点击蓝字
关注我们,让开发变得更有趣
内容来源|刘金龙
文章排版|李擎
Bert tiny 介绍及 OpenVINO 部署
一、Bert介绍
Bert是应用于NLP领域的语言模型技术,Transformer、 Encoder 、Decoder 是其核心技术。本博客的目的是教大家快速上手 bert。
1.1 Bert 能解决什么问题
1、结合上下文理解语义,其不分先后提取了语句中单个词的所有的指代关系,解决了单向信息流问题, 这是RNN\LSTM做不到的。
2、其优点是解决了堆叠多层LSTM带来的网络臃肿,计算慢的问题。
Example:
今年新收的小米特别香。
今天新发布的小米手机太棒了。
Bert的实质则是结合上下文语义帮助理解“小米”在句中的具体含义。
1.2 Bert 的前置知识
WORDTO NEC:文本向量化——让计算机看的懂的词句表达方式。
RNN\LSTM:基础网络模型,能够理解文本的语义
二、Bert的架构图
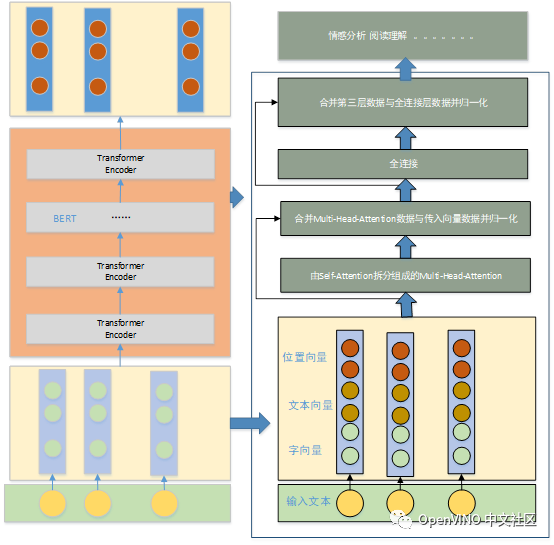
2.1 向量表示部分
其中向量表示单元包含:字向量、文本向量、位置向量。位置向量的作用为解决时序问题。
2.2 Bert结构部分
(1)由self-Attention拆分组成的Multi-Head-Attention
Attention解决了不能并行执行的问题,通过多头机制达到多种不同层次的语义表达的效果。其是transformer-encoder的核心。
(2) 合并Multi-Head-Attention数据与传入向量数据并归一化
合并是通过残差操作完成的,其目的是保证随着网络的加深网络训练效果不会变差。
归一化的目的是起到数据增强的效果,
归一化是把隐藏层的数据归一为标准正态分布,起到加速训练速度,加速收敛的作用。
(3) 全连接
全连接层进行数据提取。使用了两层全连接,第一层使用了激活函数进行激活,提取特征。第二层对第一层的特征数据进行维度变换使其可与第一层的layerNorm一样的维度,便于残差计算。
(4)合并第三层数据与全连接层数据并归一化
残差连接进行数据合并,其目的是保证多层特征提取后不丢失主要语义,使得效果越来越好。
2.3应用层
应用层主要是对特征数据的具体应用,主要场景有:情感分析、阅读理解、序列标注等等。
三、BERT训练
3.1 预训练任务
1 Masked LM
随机将一句话中一定比例的字(token)进行掩盖,具体规则为:
(1)80%的token替换成「mask」
(2)10%的保持原样
(3)10%的随机替换为其他词句。
2 NextSentence Prediction
预测两句话是否是上下文的关系,其机制是分别给出正确的语句与错误的语句让模型进行对比学习。
Bert模型通过对Masked LM任务和Next Sentence Prediction 任务进行联合训练,使模型输出的每个字/词的向量表示都能尽可能全面、准确地刻画输入文本(单句或语句对)的整体信息,为后续的微调任务提供更好的模型参数初始值。
3.2 训练
BERT,它用Transformer的双向编码器表示。与最近的其他语言表示模型不同,BERT旨在通过联合调节所有层中的上下文来预先训练深度双向表示。因此,预训练的BERT表示可以通过一个额外的输出层进行微调,适用于广泛任务的最先进模型的构建,比如问答任务和语言推理,无需针对具体任务做大幅架构修改。
其中层数(即 Transformer 块个数)表示为 L,将隐藏尺寸表示为 H、自注意力头数表示为 A。在所有实验中,将前馈/滤波器尺寸设置为 4H,即 H=768 时为 3072,H=1024 时为 4096。
为了进行比较,论文中选择,BERTBASE 的模型尺寸与OpenAI GPT具有相同的模型大小。然而,重要的是,BERT Transformer 使用双向self-attention,而GPT Transformer 使用受限制的self-attention,其中每个token只能关注到其左侧的上下文。注意需要的是,在文献中,双向 Transformer 在文献中通常称为「Transformer 编码器」,而只关注左侧语境的版本则因能用于文本生成而被称为「Transformer 解码器」。BERT,OpenAI GPT和ELMo之间的比较如下图一所示。
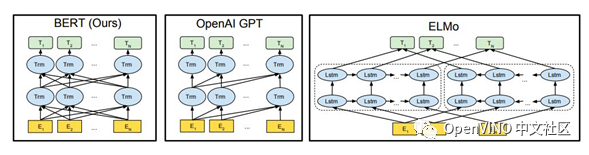
图1:预训练模型架构的差异
BERT使用双向Transformer。OpenAI GPT使用从左到右的Transformer。ELMo使用经过独立训练的从左到右
和从右到左LSTM的串联来生成下游任务的特征。三个模型中,只有BERT表示在所有层中共同依赖于左右上下文。
四、TinyBERT
4.1 TinyBERT 介绍
BERT 等大模型性能强大,但很难部署到算力、内存有限的设备中。为此,来自华中科技大学、华为诺亚方舟实验室的研究者提出了 TinyBERT,这是一种为基于 transformer 的模型专门设计的知识蒸馏方法,模型大小还不到 BERT 的 1/7,但速度是 BERT 的 9 倍还要多,而且性能没有出现明显下降。目前,该论文已经提交机器学习顶会 ICLR 2020。
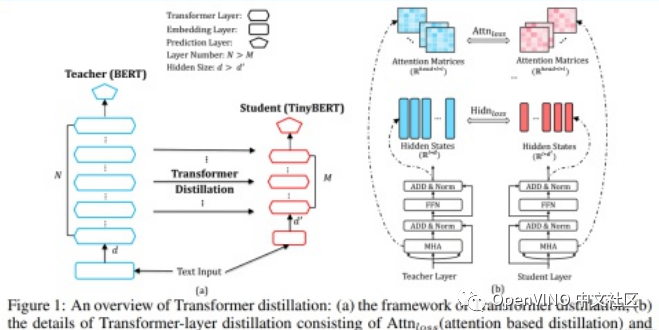
