


众所周知,GPU出现的最初目的仅仅是为了图像和视频并行处理的加速,但随着OpenCL 和 NVIDIA 的 CUDA 语言和工具链的出现使 GPU 更易于使用,目前已经成为一种通用的并行加速平台。然而,也正是由于GPU是为图像和视频处理这一类应用而做出来的专用ASIC,显然在非具有图像和视频加速处理特点的其它应用场景下(如计算密集型应用),GPU的加速性能也会大打折扣。在这种情况下,FPGA 与 CPU 结合的加速卡模式应运而生了。RIFFA 并不是将 FPGA 集成到传统软件环境中的第一次尝试,也并非唯一的一种架构,但它开源的巨大优势引起了越来越多的关注。如有学者将RIFFA应用于基因测序的加速(https://github.com/BilkentCompGen/GateKeeper),做出目前唯一的成本低廉便携式快速基因测试产品。笔者认为,随着各行各业不同加速应用卸载到网卡等设备的需求越来越多,开源的RIFFA架构必将越来越普及。
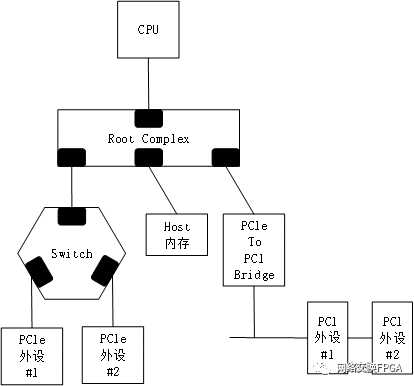
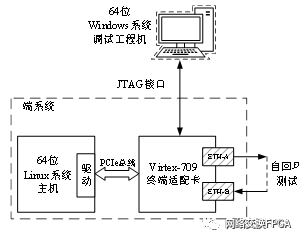
RIFFA 是一种开源通信架构,它允许通过 PCIe 在用户的 FPGA IP 内核和 CPU 的主存储器之间实时交换数据。为了建立其逻辑通道,RIFFA 在 CPU 端拥有一系列软件库,在 FPGA 端拥有 IP 核。本文主要针对其中的DMA性能(Scatter-Gather DMA)进行测试。
RIFFA是一个用于PCIe设备的可重用集成框架,它的原版Github仓库链接如下:https://github.com/KastnerRG/riffa.git
branch的Gitee仓库如下:
https://gitee.com/xu_mingwei/riffa.git
01
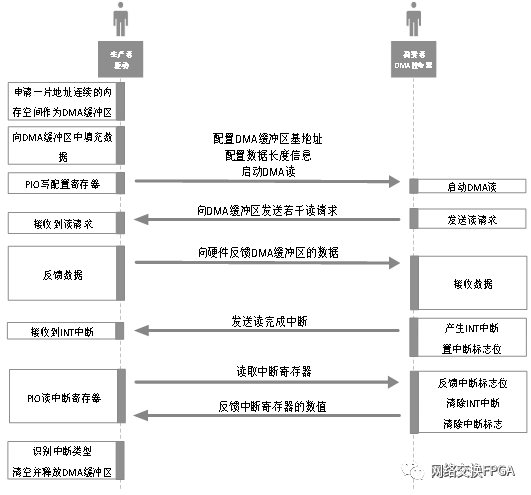
DMA技术相关知识

