

黄鹏,目前就职于某网络安全公司,主要工作内容是DPDK应用程序性能调优,从事过企业级路由器维护与开发;面对问题衷于也善于求真,探求事物本质。
Part1引言
DPDK(Data Plane Development Kit)是由英特尔,6WIND等多家公司开发,主要基于Linux系统运行,用于快速数据包处理的函数库与驱动集合,可以极大提高数据处理性能和吞吐量,提高数据面应用程序的工作效率。其主要特点和优势有以下几点:
1、 主程序运行在用户态,程序宕掉,不会影响系统崩溃,除非把内存都写坏;
2、 报文收取方面,通过DMA加寄存器的使用实现了报文零拷贝;使用轮询代替中断;
3、 对于具有多队列特性的网卡,可配置RSS功能,将不同队列绑定到不同的CPU核,进而完成报文收取的高效性;
4、 内存管理方面,有一套完整的内存池API,避免程序频繁的malloc与free导致内存产生大量碎片;
5、 TLB方面,通过使用大页表(一般的页表为2K/4K,DPDK使用2M大页表)来减少TLB miss以提升性能;
6、 常见的报文处理模型有pipeline和RTC(Run to Complite)两种,在多核情况下,使用报文批处理的技术时,势必会用到报文队列;DPDK提供了一套无锁队列(rte_ring)来提高报文的入队和出队的性能;
7、 报文结构体mbuf经过精心设计,使其常用数据在同一个cache line不跨行,维持cache的热度;且mbuf头部预留128字节(DPDK默认值,用户可自己修改)供用户自定义并使用;
8、 Cache方面,有预取API(rte_prefetch0)来提高/维持cache热度;数据结构体方面提供了__rte_cache_aligned将数据结构体进行cache line对其,避免在多核编程情况下,使用全局时,发生cache一致性问题导致CPU利用率不高问题;
9、 针对网络开发(路由、防火墙、边缘网关等)DPDK还拥有ACL、Flow、LPM(最长前缀匹配)等一系列组件,加速了软件开发实现;若追求完美,自己实现也是很nice的。
Part2源起
本文中主要讲述数据结构体cache line对齐对性能的影响。
写之前,在这里先给大伙拜个晚到的新年快乐,祝福各位在2022这个虎年,虎虎生威、升职加薪、万事如意。
作为小老弟的我,从去年年底(大概是11、12份左右),一时兴起决定使用开源的数据平面套件DPDK以及开源的quagga中的vtysh来实现自己的一个小小的防火墙软件,底层操作系统选用的是Centos7.2_1511 minimal这个发行版本。初生牛犊不怕虎,在公司内部使用了将近9个月DPDK,也算是有那么一些肤浅的认识,以及一些其他算法、报文处理流程上的开发经验,就直接开始上手干了,一天一天码一点,蜗牛式行动;这两天完成了最小的报文转发系统,较为完整的CLI命令行。
就在前些天,遇到了这么个事,事情经过大概如下:个人码好了最小的报文转发系统,兴致勃勃的使用IXIA Network打流仪器和设备,来进行测试下当前性能。
当时测试的时候,采用的配置是:分配一个核用于报文收发、两个核用于处理报文路由查询和邻居表查询,预期结果是:一对10GE接口、64字节能够达到线速的30%。
但是,就是这个但是,实际测试结果呢,很是让我伤心,一开始只有可怜的11.25%,使用Intel Vtue软件定位分析后,性能能够到13.75%了,这个和自己心中的目标相差甚远。当时使用了perf top查看了下cache利用率以及IPC数值,结果如下:
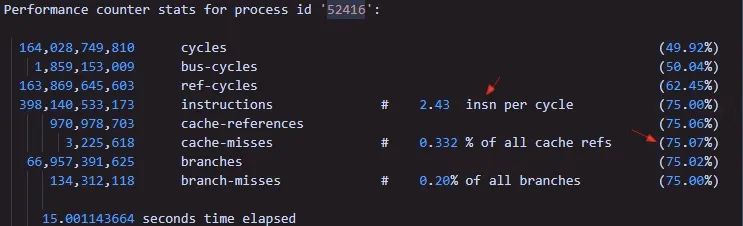
一看Cache-misses75%,心中凉凉,IPC(insn per cycle)为2.43。CPU配置是:
CPU MHz: 2194.839
BogoMIPS: 4389.67
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 14080K
NUMA node0 CPU(s): 0-19
后来,又在忙里偷闲,折腾折腾,发现当时测试有个问题,那就是数据处理核虽然分配的是两个核,但是实际只使用了一个核在进行数据处理(使用的命令是perf top -C cpuid),找了一下问题在哪里呢?
