
AI 芯片
2021年6月底,中国科学院计算所研究员包云岗在首届 RISC-V 中国峰会上发布了国产开源高性能 RISC-V 处理器核心——香山,受到了广泛关注。
香山是由中科院计算所、鹏城实验室支持,通过中国开放指令生态(RISC-V)联盟联合业界企业一起开发的一款开源高性能 RISC-V 处理器核。它的架构代号以湖命名,第一代为“雁栖湖”,第二代为“南湖”。原先,“雁栖湖”计划于去年7月流片,但受到全球芯片产能的影响,研发受阻,结果迟迟未出,香山也逐渐退出大众视野。
但就在元宵节,香山项目的主要负责人包云岗教授宣布香山芯片调试目标达成!并在知乎上写下了调试背后的曲折故事。

AI热点
原文:
https://mp.weixin.qq.com/s/Ez97rardlNOckLg_tRj-bw
2021年ML和NLP依然发展迅速,DeepMind科学家最近总结了过去一年的十五项亮点研究方向。主要包括:
Universal Models 通用模型
Massive Multi-task Learning 大规模多任务学习
Beyond the Transformer 超越Transformer的方法
Prompting 提示
Efficient Methods 高效方法
Benchmarking 基准测试
Conditional Image Generation 条件性图像生成
ML for Science 用于科学的机器学习
Program Synthesis 程序合成
Bias 偏见
Retrieval Augmentation 检索增强
Token-free Models 无Token模型
Temporal Adaptation 时序适应性
The Importance of Data 数据的重要性
Meta-learning 元学习
以通用模型为例,通用人工智能一直是AI从业者的目标,越通用的能力,代表模型更强大。2021年,预训练模型的体积越来越大,越来越通用,之后微调一下就可以适配到各种不同的应用场景。这种预训练-微调已经成了机器学习研究中的新范式。在计算机视觉领域,尽管有监督的预训练模型如Vision Transformer的规模逐渐扩大,但只要数据量够大,在自监督情况下预训练模型效果已经可以和有监督相匹敌了。
总之,预训练的模型已经被证明可以很好地推广到特定领域或模式的新任务中。它们表现出强大的few-shot learning和robust learning的能力。因此,这项研究的进展是非常有价值的,并能实现新的现实应用。
对于下一步的发展,研究人员认为将在未来看到更多、甚至更大的预训练模型的开发。同时,我们应该期待单个模型在同一时间执行更多的任务。在语言方面已经是这样了,模型可以通过将它们框定在一个共同的文本到文本的格式中来执行许多任务。同样地,我们将可能看到图像和语音模型可以在一个模型中执行许多共同的任务。

原文:
https://mp.weixin.qq.com/s/93uzg4Kt4vsnzcMaq8rguA
据美国 IT 网站 The Register 报道,英特尔将开放 x86 架构的软核和硬核授权,使客户能够在英特尔制造的定制设计芯片中混合 x86、Arm 和 RISC-V 等不同的 CPU IP 核。
英特尔代工服务事业部(IFS)客户解决方案工程副总裁Bob Brennan 表示,英特尔拥有所谓多ISA 战略,促成英特尔史上第一次授权想开发芯片的客户x86 软核心和硬核心。他解释所谓软核心是可在可程式化逻辑(如FPGA)或正在设计的特定应用芯片CPU 核心,硬核心是客制化芯片基于半导体技术的物理设计,有性能保证,提供用户的形式是电路物理结构架构和一套完整技术内容,可直接用来实现芯片制造。简单说,软核心对原型设计和特殊情况很有用,硬核心则对想制作量产芯片时最有效率。
英特尔尚未公开会以何种形式、何种收费,对哪种类型客户开放哪些x86 核心授权。不过这是为了推动英特尔代工业务,想取得英特尔x86 核心授权,应需将芯片交由英特尔代工。Bob Brennan 举例,客户能使用获许可的Xeon 核心架构芯片,并与基于RISC-V 规范或Arm IP 的AI加速器结合。
从Bob Brennan 举例看,英特尔开放x86 核心授权,幅度可能较大,如果Xeon 核心都愿意授权,那大部分x86 CPU 核心都有可能开放。但可想而知,英特尔可能不会开放最新x86 核心IP,应会与授权x86 核心保持一两代以上差距。且不会谁给钱就授权,应有限制条件,不然可能对英特尔自家CPU 销售造成大影响。毕竟英特尔不可能放弃CPU 业务转做x86 核心IP 研发和授权,发展晶圆代工业务,以避免和客户竞争。

