用 Bridge IC 转换、推高了整体成本,有的只有 RGB 接口,而一般车载显示屏都是 LVDS 接口,需要增加视频转换芯片,高通芯片比较好的地方是融合了基带信号,这个可以节省很大比射频芯片的成本,只需要外围增加射频天线即可。
产品路标和技术支持也是需要考虑的一个维度,比如瑞萨在国内的技术支持力度就不大,中国区没有足够的技术支持能力、需要通过联络日本本社提供技术支持面对国内车厂和 T1、在项目中的问题反馈和对应速度偏慢。而且需要看该产品路线后续的芯片规划,有的可能规划了这两代后,后面基本上就放弃了智能座舱的芯片了,比如 TI 芯片。

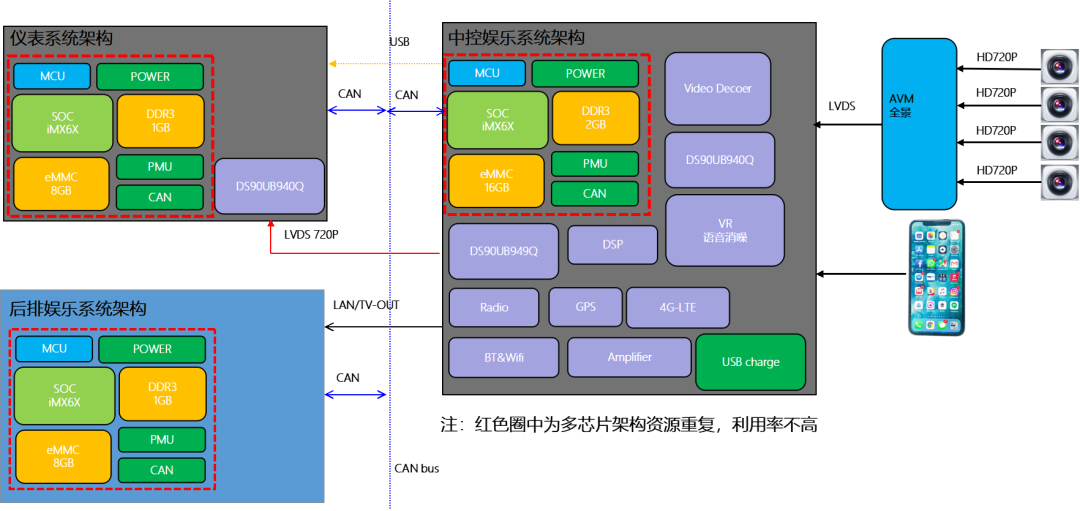
