本文来源:陈巍谈芯
随着AI计算、自动驾驶和元宇宙进入行业快车道,全社会巨大的算力需求正在催生新的计算架构。存算一体架构比冯诺依曼架构最大的优势,表现为超高的算力和能效比,是比冯氏架构更适合AI计算的架构。存算技术也被AspenCore预测为2022年的全球半导体行业十大技术趋势。
目前存算技术正处在从学术到工业产品的跃迁的关键时期。包括阿里达摩院最近刚发布的基于SeDRAM的近存计算芯片,就充分展示了存算技术(第一代仅是近存计算)在数据中心场景的算力和能效实力。
 存算一体技术的原理及优势
存算一体技术的原理及优势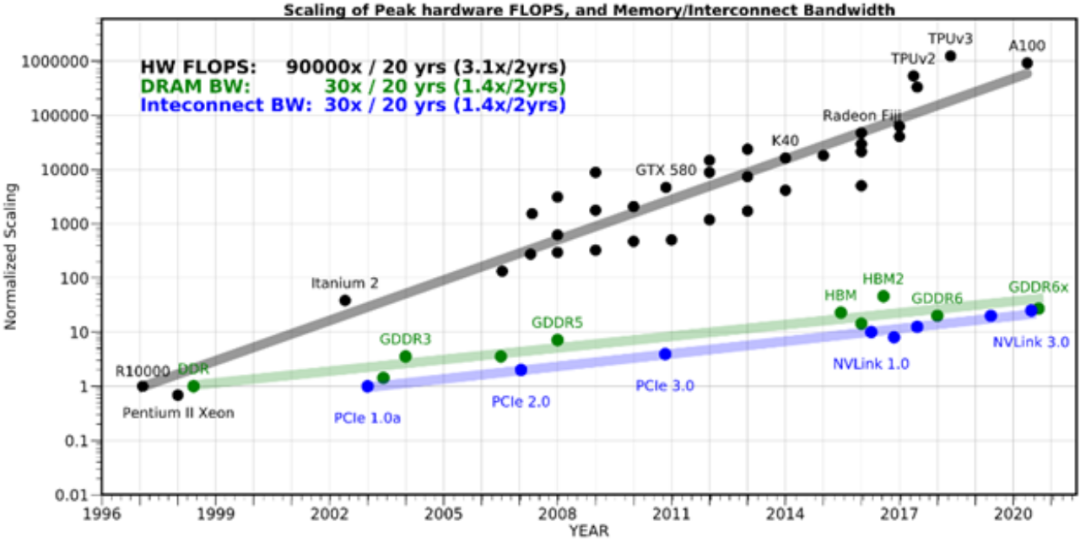
算力发展速度远超存储器(来源:amirgholami@github)
存算一体技术(Computing in Memory,CIM)概念的形成,最早可以追溯到上个世纪90年代。随着近几年云计算和人工智能(AI)应用的发展,面对计算中心的数据洪流,数据搬运慢、搬运能耗大等问题成为了计算的关键瓶颈。从处理单元外的存储器提取数据,搬运时间往往是运算时间的成百上千倍,整个过程的无用能耗大概在60%-90%之间,能效非常低,“存储墙”成为了数据计算应用的一大障碍。深度学习加速的最大挑战就是数据在计算单元和存储单元之间频繁的移动。
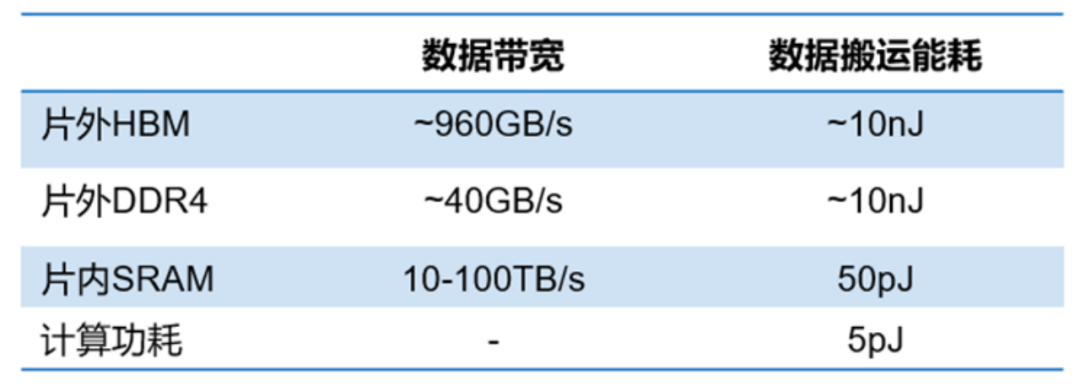
数据搬运占据AI计算的主要能耗
存算一体可理解为在存储器中嵌入计算能力,以新的运算架构进行二维和三维矩阵乘法/加法运算,而不是在传统逻辑运算单元或工艺上优化。这样能从本质上消除不必要的数据搬移的延迟和功耗,成百上千倍的提高AI计算效率,降低成本,打破存储墙。