我再将报文收取上来后,使用hash.rss % 数据转发核,将其报文分配到不同的数据转发核对应Packet Ring中,但是呢,hash.rss一直未0;继续找原因发现接口的RSS功能我根本就没有开启。此时,心中甚是欢喜,想着一个核能达到13.75%了,两个也就能够直接到27%了,后面在继续调整调整,增加cache命中率啥的,性能也就差不多能到30%了,没有再继续深入探究了,毕竟还有一个更重要的流程ACL功能未开发。
Part3追寻
有了这次经验,突然想起,做性能调优,通常都需要对代码进行打桩,我为何不在代码中进行打桩统计一些CPU利用率呢?比如,之前测试,我已经完成了CPU利用率打桩代码,通过CLI类似于show lcore utili的命令来查看没有个逻辑核的CPU利用率,也就能更早的发现问题了。所以接下里的闲暇时光里,就来完成打桩代码的测试。这里先抛个砖,开发人员一般都会很忌讳进行增设统计值相关的代码,因为这个写的不好会造成很大的性能损耗,然而这事今天被我遇上了。
为了实现CPU利用率打桩代码,我基本的思路是这样的:统计一个周期内,空闲时间和正常报文被处理的时间,使用 execute time * 100 / (exexcute time + idle time)完成CPU利用率的粗略计算,所以很快的在代码中写下入了如下的代码:
typedef struct cpu_stats_s {
time_t sum_idle;
time_t sum_exec;
uint16_t utili;
uint16_t lcore;
uint16_t lcore_role;
} cpu_stats_t, *pcpu_stats_t;
cpu_stats_t gcpu_stat[MAX_LCORE];
在报文收发或者处理(路由查找、邻接查找)中写下了如下结构:
uint64_t st_tm = rte_rdtsc();
if (空闲)
gcpu_stat[lcore_id].sum_idle = rte_rdtsc() – st_tm;
else {
…报文处理流程
gcpu_stat[lcore_id].sum_exec = rte_rdtsc() – st_tm;
}
再在非DPDK绑定的核或者叫做DPDK的master-lcore上启动一个线程每个2秒,计算出每个lcore cpu的使用率。
同时也将CLI命令:show lcore utili命令编写完成,就在自己家中验证。搭建了一个简单的拓扑(本地环境很简陋):
使用命令:sar -n DEV 1可以看到发送速率在350pps单向。
2、 在淘宝上买了一个硬件盒子,J4125 + I211网卡(千兆)
将编写好的程序放上去,开始打流,再使用perf工具,执行如下命令:
perf stat -e cycles,bus-cycles,ref-cycles,instructions,cache-references, cache misses,branches,branch-misses -p 4978 sleep 15
结果如下:
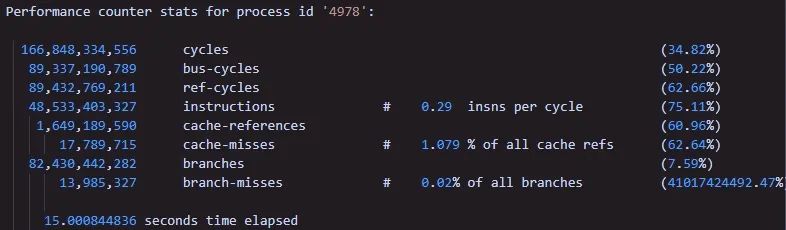