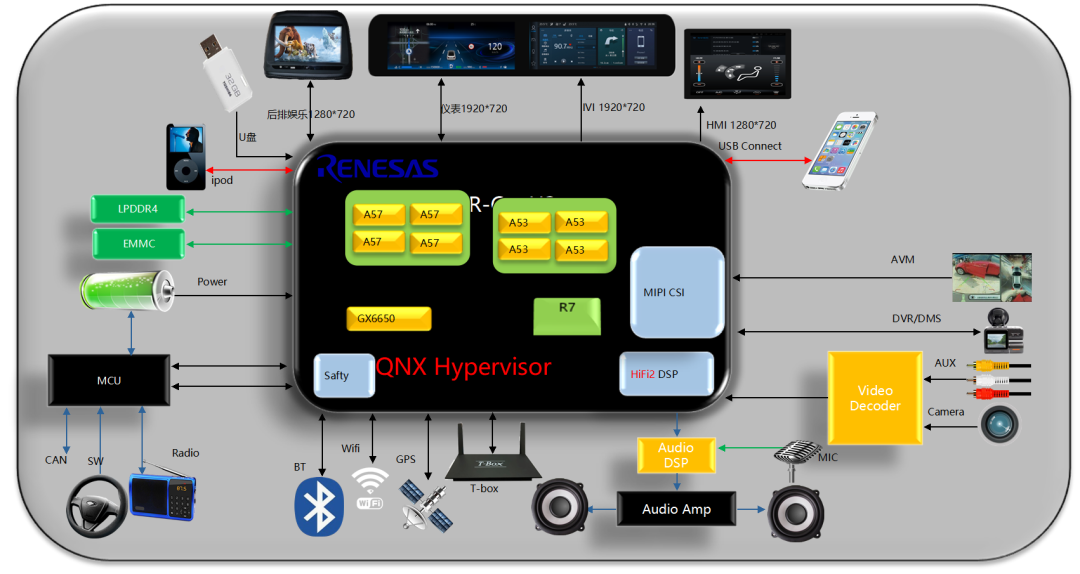
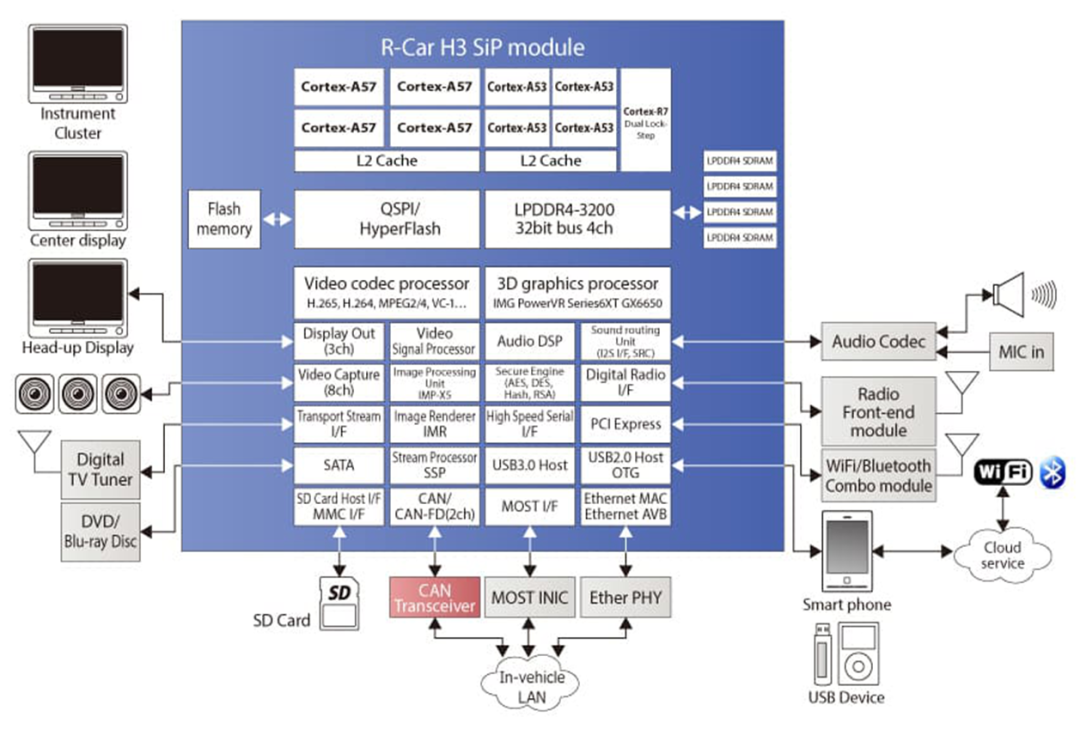
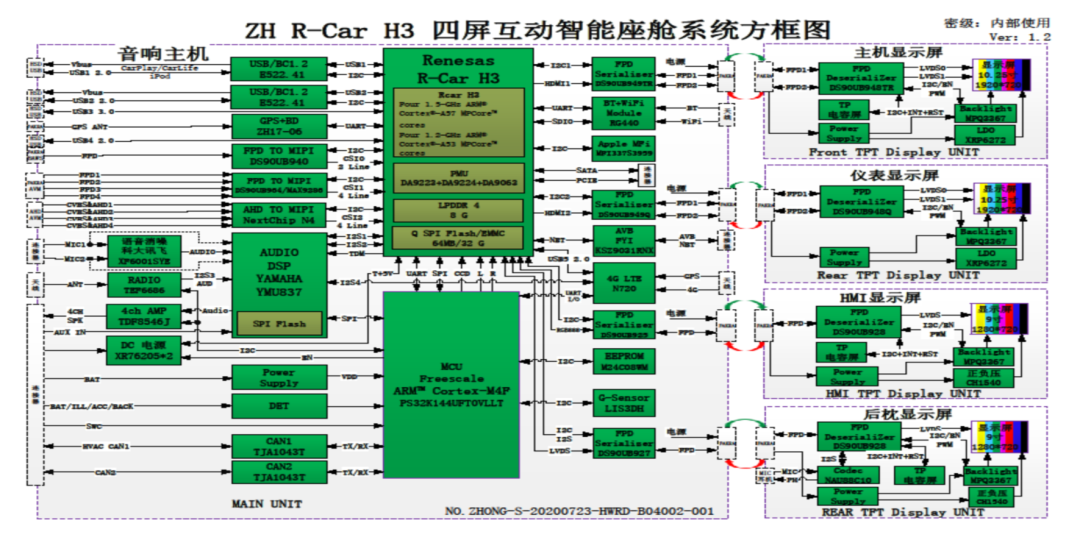

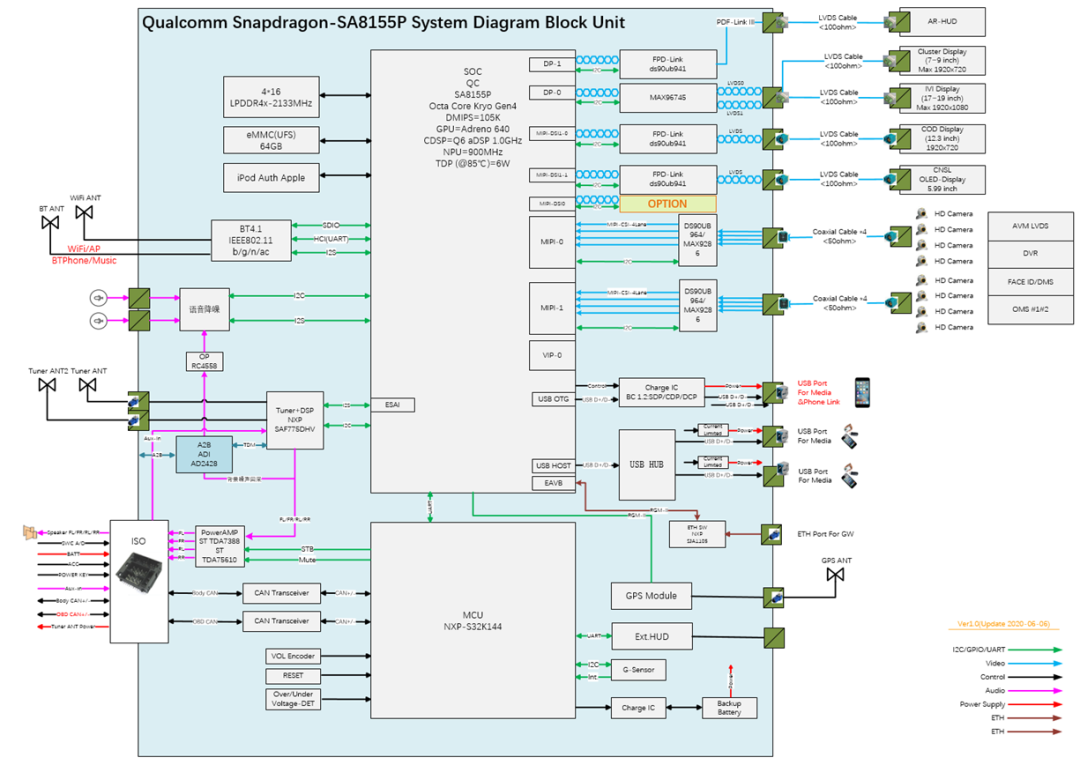
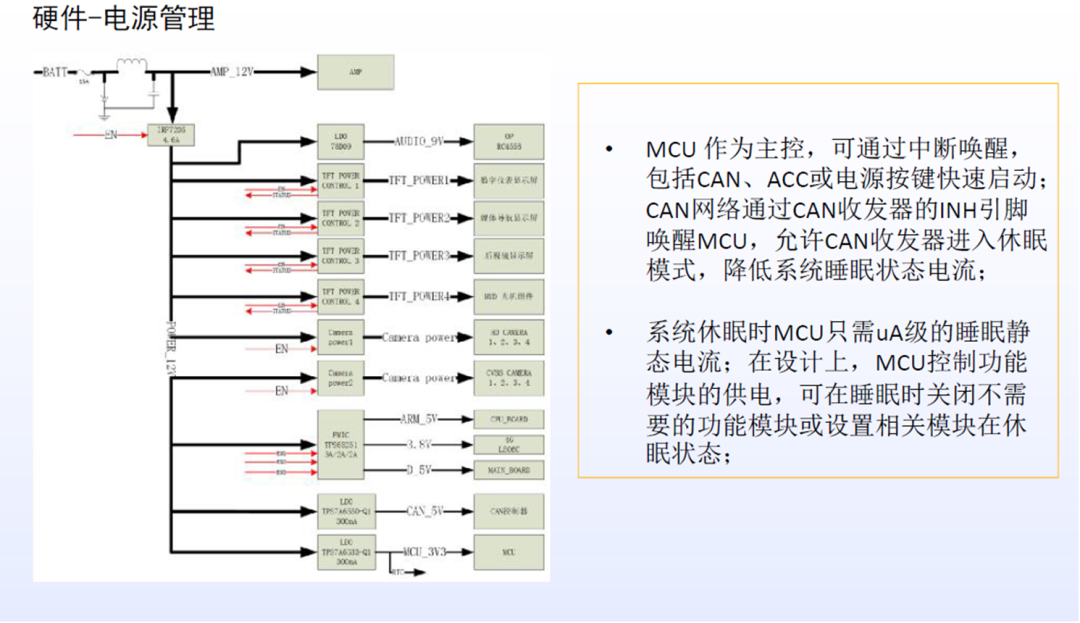
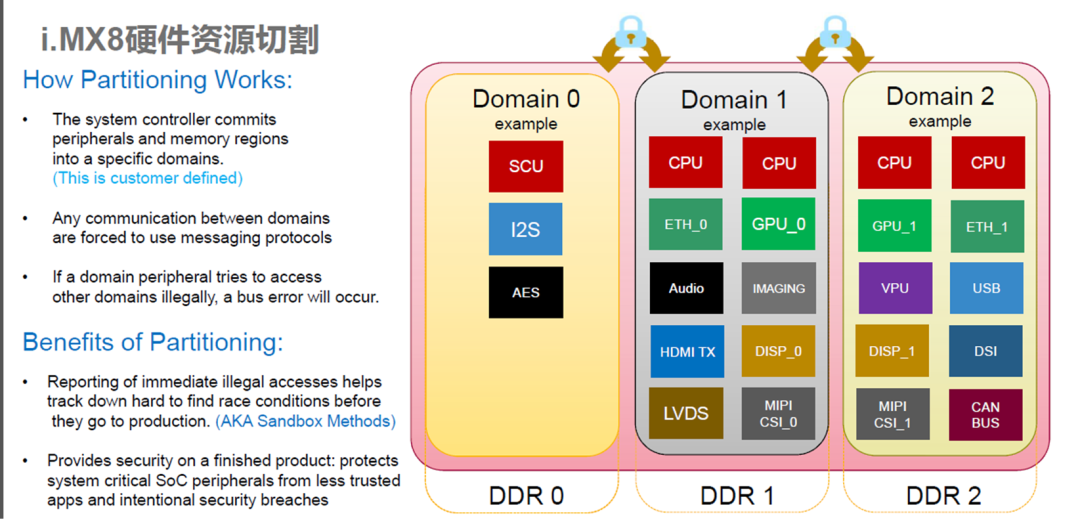
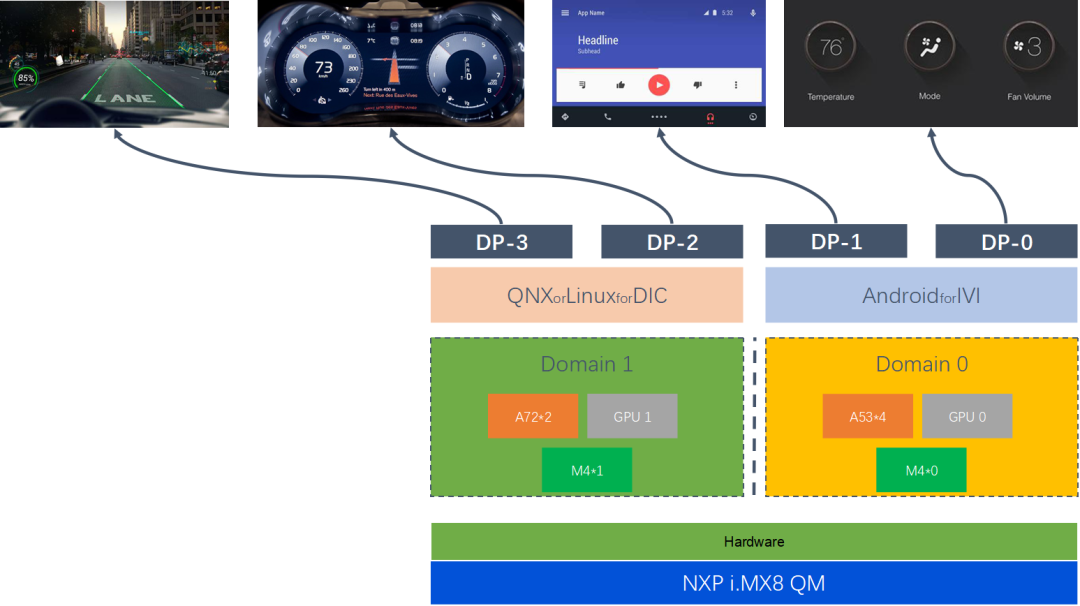