AI前沿
原文:
https://mp.weixin.qq.com/s/r72DXP9dKHtJLdWb92B2sg
论文:
https://www.nature.com/articles/s42256-021-00427-7
视网膜的微小血管或眼睛后部的细微变化可以显示出一个人可能有心脏病发作的迹象,这使得人工智能有了用武之地。
这项研究发表在Nature Machine Intelligence,题目就叫「通过视网膜扫描和最少的个人信息来预测心肌梗死」
心脏是血液循环的核心,心脏出问题,必然会导致血液循环问题,血液循环问题又会导致视网膜细胞受损并死亡,留下永久性的印记。
利兹大学的研究人员就通过这一原理推进了这项AI通过视网膜识别一年内有心脏病发作的患者,准确率高达80% 。来自约克、中国、法国、美国和比利时的科学家也参与了这项研究。

原文:
https://mp.weixin.qq.com/s/r9KdNCw1U3ql58Xx4fW5Gg
论文:
https://openreview.net/forum?id=DmpCfq6Mg39
ICLR2022前段时间已经放榜,涌现了大量优秀的工作。笔者在浏览时偶然发现一篇关于动态卷积的文章ODConv(Omni-dimensional Dynamic Convolution, ODConv),Intel实验室姚安邦:https://yaoanbang.github.io/团队的工作。作为一种“即插即用”的操作,还是非常值得一读的,故做记录以飨各位。
动态卷积这几年研究的非常多了,比较知名的有谷歌的CondConv,旷视科技的WeightNet、MSRA的DynamicConv、华为的DyNet、商汤的CARAFE等。笔者曾经也对相关paper进行过解读,各个动态卷积之间的差异性也曾进行深入分析。
一定程度上讲,ODConv可以视作CondConv的延续,将CondConv中一个维度上的动态特性进行了扩展,同时了考虑了空域、输入通道、输出通道等维度上的动态性,故称之为全维度动态卷积。ODConv通过并行策略采用多维注意力机制沿核空间的四个维度学习互补性注意力。作为一种“即插即用”的操作,它可以轻易的嵌入到现有CNN网络中。ImageNet分类与COCO检测任务上的实验验证了所提ODConv的优异性:即可提升大模型的性能,又可提升轻量型模型的性能,实乃万金油是也!值得一提的是,受益于其改进的特征提取能力,ODConv搭配一个卷积核时仍可取得与现有多核动态卷积相当甚至更优的性能。

原文:
https://mp.weixin.qq.com/s/wPWV6kxkRlYb9dMf6ADWkQ
论文:
https://www.nature.com/articles/s41586-021-04301-9
可控核聚变、强人工智能、脑机接口是人类科技发展的几个重要方向,有关它们何时可以实现,科学家们的说法永远是「还需几十年」——面临的挑战太多,手头的方法却很有限。
那么用人工智能去控制核聚变,是不是一个有前途的方向?这个问题可能需要由提出 AlphaGo 的 DeepMind 来回答了。
最近,EPFL 和 DeepMind 使用深度强化学习控制托卡马克装置等离子体的研究登上了《自然》杂志。
Ambrogio Fasoli 认为,与 DeepMind 的合作可以让研究人员突破界限,加速通往聚变能量的漫长旅程。人工智能将赋能我们探索人类无法探索的东西,因为我们可以使用自己不敢冒险的控制系统来达到目标。「如果我们确定自己有一个控制系统,让我们接近极限但不会超出极限,则实际上可以用来探索那些不存在的可能性。