当我看到了,insns per cycle 为0.29时,心中有些不安。我再次使用以前的程序,为带有CPU利用率打桩代码,测试结果如下:
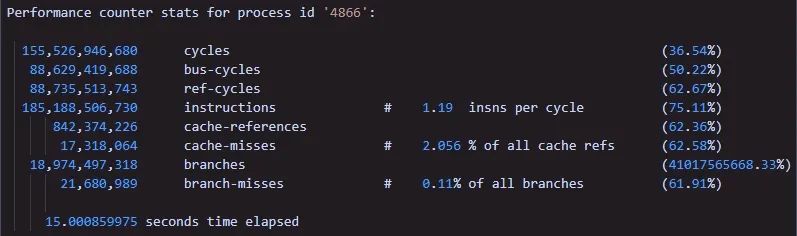
这个差距不是一点点。然后,我继续查找了相关资料,想了解下insns per cycle的含义。
参考:https://blog.csdn.net/witsmakemen/article/details/17715775?_t_t_t=0.45848739612847567
文中解释说道:
instructions:任务执行期间产生的处理器指令数,IPC(instructions perf cycle)IPC是评价处理器与应用程序性能的重要指标。(很多指令需要多个处理周期才能执行完毕),IPC越大越好,说明程序充分利用了处理器的特征。
心中一颤,我叉嘞,我写的啥玩意儿哇,这么多年,还是没长进。又继续想想怎么改进呢,不能因为就这个CPU利用率打桩代码就废了性能哇(毕竟这种非功能性需求还是非常有必要存在的)。
于是心中新生一计“良策”,CPU利用率的精度我降低点,不用那么高,将cycle统计改为统计进入空闲流程的次数。代码大致结构如下:
if (空闲)
gcpu_stat[lcore_id].sum_idle += 1;
else {
…报文处理流程
gcpu_stat[lcore_id].sum_exec += 1; //这里加1也可改为批量处理的报文个数
// gcpu_stat[lcore_id].sum_exec += 64;
}
然后又将其,部署到设备上进行验证,测试结果如下:
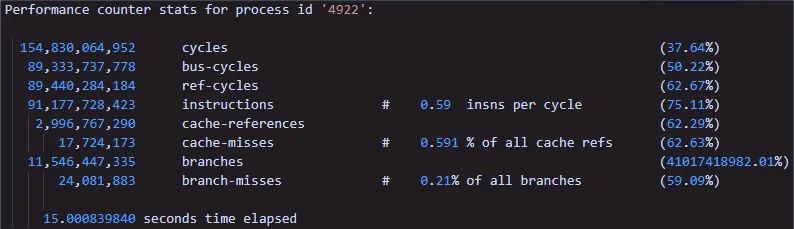
此时,insns per cycle已经来到了0.59了,相比于之前的0.29还是增加了不少,将近一倍了,毕竟之前的每次轮询里面都调用了两次rte_rdtsc()函数(这个函数再高效也经不起我这么小闹腾哇),但是离1.19还是有一倍的差距。就继续胡思乱想,反正就是自己的做小玩意儿,多折腾折腾,看看自己到底能多少能耐,能想到哪一层。
一直在基于DPDK做开发的都知道,DPDK提供了一些原子操作rte_atomic64_init、rte_atomic64_inc等相关API接口,用来提升类似自增操作的性能的。于是,我火速将以前的自增操作或为rte_atomic64_XX相关API,期待性能有提升(IPC值增加)。结果:
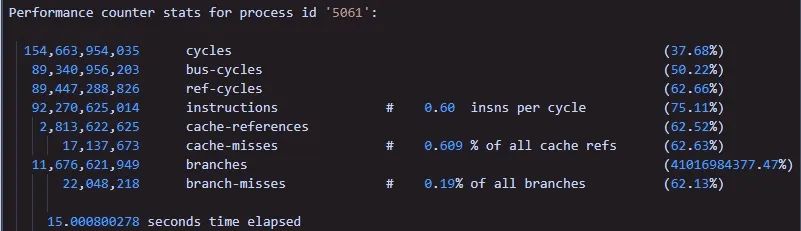
很明显事与愿违,不是预期的结果能,IPC值,几乎没啥变化。
Part4柳暗花明又一村
此时已经是下午3点多了,上床躺会儿…休息休息再战。
其实吧,没咋睡着,脑袋停不下来了。之前呢,也也一直再看增加cache命中率的一些博客或技术文档和一些提升cache命中率的代码级手段。比如说:字节对齐之类的技术,以及依稀记得常常举的计算二维数组累积和的问题:基于按行进行二维数组累积和的性能优于基于按列进行二维数组累积和。因为,假定一位含有16个4字节的元素,在64位系统下,一个cache line刚好为64字节;因此,基于按行计算优于基于按列计算,cache命中率更高,更少的数据cache换入换出。