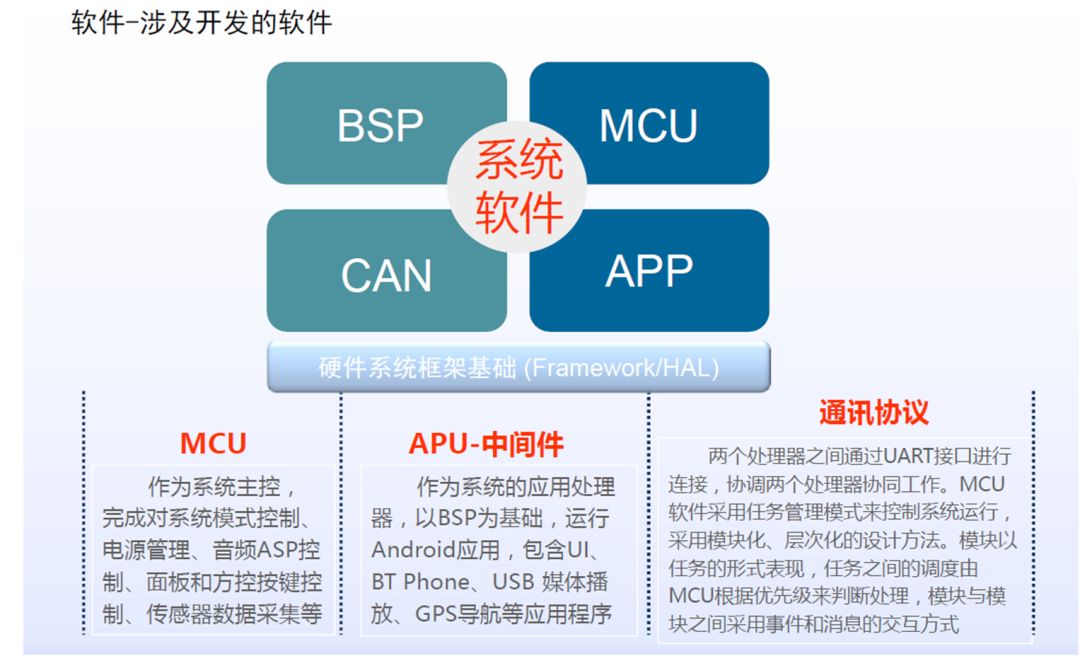
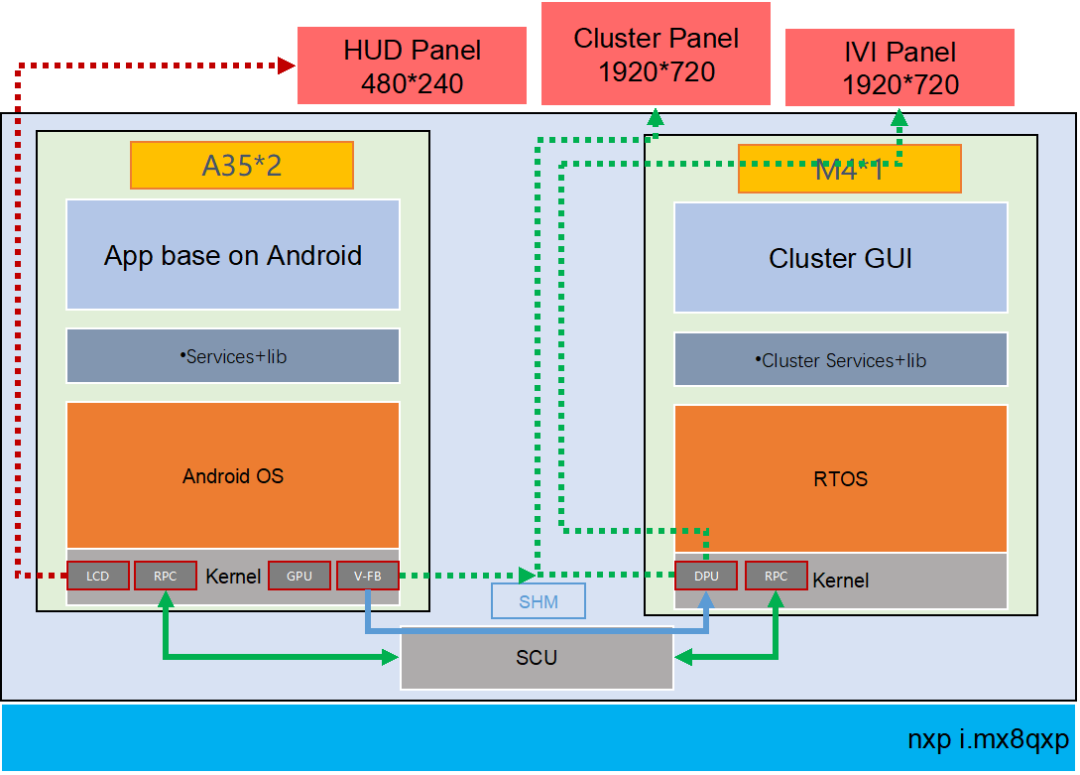
MCU 运行 AUTOSAR 系统,用于 CAN/LIN 唤醒/通讯/电源管理等。
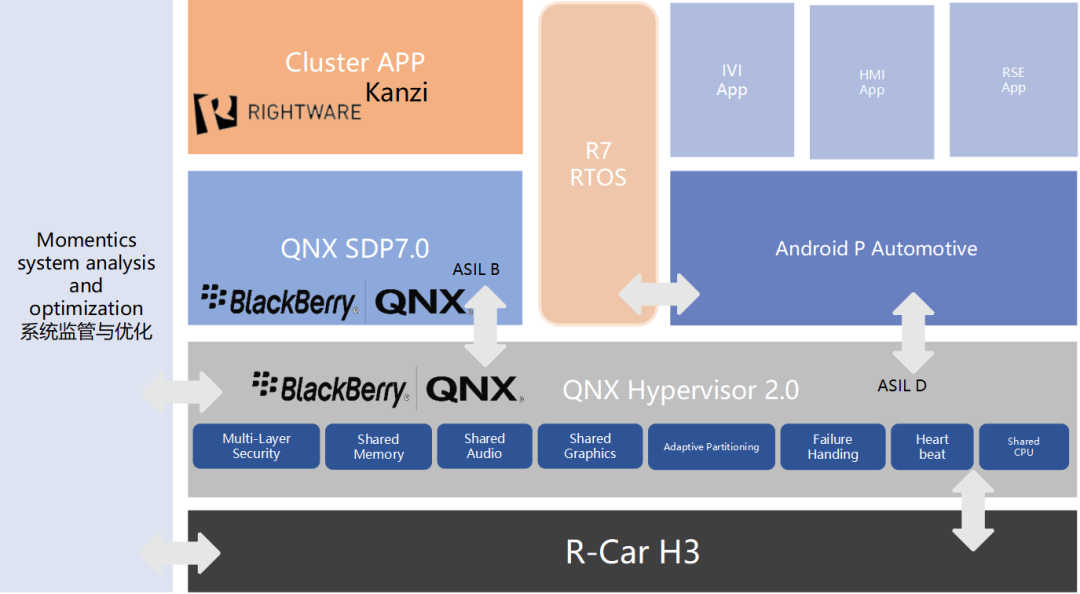
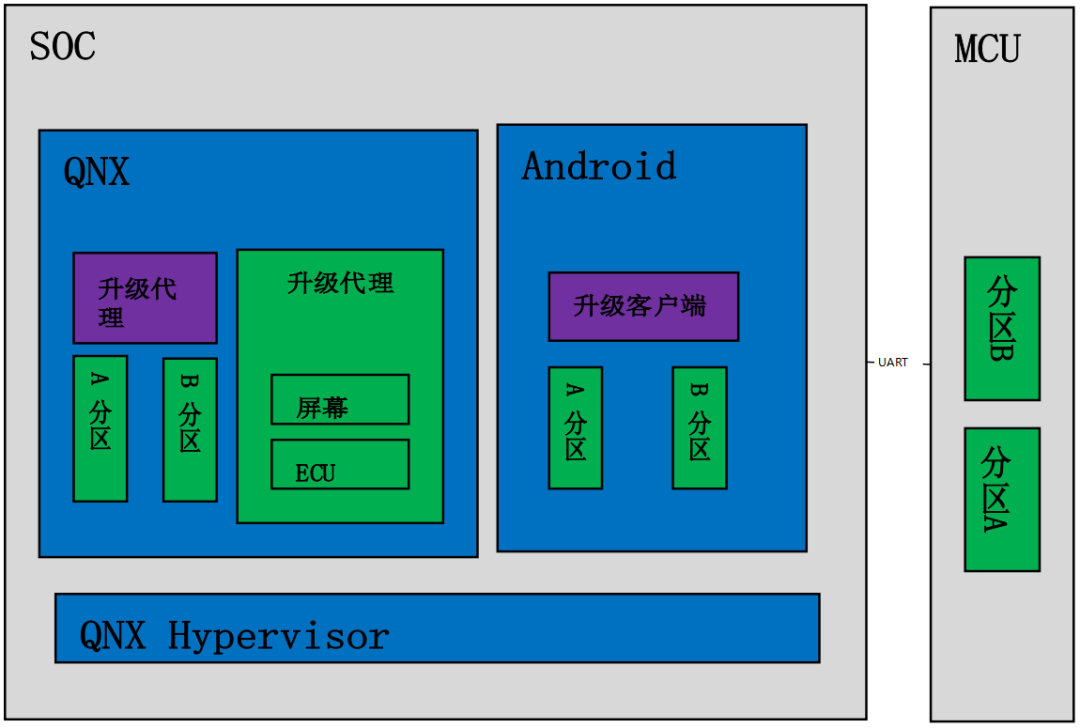
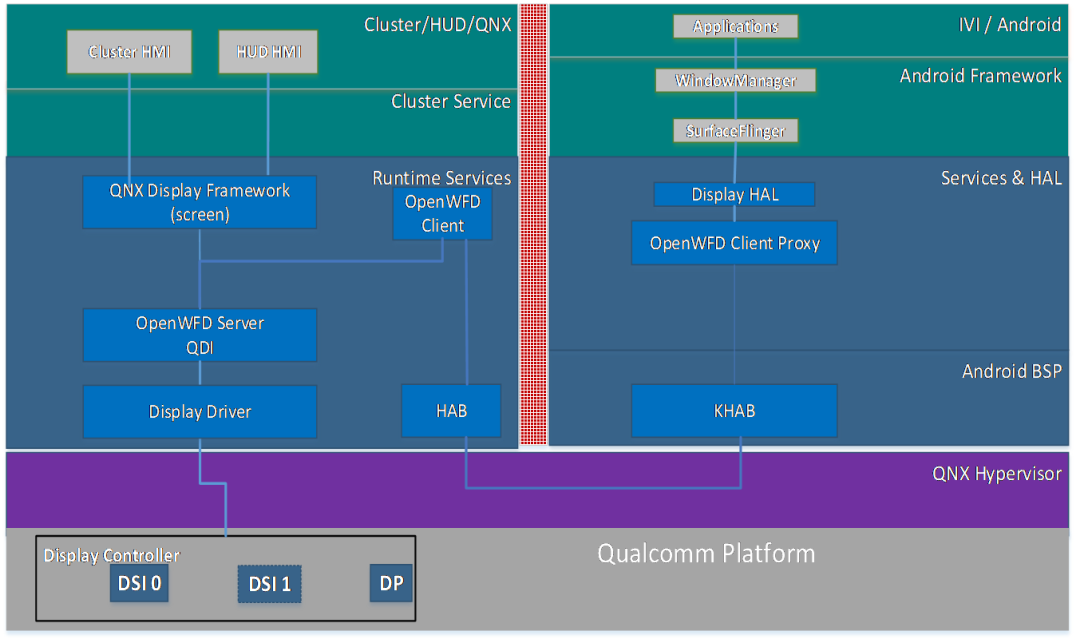
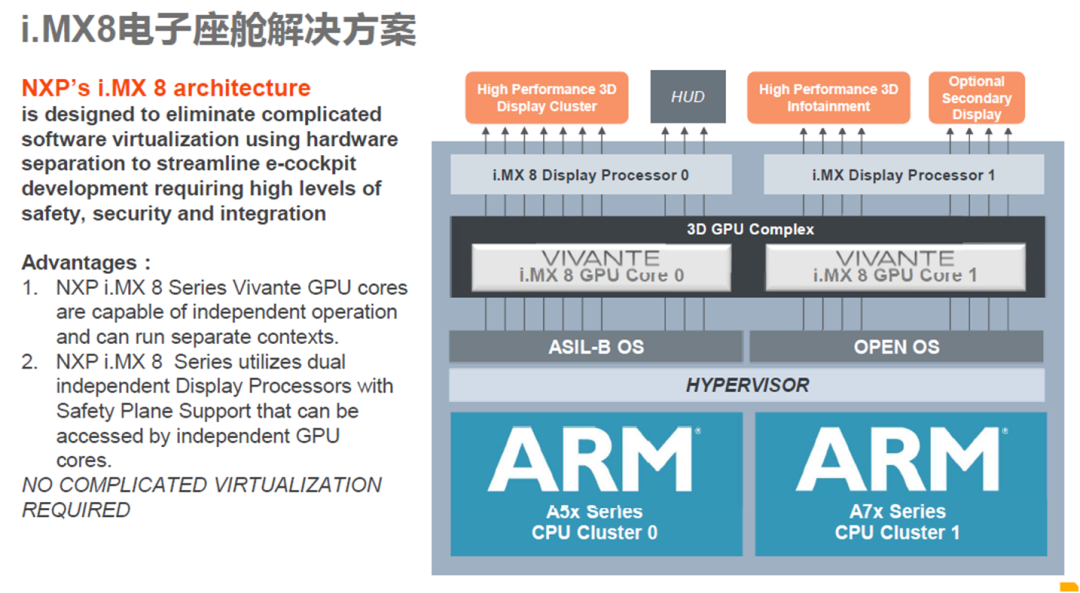