02
RIFFA架构FPGA模块及驱动说明
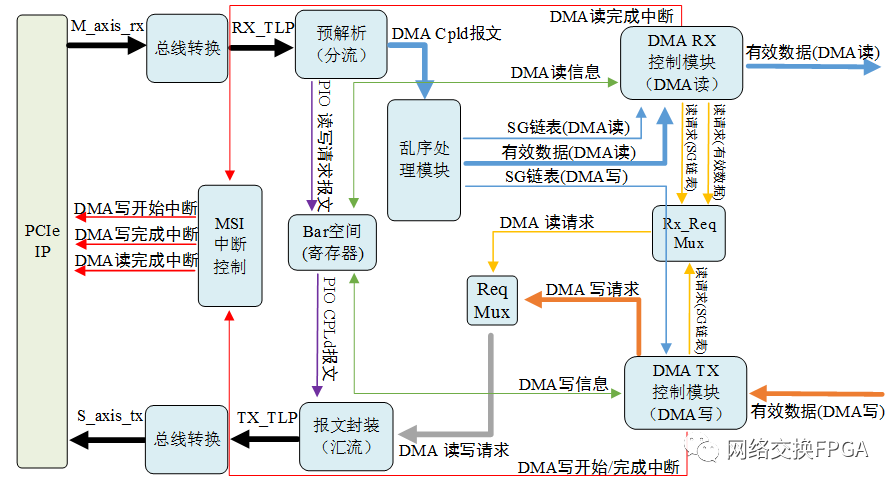
RIFFA的Linux驱动文件夹下有6个C源码文件,riffa_driver.c、riffa_driver.h、circ_queue.c、circ_queue.h、riffa.c、riffa.h。
其中riffa.c和riffa.h不属于驱动源码,它们是系统函数调用驱动封装的一层接口,属于用户应用程序的一部分。
circ_queue.c和circ_queue.h是为在内核中使用而编写的消息队列,用于同步中断和进程;riffa_driver.c和riffa_driver.h是驱动程序的主体。
注意:RIFFA驱动全程采用面向对象的编程思想。
由于篇幅所限,本公众号后续将会给出RIFFA驱动的详细解读。
03
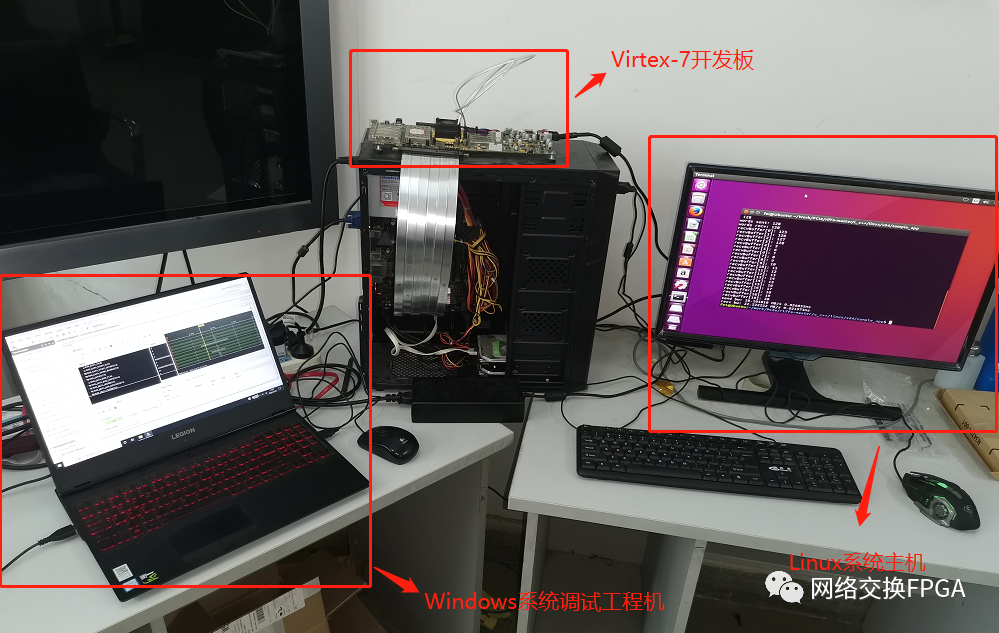
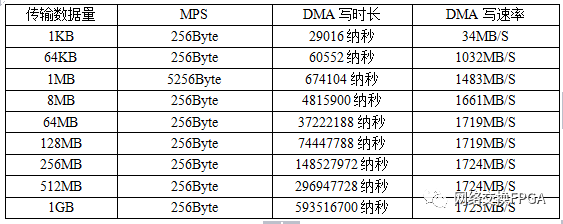
板级测试
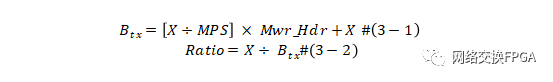
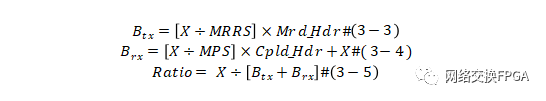




THE END

图文排版:祝钊华
责任编辑:潘伟涛



我知道你
哦


