

NVIDIA Ada Lovlace架构的RTX 40系列,AMD RDNA3架构的RX 7000系列都不远了,究竟谁能再次问鼎,形势也逐渐明了起来。
据权威爆料专家MLID的最新消息,NVIDIA下代显卡的性能目前可以做到对比RTX 3090提升最多60-80%,已经是非常了不起的幅度,但问题是依然不及AMD的最好水平。
他还说,如果NVIDIA倾尽全力,或许能做到提升1倍的性能,但功耗就疯了(insane)。


根据此前消息,RTX 4090已经被证实整卡功耗高达600W,相比于RTX 3090 350W几乎要翻倍了,为此不得不用上ATX 3.0电源规范中的16针辅助供电接口,最高供电能力600W。
甚至有声音怀疑,RTX 4090 Ti如果要做出来,功耗会达到恐怖的800W甚至更高,即便是RTX 4080也会有450W,也就是RTX 3090 Ti的水平。

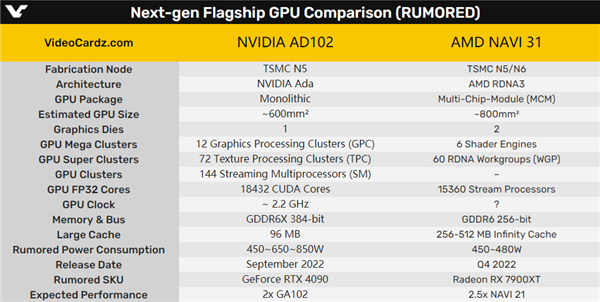
从目前情况看,NVIDIA Ada仍然会采用单一大核心设计,台积电5nm工艺,面积约600平方毫米,有望集成多达18432个CUDA核心、96MB缓存,继续搭配384-bit GDDR6X显存。
AMD RDNA3则会首次使用MCM双芯封装,台积电5nm、6nm工艺混合制造,面积预计可达800平方毫米左右,最多15360个流处理器,是现在的几乎三倍,显存还是256-bit GDDR6,但会有最多512MB无限缓存,功耗预计450-480W。
有说法称,AMD RX 7900 XT的性能可以做到RX 6900 XT 3倍左右,这几乎是不可能的,就算实现功耗也会失控,目前看2-2.5倍很有希望。
这样一来,RX 7900 XT性能超越RTX 4090就不存在什么问题额,而且功耗还低不少。
当然,一切都还在传闻阶段,继续走着瞧吧。
NVIDIA下周就要开GTC 2022大会上,老黄这次会发布什么新产品是大家最关注的,现在基本上可以断定是5nm的下一代计算卡Hopper了,这有可能是NVIDIA首款多芯封装的计算卡。
NVIDIA官方博客日前发了一篇新文章——Hopped Up: NVIDIA CEO, AI Leaders to Discuss Next Wave of AI at GTC,前面的Hopped up显然是个极为明显的暗示,结合后面的新一波AI的话来看,这就是在说新一代显卡是传闻中的5nm Hopper了。

NVIDIA的5nm显卡会继续分化,RTX 40系列游戏卡会使用Lovelace架构,Hooper则是给服务器、数据中心市场准备的,比Lovelace规模更大,有望成为NVIDIA历史上第一款MCM多芯封装GPU,内部集成两颗芯片,预计总共拥有288个SM流式多处理器,相比A100增加多达2.6倍,同时内部架构也会大改。
此前有消息称,Hopper核心晶体管多达1400亿个,面积核心达到了900平方毫米,是有史以来最大的GPU。
作为参考,NVIDIA自家旗舰Ampere架构的A100为542亿个晶体管,核心面积826mm2,可以说Hopper将是新的性能怪兽。

目光再拉近一些,NVIDIA新卡皇RTX 3090 Ti将于本月底正式发布,只剩最后十天,偷跑自然在所难免。
某加拿大零售商已经悄然列出了两款RTX 3090 Ti,价格都高得离谱,一个是风冷要4649加元(¥2.34万),一个是水冷要5234加元(¥2.64万)。
至于最终官价会不会这么高,还真不好说,大概率会低一些,但绝对不会低太多。

RTX 3090的首发价格是1499美元/11999元人民币,非公版不少都直奔2万元而去。
RTX 3090 Ti的公版价格估计会达到甚至超过1.5万元,顶级非公版绝对会轻松超过2万元。
RTX 3090 Ti首次在游戏卡上采用满血的GA102核心,10752个流处理器,84个光追单元,核心频率提供到1560-1860MHz,继续搭载24GB GDDR6X显存,但频率达到史无前例的21GHz,整卡功耗高达450W,大概率采用全新的PCIe 5.0 16针辅助接口。
可能也正是因为如此之高的规格,尤其是超高频率,RTX 3090 Ti一度严重不达标,不得不回炉重造。

哦对了,NVIDIA还搞了一个很别致的东西。
我们知道,显存容量及位宽对GPU显卡非常重要,完全依赖DRAM芯片的话成本很高。NVIDIA跟IBM联合开发了BaM(Big accelerator Memory,大型加速器内存)技术,可以让GPU直接绕过CPU限制,直连SSD硬盘,如果你有2TB的SSD,那么就是2TB的“显存”了。
现在的SSD硬盘主要是通过PCIe连接CPU的,GPU不能直接访问硬盘数据,BaM技术就是绕过这个限制的,类似技术理念早已有之,NVIDIA及IBM联合开发的BaM技术也是其中的一种。
按照他们公布的论文信息,BaM技术不依赖传统的虚拟地址转换,不再以CPU为中心,直接让GPU从内存及存储中获得数据并进行处理,无需CPU内核进行任务分配。
BaM技术的目标是扩展GPU内存容量,并提高有效的访问带宽,同时为GPU提供高级抽象,以便GPU可以按需、细粒度访问扩展内存中的海量数据。
这个BaM技术很容易让人联想到微软最近发布的DirectStorage及NVIDIA的RTX IO技术,二者本质上差不多,也是让GPU绕过CPU限制直接访问SSD上的数据,游戏中的加载时间大幅缩短,甚至可以秒进游戏。
不过BaM目前主要用于GPU高性能加速领域,包括GPU计算及机器学习等,目前还处于原型阶段,具体何时应用还没确定时间。

