
不同的平台的汇编代码是不一样的,最早的汇编在50年代就发明了,比很多人的父母的年龄都大,老掉牙,不用学习怎么写汇编。一个公司有一个人知道怎么写汇编就够了,但要学习读汇编。
为什么学习汇编?
性能
直接翻译为机器语言,性能最高。优秀的C语言效率只能达到汇编的80%左右。其他高级语言跟汇编一比差得更远。语言越高级性能越差。很多bootloader和BIOS用汇编写,汇编操作的是电脑,手机刚刚上电时,硬件和初始化的那些命令,它们的性能的要求比较高,效率高开机速度更快。
分析问题
个人认为,编程人与机器对话,我们写C,写JAVA,但是电脑并不认识这些语言,电脑只认识0和1;所以需要一个人来翻译这些语言,这个翻译官就是编译器,但是编译器不能百分之百准确的表达程序员的意思,也就是所谓的翻译有反义。例如,编译器为了性能好一点,可能会优化变量和语句,这个过程可能好心办坏事,把有用的操作优化了。因此只有看懂一些汇编语句,才能分析程序真正执行的流程。在问题难以定位的情况下,汇编可能是分析问题的最后一根稻草。
帮助理解硬件
有些学校的单片机课程是以汇编进行教学的,主要原因就是汇编更贴近硬件。不过我不赞成这种做法,C语言能快速做出一点东西,有利于学生在放弃之前,增加成就感,好坚持下去。但是汇编确实更贴近硬件。
为了便于理解下文,先介绍下LDR指令,其格式如下:
LDR{条件} 目的寄存器 <存储器地址>作用:将 存储器地址 所指地址处连续的4个字节(1个字)的数据传送到目的寄存器中。LDR指令的寻址方式比较灵活,实例如下:
LDR R0,[R1] ;将存储器地址为R1的字数据读入寄存器R0。LDR R0,[R1,R2] ;将存储器地址为R1+R2的字数据读入寄存器R0。LDR R0,[R1,#8] ;将存储器地址为R1+8的字数据读入寄存器R0。LDR R0,[R1],R2 ;将存储器地址为R1的字数据读入寄存器R0,并将R1+R2的值存入R1。LDR R0,[R1],#8 ;将存储器地址为R1的字数据读入寄存器R0,并将R1+8的值存入R1。LDR R0,[R1,R2]! ;将存储器地址为R1+R2的字数据读入寄存器R0,并将R1+R2的值存入R1。LDR R0,[R1,LSL #3] ;将存储器地址为R1*8的字数据读入寄存器R0。LDR R0,[R1,R2,LSL #2] ;将存储器地址为R1+R2*4的字数据读入寄存器R0。LDR R0,[R1,R2,LSL #2]!;将存储器地址为R1+R2*4的字数据读入寄存器R0,并将R1+R2*4的值存入R1。LDR R0,[R1],R2,LSL #2 ;将存储器地址为R1的字数据读入寄存器R0,并将R1+R2*4的值存入R1。LDR R0,Label ;Label为程序标号,Label必须是当前指令的-4~4KB范围内。
要注意的是:
LDR Rd,[Rn],#0x04 ;这里Rd不允许是R15。另外LDRB 的指令格式与LDR相似,只不过它是将存储器地址中的8位(1个字节)读到目的寄存器中。LDRH的指令格式也与LDR相似,它是将内存中的16位(半字)读到目的寄存器中。
LDR R0,=0xff这里的LDR不是arm指令,而是伪指令。这个时候与MOVE很相似,只不过MOV指令后的立即数是有限制的。这个立即数必须是0X00-OXFF范围内的数经过偶数次右移得到的数,所以MOV用起来比较麻烦,因为有些数不那么容易看出来是否合法。
如何在KEIL下阅读汇编
按d进入debug模式,在view下选择disassembly window 。
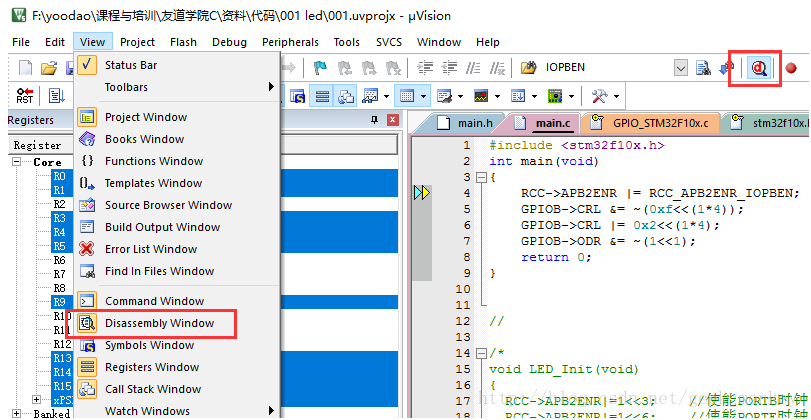
看光标,c文件下指向了main函数的第一行。
汇编窗口也指向了对应的语句。但是,在执行C语言的第一行之前,仍然有许多操作要做,比如变量放在哪?在哪里调用了main函数等,这些操作都被集成开发环境IDE给封装起来了。我们必须知道,在执行main函数之前,有许多事情要做,只不过,初学的时候不必理会。以下是C语言源码,功能是点亮LED。
//main.c#includeint main(void){RCC->APB2ENR |= RCC_APB2ENR_IOPBEN;GPIOB->CRL &= ~(0xf<<(1*4));GPIOB->CRL |= 0x2<<(1*4);GPIOB->ODR &= ~(1<<1);return 0;}//main.h#define RCC_APB2ENR (*(unsigned int *)0x40021018)#define GPIOB_CRL (*(unsigned int *)0x40010c00)#define GPIOB_ODR (*(unsigned int *)0x40010c0c)
汇编窗口往上翻,确实很多语句,先看这几行代码的汇编:

