FPGA得益于其高可编程性以及低延迟,低功耗的特点,在机器学习的推理领域已获得了广泛的关注。在过去,FPGA对于软件开发人员来说有较高的开发门槛,把一部分开发者挡在了门外。如今越来越完善的高阶工具以及软件堆栈使得开发者可以充分利用FPGA优点对关键应用进行加速,同时不需花费时间去了解FPGA的底层实现。
Xilinx Vitis AI 是用于 Xilinx 硬件平台上的 AI 推理的开发堆栈。它由优化的 IP(DPU)、工具、库、模型和示例设计组成,使用Xilinx ZynqMP SOC或者Versal ACAP器件并借助强大的Vitis AI堆栈,已大大降低了FPGA上部署机器学习应用的门槛。
本文将使用Tensorflow 2.0从零搭建并训练一个简单的CNN模型来进行数字手势识别,并部署运行在ZynqMP开发板上,来熟悉Vitis AI的工作流程。
我们首先用Tensorflow 2.0创建模型并针对目标数据集进行训练,然后使用Vitis AI 工具对模型进行量化/编译等处理,获得运行DPU所需要的xmodel文件。最后需要编写调用Vitis AI runtime的主机应用,该应用运行在CPU上,进行必要的预处理/后处理以及对DPU进行调度。
1
Vitis AI环境配置
Vitis AI支持业界通用的Pytorch/Tensorflow/Caffe训练框架。模型创建和训练工作完全在通用框架下进行开发。开始工作之前需要先在Host机器上配置好Vitis-AI Docker环境,这部分完全参考 https://github.com/Xilinx/Vitis-AI Guide 即可。以下所有在Host机器上完成的步骤(训练/量化/编译)都是在Vitis AI docker 及vitis-ai-tensorflow2 conda env环境下完成。
2
数据集
本实例使用的数字手势数据集:
https://github.com/ardamavi/Sign-Language-Digits-Dataset (感谢开源数据集作者Arda Mavi )

3
源码说明
本项目的工程文件保存在 Github目录:
https://github.com/lobster1989/Handsign-digits-classification-on-KV260
有4个主要文件夹:
1. code:
此处包含所有源代码,包括用于训练/量化/编译任务的脚本,以及在 ARM 内核上运行的主机应用程序。
2. output:
生成的模型文件。
3. Sign-Language-Digits-Dataset:
数据集应该下载并放在这里。
4. target_zcu102_zcu104_kv260:
准备复制到目标板运行的文件。
4
创建/训练模型
Host机器上运行 "train.py" 脚本,train.py脚本中包含了模型的创建和训练过程。模型的创建主要代码如下,使用Keras的function式 API(注意sequential 式API目前Vitis AI不支持)。创建的模型包含4个连续的Conv2D+Maxpolling层,然后跟随一个flatten layer, 一个dropout layer,以及两个全连接层。
这个模型仅仅作为示例,各位也可以尝试使用其它的CNN模型或进行优化。
# Function: create a custom CNN model
def customcnn():
inputs = keras.Input(shape=image_shape)
x = layers.Conv2D(32, (3,3), activation='relu', input_shape=image_shape)(inputs)
x = layers.MaxPooling2D((2,2))(x)
x = layers.Conv2D(64, (3,3), activation='relu')(x)
x = layers.MaxPooling2D((2,2))(x)
x = layers.Conv2D(128, (3,3), activation='relu')(x)
x = layers.MaxPooling2D((2,2))(x)
x = layers.Conv2D(128, (3,3), activation='relu')(x)
x = layers.MaxPooling2D((2,2))(x)
x = layers.Flatten()(x)
x = layers.Dropout(0.5)(x)
x = layers.Dense(512, activation='relu')(x)
outputs = layers.Dense(10, activation='softmax')(x)
model = keras.Model(inputs=inputs, outputs=outputs, name='customcnn_model')
model.summary()
# Compile the model
model.compile(optimizer="rmsprop",
loss="categorical_crossentropy",
metrics=['acc']
)
return model
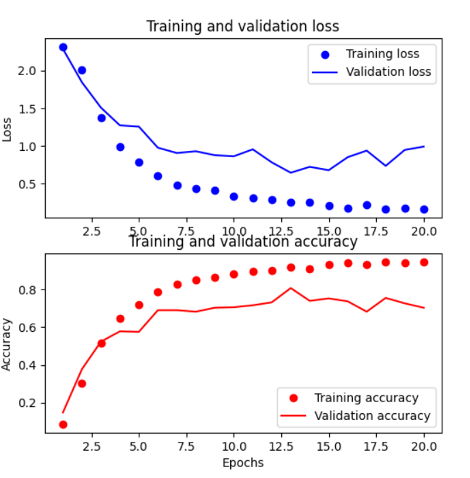
该模型在第 10 个epoch在验证数据集上获得了 0.7682 的精确度。
5
模型量化
训练完Tensorflow2.0模型后,下一步是使用Vitis AI quantizer工具对模型进行量化。量化过程将 32 位浮点权重转换为 8 位整型 (INT8),定点模型需要更少的内存带宽,从而提供更快的速度和更高的运行效率。如果需要进一步优化计算量级,还可以使用Vitis AI提供的剪枝(pruning)工具。
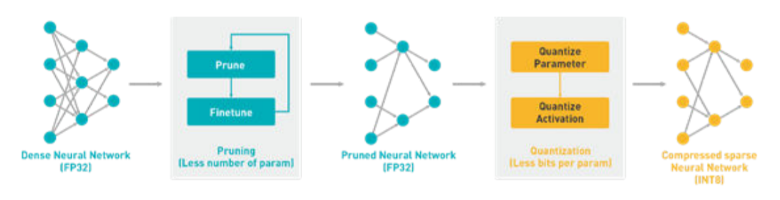