上图描述了bert知识蒸馏的过程,左边的图整体概括了知识蒸馏的过程:左边是Teacher BERT,右边是Student TinyBERT,论文的目的是将Teacher BERT学习到的知识迁移到TinyBERT中;右边的图描述了知识迁移的细节,在训练过程中选用Teacher BERT中每一层transformer layer的attention矩阵和输出作为监督信息。
4.2 BERTtiny源码
用BERTtiny的源码实现一下NER(命名实体识别,named entity recognition)任务,这里简单记录一下思路和方法。这里只放BERT的源码,改动的代码大家可以根据思路自己改一下,也当给自己缕清一下思路。
第一步,明确任务:我们将 NER 任务视为序列标注任务,标注方式采用BIOES标注。这里标注方式有很多种,例如最常见的BIO标注,BMEOS标注等。一般来说B(Begin)代表entity的第一个token,E(End)代表entity的最后一个token,I(Inside)代表entity中间的token,O(Outside)代表非entity的token,S(Single)代表只有一个token的entity。
例如:傻(B)大(I)姐(E)借(O)口(O)给(O)二(B)妹(E)送(O)钱(S)
采去BIOES标注方式的原因是BIO标注只关注了实体边界的起始位置,结束位置没有明确地标注,BIOES标注的信息更加丰富,有完整实体边界的信息,更方便进行后续任务。
第二步,明确方法:我们知道谷歌提出的BERT模型是现在所有NLP任务的baseline,几乎横扫了之前所有的方法。序列标注任务与BERT源码(https://github.com/google-research/bert)中的文本分类任务(run_classifier.py)比较类似。所以我决定在这个代码的基础上进行改动,使其适应序列标注任务。
with open("train_data","rb") as f:data = f.read().decode("utf-8")train_data = data.split("\n\n")train_data = [token.split("\n") for token in train_data]train_data = [[j.split() for j in i ] for i in train_data]train_data.pop()
载入bert部分
from kashgari.embeddings import BERTEmbeddingfrom kashgari.tasks.seq_labeling import BLSTMCRFModelembedding = BERTEmbedding("bert-base-chinese", 200)
搭建训练模型部分
model = BLSTMCRFModel(embedding)model.fit(train_x,train_y,epochs=1,batch_size=100)
查看网络结构
__________________Layer (type) Output Shape Param # Connected to ==================================================================================================Input-Token (InputLayer) (None, 200)__________________________________________________________________________________________________Input-Segment (InputLayer) (None, 200) 0(None, 200, 10) 1410 dense_3[0][0] ==================================================================================================Total params: 103,603,714Trainable params: 2,166,274Non-trainable params: 101,437,440__________________________________________________________________________________________________Epoch 1/1506/506 [==============================] - 960s 2s/step - loss: 0.0377 - crf_accuracy: 0.2892 - acc: 0.2759
4.3 OpenVINO 模型部署
使用OpenVINO部署模型需要用到两个工具套件:model optimizer 和inference engine .其中model optimizer用于深度神经网络模型的优化并转化为统一的能够被inference engine 读取、加载并执行推理的IR格式的模型文件。inference engine 是提供了C++/python API的模型推理函数库,用于读取、加载、设置模型参数并获得推理结果。
4.3.1 模型转换