先说最常用的两句汇编:
LDR r0,[r1] r0 = *r1STR r0,[r1] *r1 = r0MOV r0,r1 r1->r0拷贝
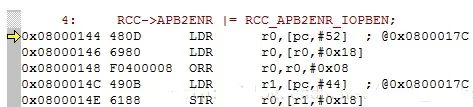
从内存0x0800 017c的32位数据拷贝到r0:
r0 = * 0x0800 017c我们看到的 1000 4002其实 就是0x4002 1000。这里边有个知识点叫做大小端模式,以下简单讲解,不能理解就记住。

这个数据是在地址是这么存放的:
7C 7D 7E 7F
00 10 02 40
实际数据是0x4002 1000
* 0x0800 017c=0x4002 1000
然后r0的值+0x18也就是24 因为这个是第6号(第6号就是第7个的意思)元素
得到r0 = *0x4002 1018,r0的值由一个地址,变成了地址所存放的数据。
然后是或0x08操作,结果再复制给r0,*0x4002 1018 |=0x08
给r1分配地址,这个地址也是0x4002 1000, r1 = *0x4002 1000
把r0存放的值,(不是r0的地址,)存到r1+18的空间上
*(r1+0x18) = r0
*0x4002 1018 = (*0x4002 1018 |=0x08)
*0x4002 1018|=0x08
最终结果:地址4002 1018的数,执行了或0x08的操作。再分析下一句 :
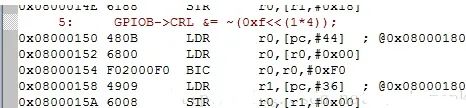
前两句给r0分配空间,r0 = *0x4001 0c00
然后用BIC清除数据位,把4-7位清零,结果再赋值给r0。
*0x4001 0c00 &= ~(0xf0)r1 = *0x4001 0c00*0x4001 0c00 &= ~(0xf0)
剩下的不再详细分析,直接给答案 :
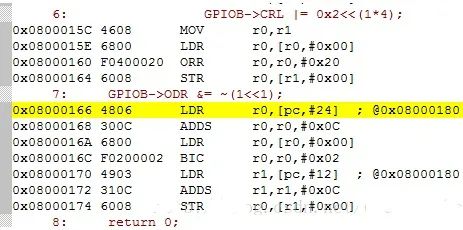
***0x4001 0c00 |= 0x200x4001 0c0c &= ~(0x02)*
最终,可以看到C语句被翻译成了意料之中的汇编语句,自己的意图被机器准确的理解了。
1.别错过嵌入式系统与软件领域年度盛会~
2.两会中的“芯”提案
3.AMD将用FPGA干什么?
4.串口传输中,共用体和结构体如何转换?
5.RISC-V CTO: 我们不会像 Arm 和 x86 那样左右芯片的设计
6.C函数指针别再停留在语法,得上升到软件设计~

免责声明:本文系网络转载,版权归原作者所有。如涉及作品版权问题,请与我们联系,我们将根据您提供的版权证明材料确认版权并支付稿酬或者删除内容。