注意:假定设定变量int array[4][16],在计算第一行时,sum += array[0][0 … 15],计算机怎么就自动将后15个元素自动加载到了cache line了呢?但是呢,实时确认如此,就是“自动”加载到了和array[0]同一个cache line了(这一点我也一直没想明白,先跳过)。
基于这个思路,回头再来看看,我改过编写的数据结构体和全局变量的定义:
typedef struct cpu_stats_s {
time_t sum_idle;// 8 字节
time_t sum_exec;// 8字节
uint16_t utili;// 2字节
uint16_t lcore; // 2字节
uint16_t lcore_role; //2字节,总24字节
} cpu_stats_t, *pcpu_stats_t;
cpu_stats_t gcpu_stat[MAX_LCORE];
假定,报文收取与发送的CPU为1核,报文处理核为2,3。
在CPU 1计算CPU使用率时,访问gcpu_stat[1]时,参数刚刚讲的数组那个问题,同时是不是也会把gcpu_stat[2]的数据加载更新到CPU1核的cache缓存(L2/L1)中;又如,CPU2在访问gcpu_stat[2]计算时,是不是又要将gcpu_stat[3]加载至CPU2的cache缓存中;CPU 2计算更新gcpu_stat[2]后,由于其又存在CPU 1,为了cache的一致性是不是又要去刷新CPU1中的cache,这里涉及到Cache一致性问题了,我这里没有完全的说明cache一致性问题。
但是基于这个思路,萌生的想法就是:把数据结构体cpu_stats_t空间填充到结构体大小为64字节。代码如下:
typedef struct cpu_stats_s {
time_t sum_idle;// 8 字节
time_t sum_exec;// 8字节
uint16_t utili;// 2字节
uint16_t lcore; // 2字节
uint16_t lcore_role; //2字节
uint16_t reserver; // 2字节,总24字节
uint64_t rarray[5]; 40 字节
} cpu_stats_t, *pcpu_stats_t;
继续,将程序部署到设备上,进行验证,结果如下:
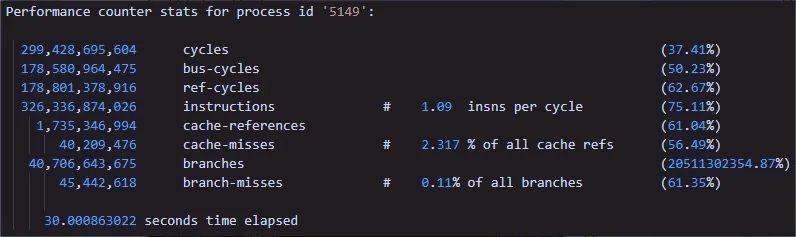
此时,嘴角微微上翘,IPC值来到了1.09距离1.19相差0.1,心中慢慢的放松下来了。
总结这次经验就是,在如下条件:
1、 全局数组,元素类型为结构体时
2、 每个核操作一个数组元素
我们需要保持该结构体数据cache line对齐,在DPDK编程中,处理我们自己进行结构体填充外,是否还有别的方法,毕竟自己填充太麻烦了,还要去计算需要填充多少字节。
我们需要了解Cache Line对齐和Cache一致性,将这些非常抽象的概念具体化,然后在实际使用,在对数据结构设计时多加考虑这些问题。
其实在DPDK中有这么一个宏:__rte_cache_aligned 来标记结构体按cache行对齐。最后,数据结构体如下:
typedef struct cpu_stats_s {
time_t sum_idle;// 8 字节
time_t sum_exec;// 8字节
uint16_t utili;// 2字节
uint16_t lcore; // 2字节
uint16_t lcore_role; //2字节
uint16_t reserver; // 2字节,总24字节
uint64_t rarray[5]; 40 字节
} cpu_stats_t, *pcpu_stats_t __rte_cache_aligned;
验证结果,IPC和之前手动填充的结构体略多0.02左右的。
Part5回眸Cache与Cache一致性
简而言之,缓存是缓冲内存访问的地方,并且可能拥有您请求的数据的副本。通常人们认为缓存(可能不止一个)是堆叠的;CPU 位于顶部,然后是一层或多层缓存,然后是主内存。在此层次结构中,缓存按其级别进行量化。离CPU最近的缓存称为一级缓存,简称L1,缓存逐级递增,直到到达主存。
Cache具有三种操作模式:回写(write back)、直写(write through)和直通(passthrough)(这里不具体解释)。
对于一个特定的缓存可以是直写或回写。直写意味着缓存可以存储数据的副本,但写入必须在下一层完成,然后才能向上一层发出完成信号。回写意味着一旦数据存储在缓存中,就可以认为写入完成。对于回写缓存,只要写入的数据没有被传输,缓存行就被认为是脏的,因为它最终必须被写出到下面的级别。
那么缓存的基本问题之一便是:cache一致性问题。当行中的数据与存储在被缓存的主存储器中的数据相同时,缓存行被称为一致的。如果不是这样,则高速缓存行被称为不连贯。缺乏连贯性会导致两个特殊问题。
1、缺乏连贯性
第一个问题是所有缓存都可能出现的问题,即陈旧数据。在这种情况下,主内存中的数据已更改,但尚未更新缓存以反映更改。这通常表现为不正确的读取,如图 1 所示。这是一个暂时性错误,因为正确的数据位于主存储器中;只需要告诉缓存将其带入即可。
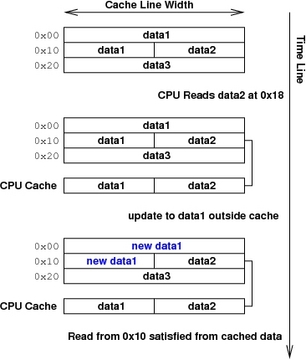
图 1
第二个问题只发生在回写缓存中,它会导致数据的实际破坏,而且更加隐蔽。如图 2 所示,内存中的数据已更改,并且它也已通过 CPU 写入缓存单独更改。因为缓存必须一次写出一行,所以现在无法协调更改——要么必须清除缓存行而不写入,丢失 CPU 的更改,要么必须写出行,从而丢失更改做主内存。所有程序员都必须避免达到数据破坏不可避免的地步;他们可以通过明智地使用各种缓存管理 API 来做到这一点。

图 2
2、缓存行干扰
Part6参考链接
1、 https://blog.csdn.net/witsmakemen/article/details/17715775?_t_t_t=0.45848739612847567
2、 https://www.linuxjournal.com/article/7105
3、 https://www.kernel.org/doc/html/latest/admin-guide/device-mapper/cache.html