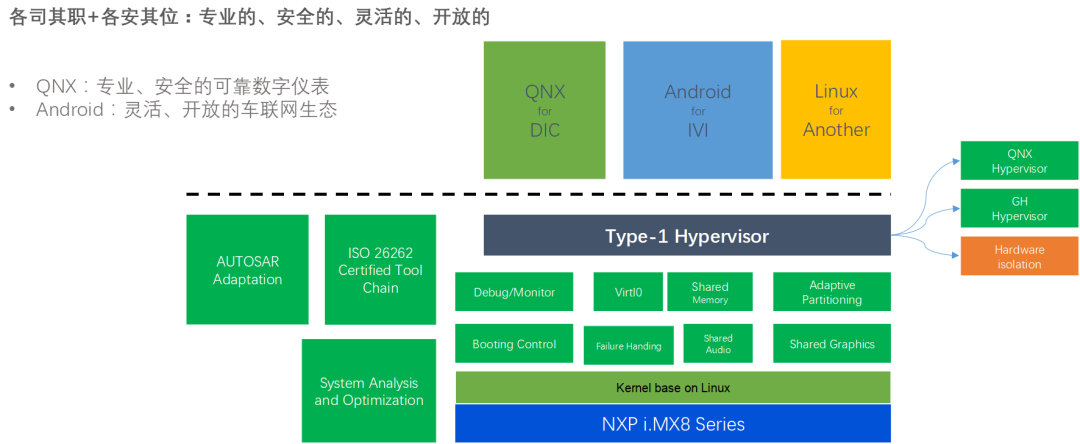
SoC 运行 QNX Hypervisor,包含两个操作系统,其中 QNX 运行对实时性和安全性要求高的功能,比如仪表/HUD。
Android 系统运行娱乐域相关的功能,比如导航/音乐等应用。
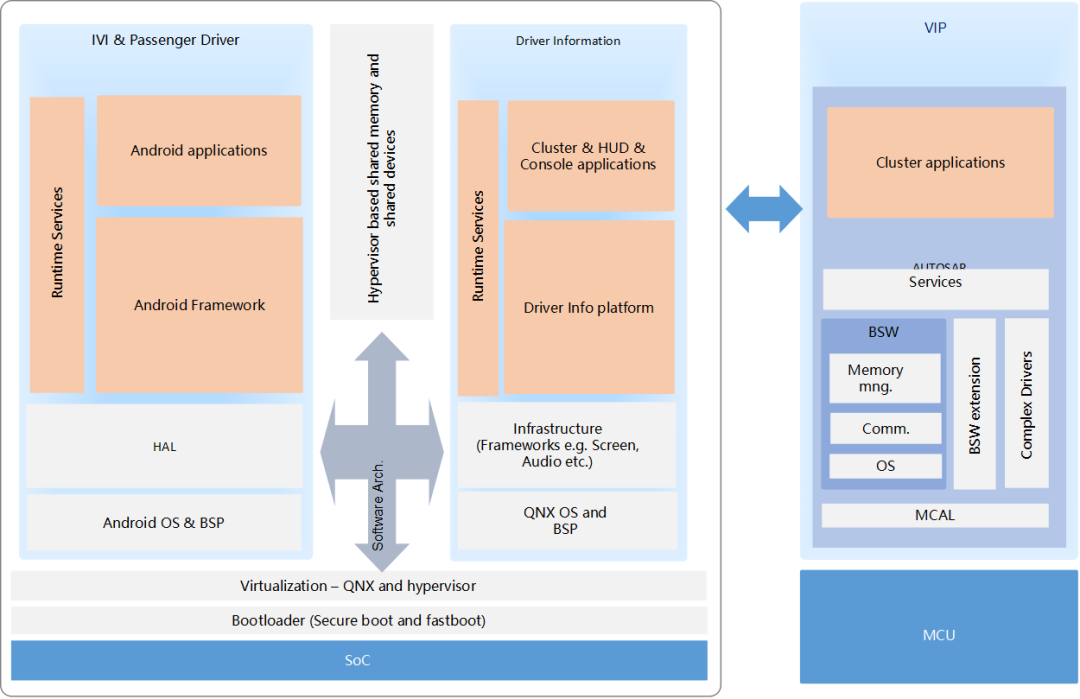
运行 Guest OS 系统,可以在虚拟机上运行 Android 系统。
QNX 系统达到 ASIL-D 等级,同时具备高实时性,可以运行仪表/HUD 等功能。
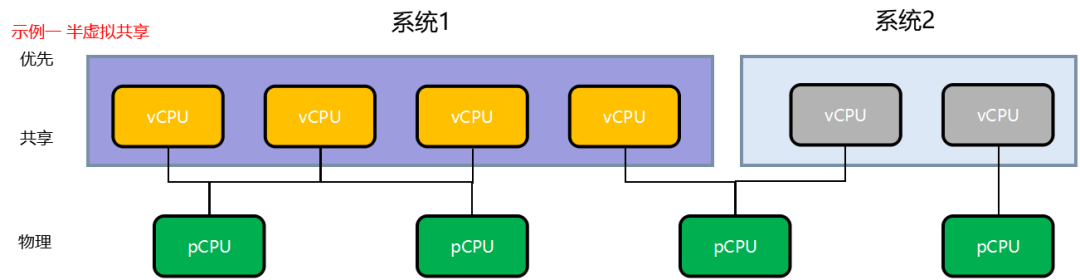
