




继续日前英伟达内网遭遇黑客攻击之后,据外媒报道, 半导体硅晶圆(硅片)大厂环球晶圆在日本的子公司近日也遭到了黑客攻击。不过环球晶圆回应称,已在检查生产线的系统与终端设备,确保安全后就会重启,对整体运营影响不大。
报道称,环球晶圆日本子公司内部IT部门和外部专业人员已经在逐步处理中,并且硅晶圆生产大部分可以离线进行,所以此次遭受网络攻击的影响并不大。
此外环球晶圆还表示,该公司的系统都有自动备份功能,即便遭受攻击,所有信息也可以顺利复原,在确保安全后公司即可恢复正产生产。编辑:芯智讯-林子
 此处广告,与本文无关
此处广告,与本文无关
日前,IPU公司Graphcore(拟未)宣布推出其全新称为Bow的IPU,以及计算刀片:Bow-Machine和计算系统Bow Pod系列。相比较搭载第二代IPU——Colossus Mk2 GC200的M2000而言,Bow Pod系列可以实现总体40%的性能提升,以及每瓦性能16%的提升。
摩尔定律放缓,封装跟上
摩尔定律放缓已经成为了一个不争的事实。而其失效原因,归根结底是在于漏电与散热问题,因此业界纷纷提出各种解决方案,包括DSA架构、3D封装等,小心地避开晶体管物理陷阱。
实际上在Graphcore宣布推出Mk1时,就采用了多内核计算与细粒度存储SRAM紧耦合的架构,从而解决AI时代所面临的数据传输瓶颈。而这也收获了明显的成绩——其第二代IPU直接叫板英伟达的A100系列,并给出了在多个主流模型上的实际测试结果。

对比Mk1,Mk2的晶体管数量翻了一倍多,基本都增加到了片内SRAM上,从304MB增加到了将近900MB,使得其性能相比Mk1增加了8倍之多,工艺制程也从台积电的16nm升级至7nm。
如果说Mk1和Mk2是Graphcore通过创新DSA架构,实现了性能的飞跃。如今,为了进一步解决散热问题,其与台积电合作,通过WoW(Wafer on Wafer)3D封装方式,实现了性能及功耗比的进一步提升。

通过Graphcore Bow产品的宣传资料可以看出,多出来的将近6亿颗晶体管,一方面是增加了数据吞吐率,另外则是为了优化电源结构。
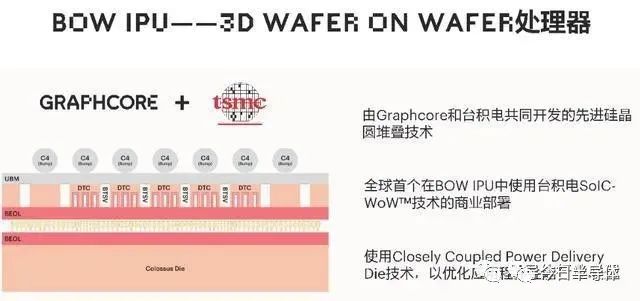
如图所示,底层结构依然为IPU的计算和存储单元,但是上层Wafer使用了Closely Coupled Power Delivery Die技术,使得供电网络可以以最短的路径为下层IPU供电,从而实现更小的损耗。
正如台积电在2021年财报中所述,公司的SoIC技术同时提供晶圆对晶圆(Wafer on Wafer,WoW)或是晶片对晶圆(Chip on Wafer,CoW)制程,能够同时堆叠同质或异质晶片,大幅提升系统效能,并且缩小产品晶片尺寸。在CoW制程研发持续进行的同时,台积电公司的WoW的技术,已经成功于2020年,在逻辑对记忆体以及逻辑对深沟槽电容(Deep Trench Capacitor,DTC)的垂直异质整合(Heterogeneous Integration)上,展现出优异的电性能。
Graphcore大中华区总裁兼全球首席营收官卢涛也表示,5nm与7nm相比,生产工艺所带来的收益并不像第一代的16nm与第二代的7nm那样,而是只有20%左右的提升,但我们可以通过诸如封装等创新,可以更加容易地获取同样收益。

而根据此前台积电所给出的路线图,2022年N7+DTC的推出日期,刚好与Graphcore的Bow产品相吻合。
值得注意的是,此次Bow的发布,不只是芯片,同时也包括了可立即发货且灵活配置的IPU系统,这也标志着Bow的成功量产。