AI 开源项目
原文:
https://mp.weixin.qq.com/s/vCoMJBAHdv9nlQLqv7I_Zw
Github:https://ramdrop.github.io/assets/pages/AutoPlace/AutoPlace_customized.html
场景识别是许多机器自主任务的基础,比如回环检测和尺度定位。一般的场景识别系统使用视觉相机或者激光雷达来实现,但它们在黑暗、恶劣天气以及其他视线不佳的情况下性能会极大降低。机械毫米波雷达(如CTS-350X)可以应对一些恶劣工况,但是它体积大、成本高且必须安装在车顶,这使得难以被大规模商用。车载单片毫米波雷达是近年来新出现的商用环境感知传感器,它体积小、成本低,采集信号种类丰富(包括多谱勒速度和RCS)。但是车载单片毫米波雷达的点云稀疏又嘈杂,如何将其良好应用于场景识别是一个尚未解决的挑战。
本工作提出一套针对车载单片毫米波雷达的场景识别方法,我们称之为AutoPlace。AutoPlace挖掘车载单片毫米波雷达的Doppler Velocity和RCS两种测量物理信号,并使用深度学习网络提取点云的时间和空间信息,为每一帧点云生成一个具有强区分度的全局描述子。

原文:
https://mp.weixin.qq.com/s/PbKYy8iclKk_rGNn1LoQ0A
Github:
https://github.com/bilibili/ailab/tree/main/Real-CUGAN
最近,GitHub 上一个图像超分辨率的项目火了,一个叫做 Real-CUGAN 的工具可以把动画图像的质量提升 2 到 4 倍,qq 上斗图的表情包也能给你脑补成 4k 品质。
据作者介绍,Real-CUGAN 是一个使用百万级动漫数据进行训练的,结构与 Waifu2x 兼容的通用动漫图像超分辨率模型。相比目前市面上已有的通用化超分辨率算法,Real-CUGAN 的 AI 模型经过了更大体量数据集的训练,处理二次元内容的效果更佳。
它支持 2x\3x\4x 倍超分辨率,其中 2 倍模型支持 4 种降噪强度与保守修复,3 倍 / 4 倍模型支持 2 种降噪强度与保守修复。
Real-CUGAN 全称为 Real Cascaded-U-Net-style Generative Adversarial Networks(真实的、级联 U-Net 风格的生成对抗网络),使用了与 Waifu2x 相同的动漫网络结构,但因为使用了新的训练数据与训练方法,从而形成了不同的参数。

文末干货
原文:
https://mp.weixin.qq.com/s/VBVtxIOdUeLVLKcSWDR19g
知乎视频:
https://www.zhihu.com/zvideo/1373194535481163776
由李沐大神分享关于如何快速阅读和整理文献的相关经验。
本文的主要内容包括:
1、读文献的目的
2、整理论文的技巧和工具
3、工具相关的教程
原文:
https://mp.weixin.qq.com/s/cfqKhwslbX_lD6FXvuqWIA
当我们辛苦收集数据、数据清洗、搭建环境、训练模型、模型评估测试后,终于可以应用到具体场景,但是,突然发现不知道怎么调用自己的模型,更不清楚怎么去部署模型!那么就收藏这篇文章慢慢看!


嵌入式系统解决方案技术研讨会
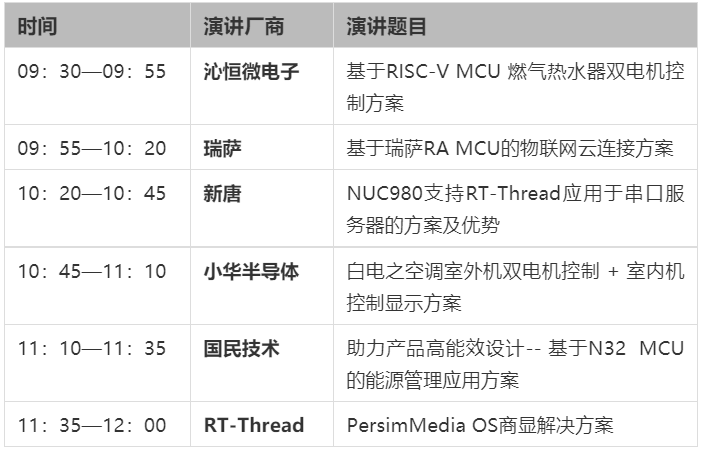




点击 “阅读原文” 进入官网