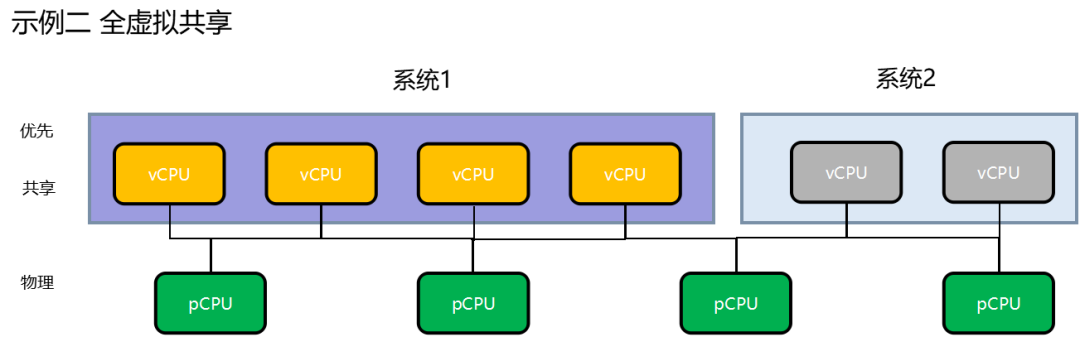
GPU 以及 CPU 的资源可以共享,可以通过配置优先级确保 QNX 系统的资源。
支持 Qualcomm 平台/Renesas 平台/Intel 以及其他座舱域控硬件平台。
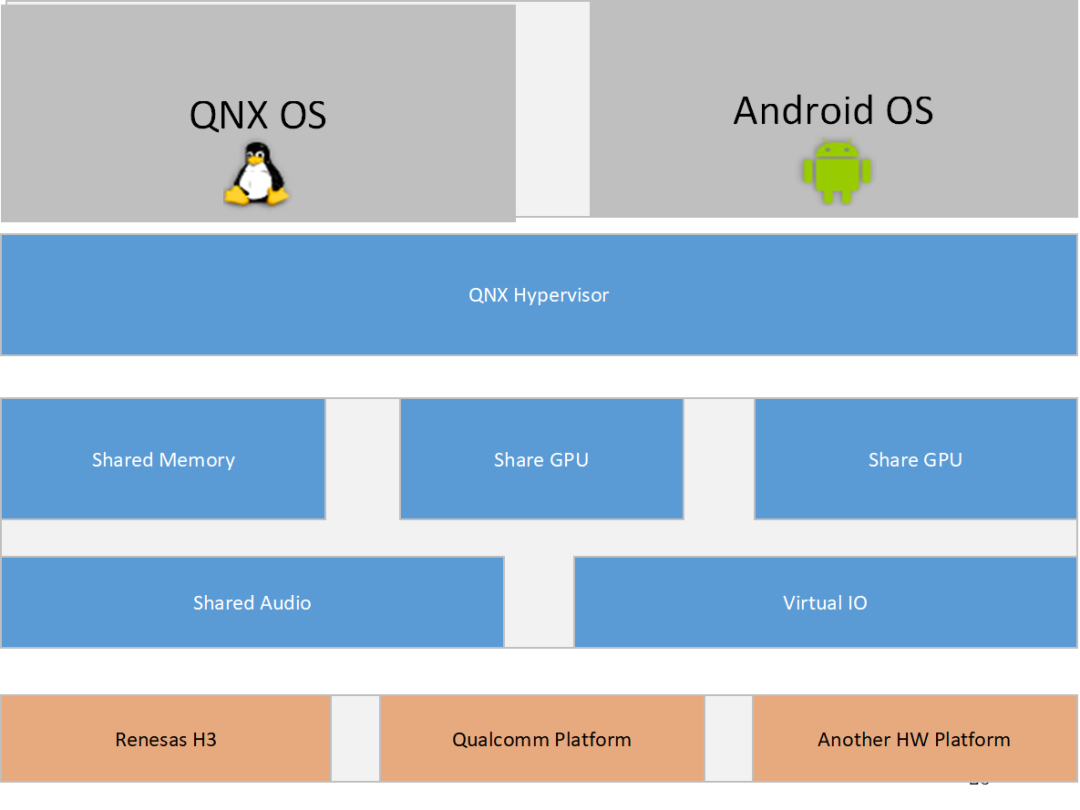
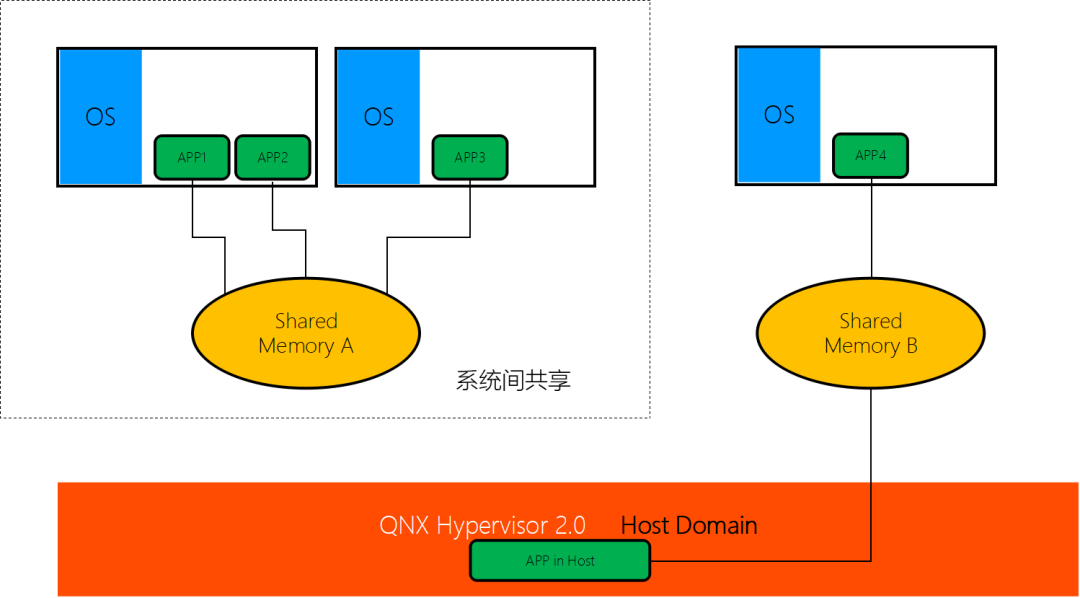
系统间的控制命令/数据通讯(不包含音频视频)可以通过 SomeIP 协议来实现。
系统间的大数据量数据通讯(比如图像/音频)可以通过共享内存的方式实现数据通讯。
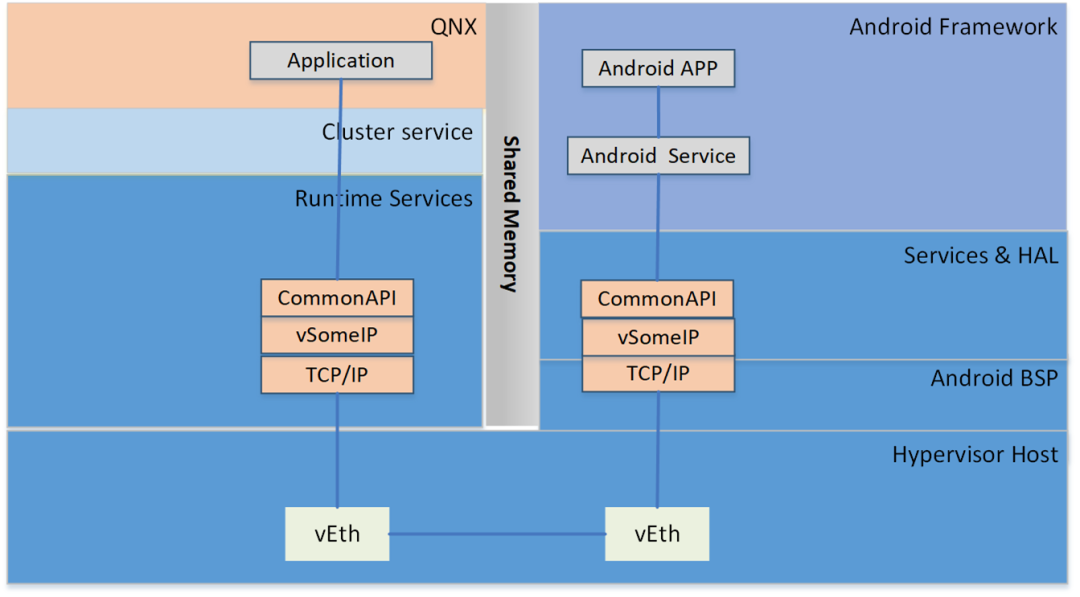