首先我们下载OpenVINO的源码,从github上下载。进入源码用以下代码将我们的onnx模型转换成IR的模型
python3/deployment_tools/model_optimizer/mo.py \ --input_model INPUT_MODEL \--output_dir
OUTPUT
Model Optimizer arguments:Common parameters:- Path to the Input Model: /root/autodl-tmp/uer_py_ner_part.onnx- Path for generated IR: /root/autodl-tmp/uer_py_ner_part.xml- IR output name: uer_py_ner_part- Log level: ERROR- Batch: Not specified, inherited from the model- Input layers: Not specified, inherited from the model- Output layers: Not specified, inherited from the model- Input shapes: Not specified, inherited from the model- Mean values: Not specified- Scale values: Not specified- Scale factor: Not specified- Precision of IR: FP32- Enable fusing: True- Enable grouped convolutions fusing: True- Move mean values to preprocess section: None- Reverse input channels: FalseONNX specific parameters:- Inference Engine found in: /usr/local/lib/python3.6/dist-packages/openvinoInference Engine version: 2021.4.1-3926-14e67d86634-releases/2021/4Model Optimizer version: custom_master_1ffeb24a419c8b9c328a4d6735f41c946ee8bae3[ WARNING ] Model Optimizer and Inference Engine versions do no match.[ WARNING ] Consider building the Inference Engine Python API from sources or reinstall OpenVINO (TM) toolkit using "pip install openvino" (may be incompatible with the current Model Optimizer version)[ WARNING ] Convert data type of Parameter "input.1" to int32[ WARNING ] Convert data type of Parameter "1" to int32[ WARNING ] Convert data type of Parameter "input.5" to int32[ SUCCESS ] Generated IR version 10 model.[ SUCCESS ] XML file: /root/autodl-tmp/uer_py_ner_part.xml/uer_py_ner_part.xml[ SUCCESS ] BIN file: /root/autodl-tmp/uer_py_ner_part.xml/uer_py_ner_part.bin[ SUCCESS ] Total execution time: 1235.61 seconds.[ SUCCESS ] Memory consumed: 1506 MB.It's been a while, check for a new version of Intel(R) Distribution of OpenVINO(TM) toolkit here https://software.intel.com/content/www/us/en/develop/tools/openvino-toolkit/download.html?cid=other&source=prod&campid=ww_2021_bu_IOTG_OpenVINO-2021-3&content=upg_all&medium=organic or on the GitHub*
那么我们就把模型转换成了 OpenVINO 的IR模型。我们来做一下实验这个会不会带来我们推理速度的提升。
4.3.2 使用 Benchmark 进行基准测试
Benchmark Tool 用来评估支持的设备上的深度学习推理性能,这里针对CPU、GPU测试了不同计算平台的性能基准差异。下面是GPU执行测试的操作:


我们发现该模型在GPU上的性能更好一些,具体数据如下表:
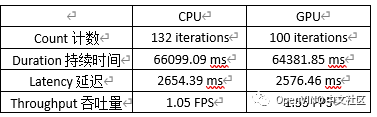
4.3.3 模型部署
使用 OpenVINO 的 inference engine 进行模型推理有八步,如图:
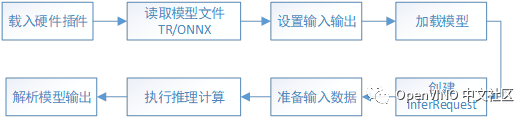
(1)载入硬件插件:创建Core对象进行管理所有AI计算硬件;
(2)读取模型:将模型文件读入到Network类的实例对象中;
(3)设置输入输出:指定模型输入/输出的精度和布局;
(4)加载模型:将设置好参数的模型用LoadNetwork()方法载入到计算硬件中;
(5)创建inferRequest: 创建用于推理计算的对象;
(6)准备输入数据:按模型的输入要求准备输入数据;
(7)执行推理计算:推理计算分为同步推理和异步推理;
(8)解析输出结果:输出结果一般是张量形式,按照编码规则解析为自己想要的格式。
将训练好的pt模型转换成onnx 或IR格式很方便,几行代码就搞定。由于openvino目前最新版本即适用于IR格式的模型读取,也适用于onnx格式的模型读取。接下来以onnx格式为例说明一下部署过程:
import osimport numpy as npfrom openvino.inference_engine import IECorefrom tqdm import tqdmie = IECore()exec_net = ie.load_network(network=os.path.join(os.getcwd(), "uer_py_ner_part.onnx"), device_name="CPU")print("loaded network")ort_session_inputs = {}ort_session_inputs["input.1"] = np.random.randint(2, size=(16, 128))ort_session_inputs["1"] = np.random.randint(2, size=(16, 128))result = exec_net.infer(ort_session_inputs)print(result)for i in tqdm(range(100)):result = exec_net.infer(ort_session_inputs)
4.4 onnx run time 的推理部分代码
import numpy as npimport onnximport onnxruntime as ort# Load the ONNX modelfrom tqdm import tqdmmodel = onnx.load("./uer_py_ner_part.onnx")# Check that the IR is well formedonnx.checker.check_model(model)# Print a human readable representation of the graph# print(onnx.helper.printable_graph(model.graph))def ort_session_test(ort_session):outputs = ort_session.run([label_name],ort_session_inputs,)# print(outputs)# print(outputs[0])if __name__ == '__main__':ort_session = ort.InferenceSession("./uer_py_ner_part.onnx")# print(ort_session)label_name = ort_session.get_outputs()[0].name# print(ort_session.get_inputs())ort_session_inputs = {}for input in ort_session.get_inputs():# print(input)# print(input.name)# print(input.shape)ort_session_inputs[str(input.name)] = np.random.randint(2, size=(16, 128))# print(ort_session_inputs)ort_session_test(ort_session)for i in tqdm(range(100)):ort_session_test(ort_session)
4.5 output 比对
对于微软的 onnx run time 的相应速度来看并没有提升。以下是同样的模型对比的模型部署效果。
100%|██████████| 100/100 [04:09<00:00, 2.49s/it]需要4分09秒
OpenVINO output
100%|██████████| 100/100 [03:21<00:00, 2.01s/it]现在只需要3分21秒。有挺大的提升,还是很能看出来 OpenVINO 的功力的。
五、小结
BERT 就像图像领域的 Imagenet,通过高难度的预训练任务,以及强网络模型去预先学习到领域相关的知识,然后去做下游任务。在模型部署方面,如图只有CPU机器,通过对比,OpenVINO 的性能还是具有优越性的,是我们工程化部署的得力工具。
--END--