软件进一步优化
除了硬件本身之外,Graphcore产品性能的提升,也得益于其整个软件栈的生态系统。Graphcore中国工程副总裁、AI算法科学家金琛表示,其中最核心的是Poplar SDK,包括驱动、图编译器PopART、上层backend等,此外还提供了各类AI软件框架,API等支持。而正是因为Bow与此前的产品在结构上没有任何更改,因此软件代码可实现100%兼容。
金琛同时介绍道,其中针对模型性能优化的工作,大部分由中国团队负责。而根据Graphcore给出的一组实测数据结果,也显示出在不同的模型下,性能均有所提升,这其中一部分原因是处理器性能提升,另外则是针对模型进行了许多优化。
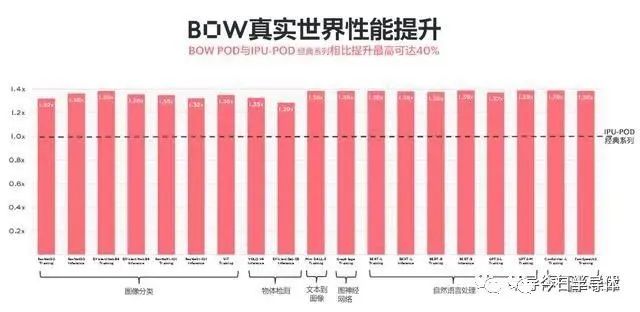
得益于Bow系统软硬件的优化,其与英伟达的DGX-A100相比,性价比优势进一步突出,TCO(总体拥有成本)仅为英伟达的1/10。

AI芯片不能完全依赖DSA
如今,随着AI模型算法的迅速迭代,有些DSA架构的处理器,在模型更新后,就显得力不从心了。卢涛对此表示,早些年业界谈AI,必然离不开CNN,因此诞生出很多针对CNN计算优化的加速器,也采用了先进制程,并且提供数百pFLOPS算力,在CNN上确实能够达到A100级别的表现。但是,随着业界转向Transformer,其算力可能只能达到V100级别。
Graphcore的IPU推出之时,并没有针对某个模型进行架构优化,而是通过搭建底层计算图架构,从而支持广泛的模型。实际在2020年,Graphcore就捕捉到了Transformer的趋势,并开发了许多基于Transformer的视觉和语音模型。也正因此,在如今Transformer的应用场景中,Graphcore的IPU在训练上可以和英伟达打个平手,但是在推理上则具有明显的优势。
与中国客户的广泛合作
去年一年中,Graphcore与包括升哲科技、安捷中科、深势科技等公司围绕包括城市治理、气象以及分子动力学等领域开展合作。同时也与几家主流的互联网云厂商合作,包括金山云推出了基于Graphcore IPU平台的服务器产品——金山云IPU服务器,用于AI任务在云端的训练和推理,这也是中国首个大型公有云厂商对外公开推出自己的IPU云产品。此外,Graphcore也与神州数码签署了合作协议,通过各种灵活的方式,为客户提供IPU的相关产品。

目前,Graphcore的全球客户,涵盖国家实验室、医药健康、保险、云以及其他科学、金融等方面。其中,Pacific Northwest成为了首批Bow Pod用户,基于Transformer的模型以及图神经网络,进行计算化学和网络安全方面的应用。
超越人脑的古德计算机
除了Bow系列产品之外,卢涛还介绍了Graphcore正在开发的超级智能AI计算机Good Computer计划——古德计算机,预计2024年交付,用以纪念计算机科学先驱杰克·古德。其率先在其1965年的论文《关于第一台超级智能机器的推测》中描述了一种超越大脑能力的机器。
根据Graphcore的规划,古德计算机将包括8192个未来计划中的IPU,能够提供超过10 Exa-Flops的AI算力,实现4 PB的存储单元,可助力超过500万亿参数规模的人工智能模型的开发。预计价格在100万美元到1.5亿美元的规模。
卢涛表示,人类大脑中大概有860亿个神经元,100万亿个突触。目前最大的人工智能模型的参数跟真正的人的大脑比较起来,可能还有100倍左右的差距。而未来古德计算机的规划,就是要成为超越人脑的超级智能机器。
卢涛同时认为,该架构的整体思路依然会沿用如今的IPU体系,主要原因是Graphcore多年来针对其硬件和软件的积累,以及用户的使用习惯的延续。
目前Graphcore IPU中具有1472个tiles(处理器内核),也有高达900MB的SRAM处理器内存,运作机理和大脑的神经元类似,但这并不是类脑或存内计算架构。
实际上,就目前来看,无论是类脑,还是存内计算,都距离商业化较为久远,其中最主要原因依然是精度问题。
除此之外,金琛也补充道,想超越人脑,在模型方面,也需要支持稀疏化,通过低功耗执行大规模的模型,目前Graphcore在稀疏化方面也一直在进行一些尝试。2021年,Graphcore曾经发表过一篇研究论文,以IPU上的大型语言模型预训练为例,演示了如何有效地实施稀疏训练。
AI芯片的X×Y×Z矩阵
卢涛表示,如今的AI领域,面临着X×Y×Z的抉择关系,其中X代表应用,Y是框架,Z是处理器,如果大家都沿着不同应用,不同框架,不同处理器去做研发和优化,那么X×Y×Z的可能性会非常多。但随着业界逐渐有一套稳定的主赛道之后,对于芯片厂商会有很多好处,尽管赛道的人可能更多,但这条路会变得很宽,同时也不会出现跑偏的情况,这有助于厂商获得更广泛的开发者和市场。
显然,目前Graphcore所处赛道的正前方,一直都是英伟达。
*免责声明:今日半导体 转载仅为了传达一种不同的观点,不代表今日半导体对该观点赞同或支持,内容如有侵权,请联系本部删除!手机微信同15800497114。

关注 今日半导体 公众号,掌握半导体新动态!