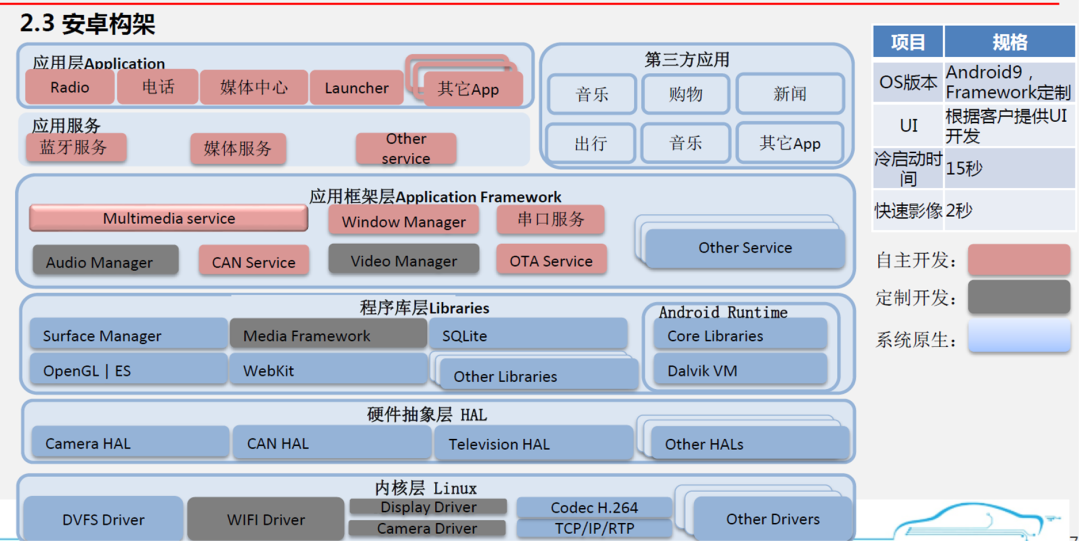
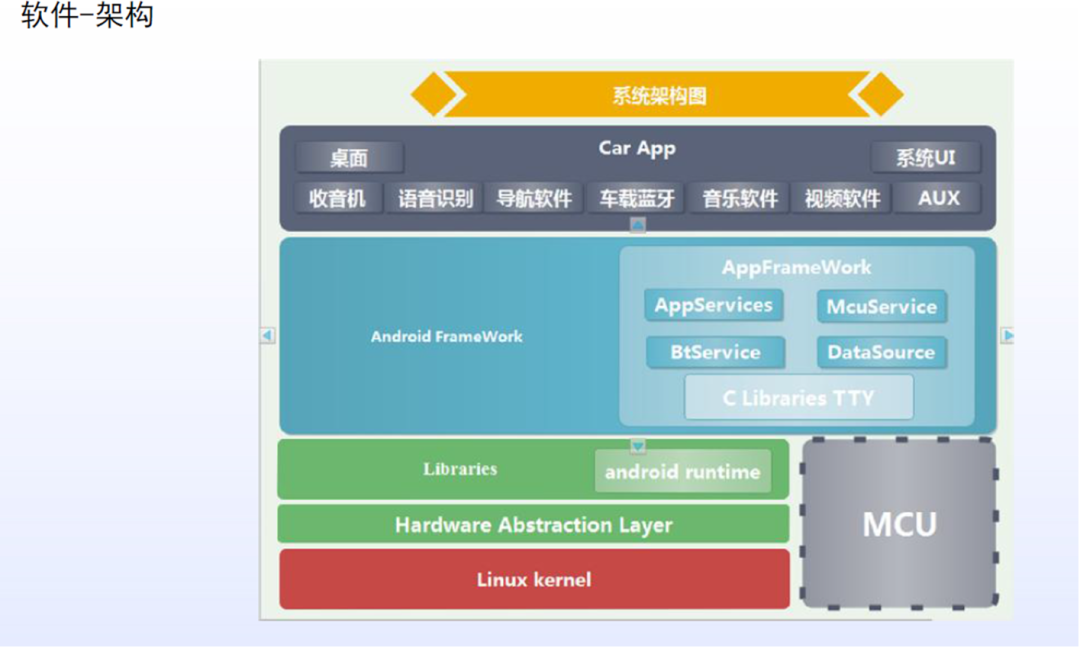
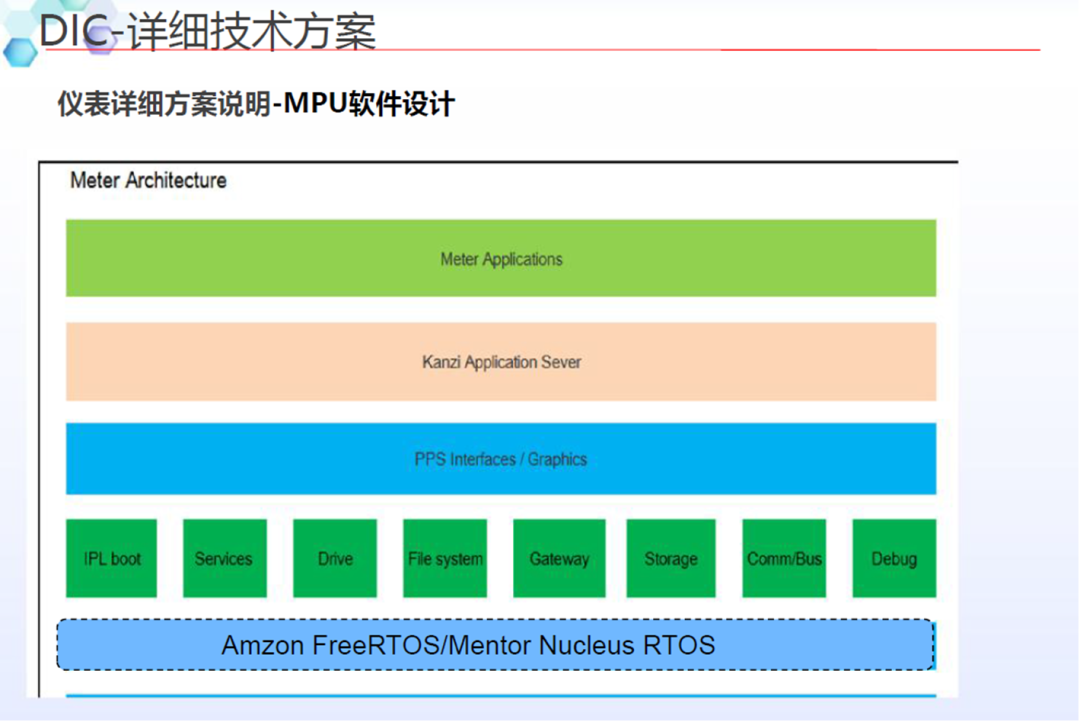
应用层:运行自研应用及第三方应用;
Framework层:支持上层android应用运行的框架,比如音频/媒体类/连接类等框架;
安卓服务层:支持应用运行的功能,以android服务的形式运行;
硬件抽象层:对上提供统一的接口,屏蔽底层驱动的不同,对下适配底层驱动。

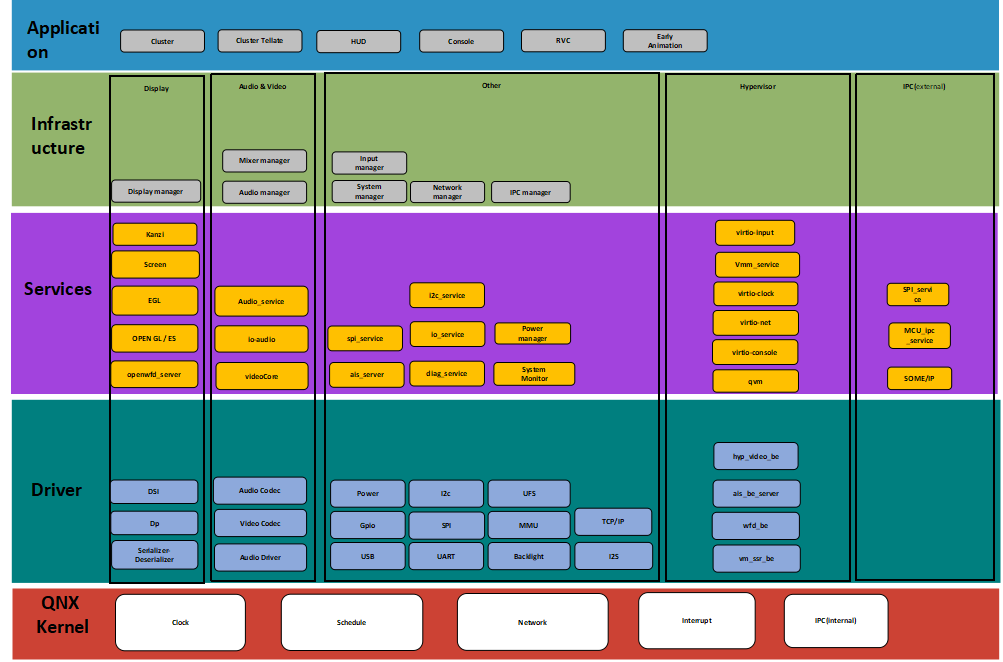