运行quantize.py脚本进行量化,运行结束后将生成量化后的模型''quantized_model.h5''。
进行quantize的代码部分如下,调用VitisQuantizer,需要提供的输入包括上个步骤生成的float模型,以及一部分图片(推荐为100~1000张)作为calibration的输入。Calibration操作使用提供的图片进行正向运算,不需要提供label
# Run quantization
quantizer = vitis_quantize.VitisQuantizer(float_model)
quantized_model = quantizer.quantize_model(
calib_dataset=train_generator
)
6
评估量化后模型
我们可以测试评估下量化后的模型是否有精度的损失。量化模型的评估可以直接在 python 脚本中利用TensorFlow框架完成。读入模型,重新compile, 然后调用evaluation相关 API对模型进行评估。主要代码部分如下
# Load the quantized model
path = os.path.join(MODEL_DIR, QAUNT_MODEL)
with vitis_quantize.quantize_scope():
model = models.load_model(path)
# Compile the model
model.compile(optimizer="rmsprop",
loss="categorical_crossentropy",
metrics=['accuracy']
)
# Evaluate model with test data
loss, acc = model.evaluate(val_generator) # returns loss and metrics
运行“eval_quantize.py”脚本即可完成评估。通过评估发现,量化后的模型没有发生精度损失。当然实际并不总是如此,有时候量化后的模型会有些许精度损失,这和不同的模型有关系。这时候我们可以使用Vitis AI提供finetuning来精调模型 。
7
编译模型
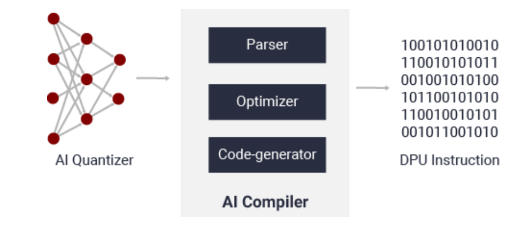
模型的编译需要用到Vitis AI compiler(VAI_C)。这个步骤实际上是把量化后的模型转化为可以在DPU上运行的指令序列。VAI_C 框架的简化流程如下图所示,包含模型解析,优化和代码生成三个阶段。模型解析步骤对模型的拓扑进行解析,生成用Xilinx的中间表示层(Intermediate Representation)表示的计算图(computation graph)。然后是执行一些优化操作,例如计算节点融合或者提高数据重用。最后的步骤是生成DPU架构上运行的指令序列。
运行compile.sh脚本即可完成编译过程。主要代码如下,使用vai_c_tensorflow2命令。注意需要提供目标DPU配置的arch.json文件作为输入(--arch选项)。编译步骤完成后会生成DPU推理用的xmodel文件。
compile() {
vai_c_tensorflow2 \
--model $MODEL \
--arch $ARCH \
--output_dir $OUTDIR \
--net_name $NET_NAME
}
8
主机程序
DPU作为神经网络加速引擎,还需要CPU主机对其进行控制和调度,提供给DPU数据输入/输出。另外还需要对这部分运行在ARM或Host CPU上的应用而言, Vitis AI提供了Vitis AI Runtime (VART) 以及Vitis AI Library来方便应用开发。VART比较底层,提供更大的自由度。Vitis AI library属于高层次API,构建于 VART 之上,通过封装许多高效、高质量的神经网络,提供更易于使用的统一接口。
VART具有C++和Python两套API。多数机器学习开发者习惯用Python来开发和训练模型,在部署阶段甚至可以不用切换语言。本例子中提供了使用Python接口的host程序app_mt.py。使用Python API的简化流程如下。
# Preprocess
dpu_runner = runner.Runner(subgraph,"run")
# Populate input/out tensors
jid = dpu_runner.execute_async(fpgaInput, fpgaOutput)
dpu_runner.wait(jid)
# Post process
9
开发板上运行
如果使用的是 Xilinx zcu102/zcu104/KV260 官方 Vitis AI 启动文件,则3 块板上的 DPU 配置都相同。可以在 3 个平台上运行相同的xmodel文件,主机上的所有步骤完成后,将以下文件复制到目标板上。共需要xmodel文件,主机程序,以及一些用来测试的图片。
启动开发板并运行 app_mt.py ,用 -d指定图片路径,-m指定xmodel文件,-t 指定CPU上运行的线程数。
很幸运,10张测试图片的推理结果都是正确的。
root@xilinx-zcu102-2021_1:/home/petalinux/Target_zcu102_HandSignDigit# python3 app_mt.py -d Examples/ -m customcnn.xmodel
Pre-processing 10 images...
Starting 1 threads...
Throughput=1111.96 fps, total frames = 10, time=0.0090 seconds
Correct:10, Wrong:0, Accuracy:1.0000