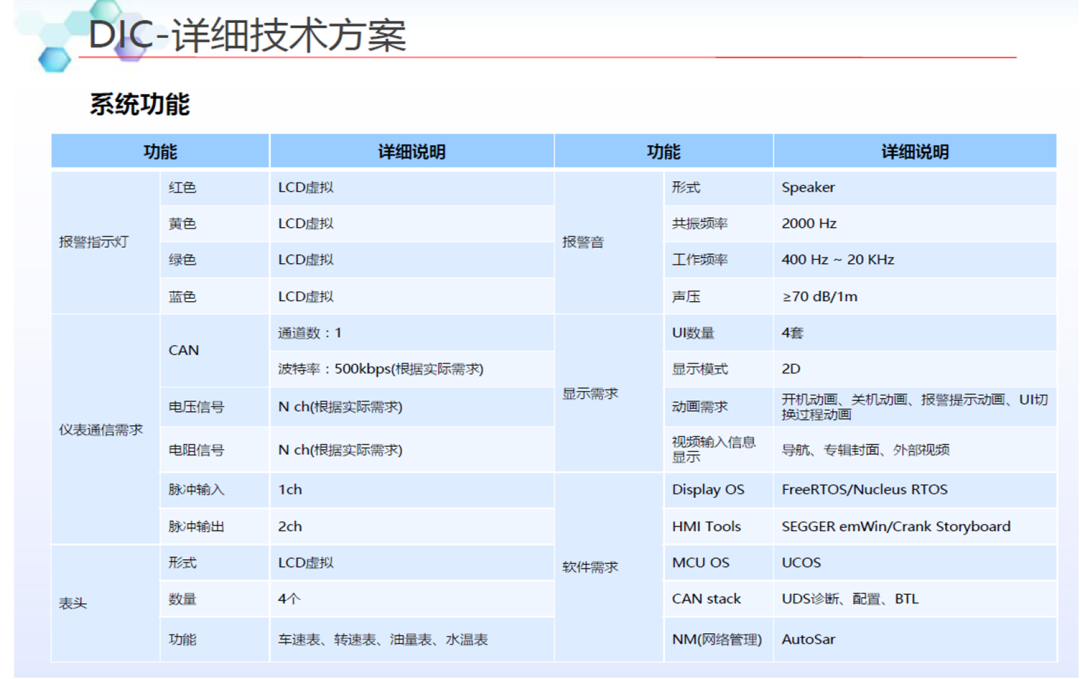
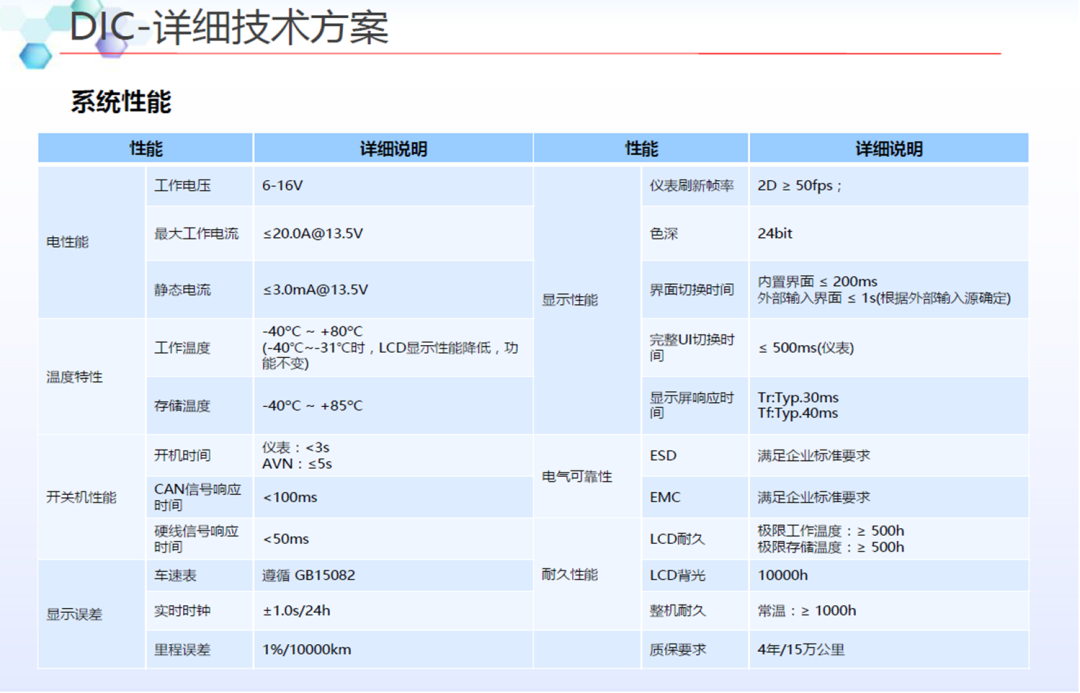
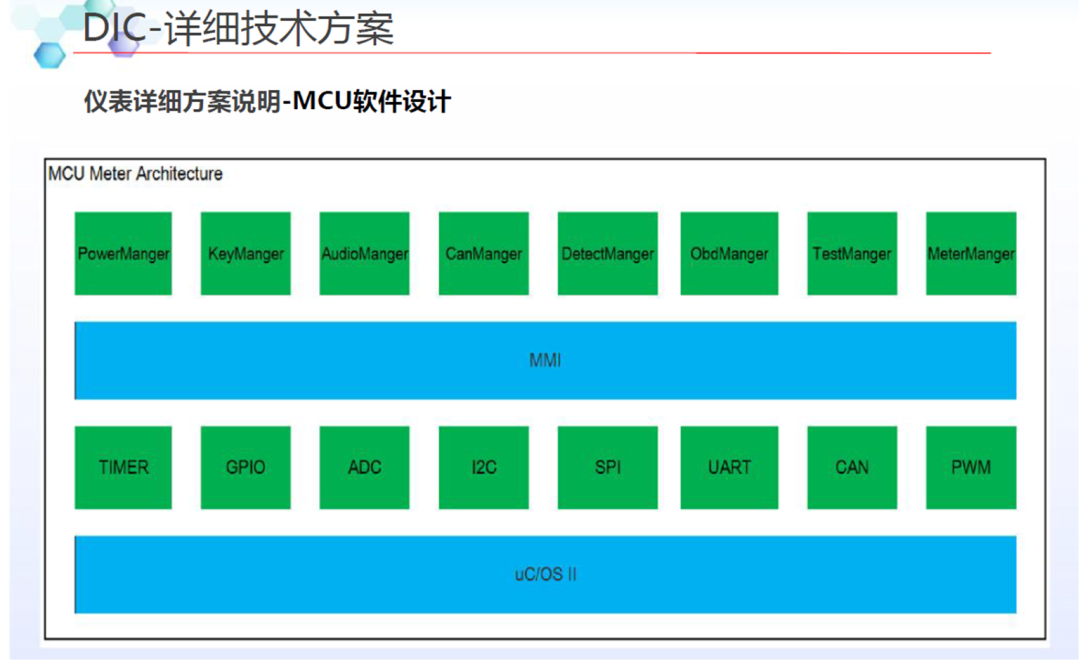
应用层:主要运行仪表速度/转速/报警灯/快速 RVC/动画等上层应用;
架构层:主要运行图形处理/音频处理/网络管理/进程间通讯框架;
服务层:主要运行进程间通讯,虚拟 IO 口的访问/音频服务/屏幕管理的逻辑;
驱动层:负责屏幕串行解串/USB/摄像头等驱动调试。
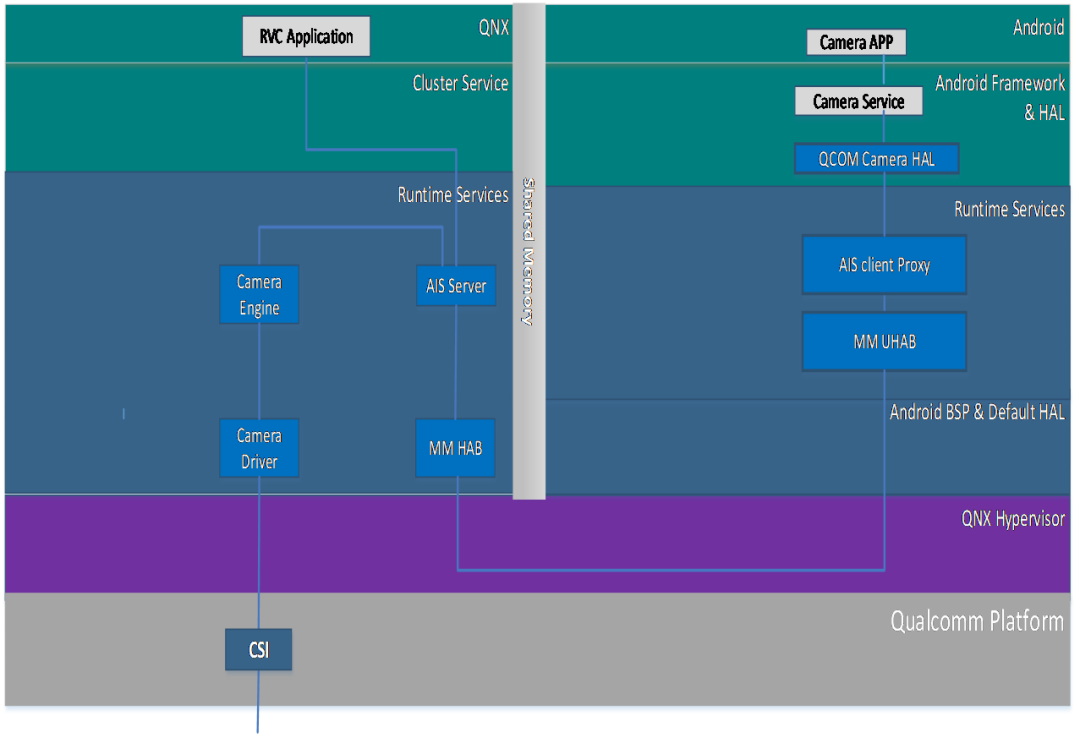
Camera 框架使用AIS框架,图像数据的采集在QNX端完成;
Android端可以通过AIS框架获取到Camera图像数据,界面的处理需要靠图层叠加来完成;
Camera的接口是CSI接口,每个CSI接口可以支持4个摄像头接入。不同高通平台的CSI接口数目不同。
屏幕的输出使用 WFD 框架。
屏幕的输出接口控制在 QNX 端。Android 端使用代理与 QNX 端通讯。
屏幕的输出接口有 DP 和 DSI 两种,具体的接口数目不同的项目不一样。





添加微信,找到我们

更多阅读



小鹏 P5 发布,有城市 NGP、配激光雷达,18 万会卖爆吗?