除了用于AI计算外,存算技术也可用于感存算一体芯片和类脑芯片,代表了未来主流的大数据计算芯片架构。
存算一体技术的分类

存算技术的分类/演进
目前存算技术在按照以下路线在演进:
• 查存计算(Processing With Memory):GPU中对于复杂函数就采用了这种计算方法,是早已落地多年的技术。通过在存储芯片内部查表来完成计算操作。
• 近存计算(Computing Near Memory):典型代表是AMD的Zen系列CPU,技术方案已经比较成熟。计算操作由位于存储区域外部的独立计算芯片/模块完成。这种架构设计的代际设计成本较低,适合传统架构芯片转入。将HBM内存(包括三星的HBM-PIM)与计算模组(裸Die)封装在一起的芯片也属于这一类。
• 存内计算(Computing In Memory):典型代表是Mythic、闪忆、知存、九天睿芯等。计算操作由位于存储芯片/区域内部的独立计算单元完成,存储和计算可以是模拟的也可以是数字的。这种路线一般用于算法固定的场景算法计算。
• 存内逻辑(Logic In Memory):这是较新的存算架构,典型代表包括TSMC(在2021 ISSCC发表)和千芯科技。这种架构数据传输路径最短,同时能满足大模型的计算精度要求。通过在内部存储中添加计算逻辑,直接在内部存储执行数据计算。
PIM-HBM芯片架构
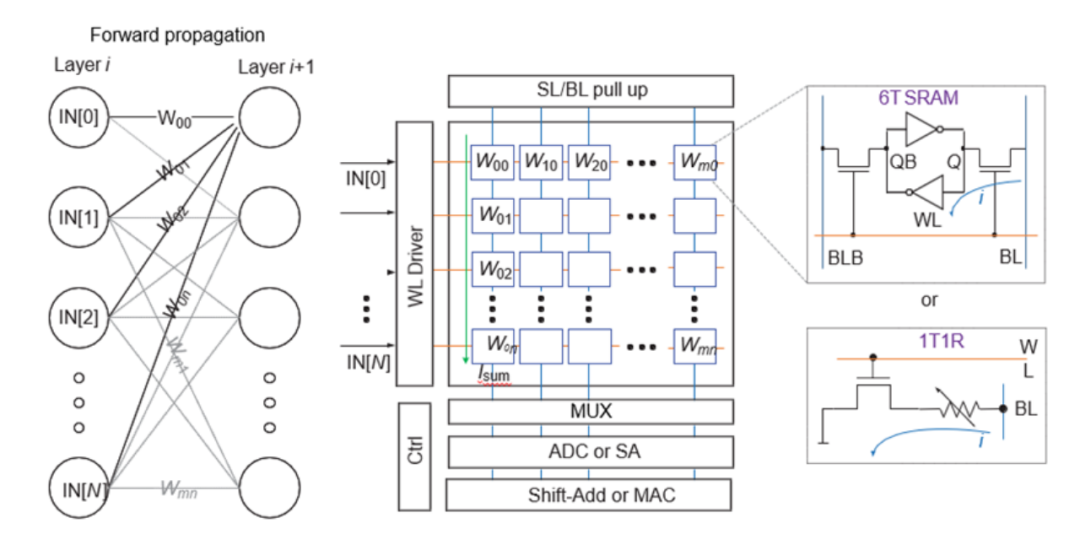
存内计算芯片基本架构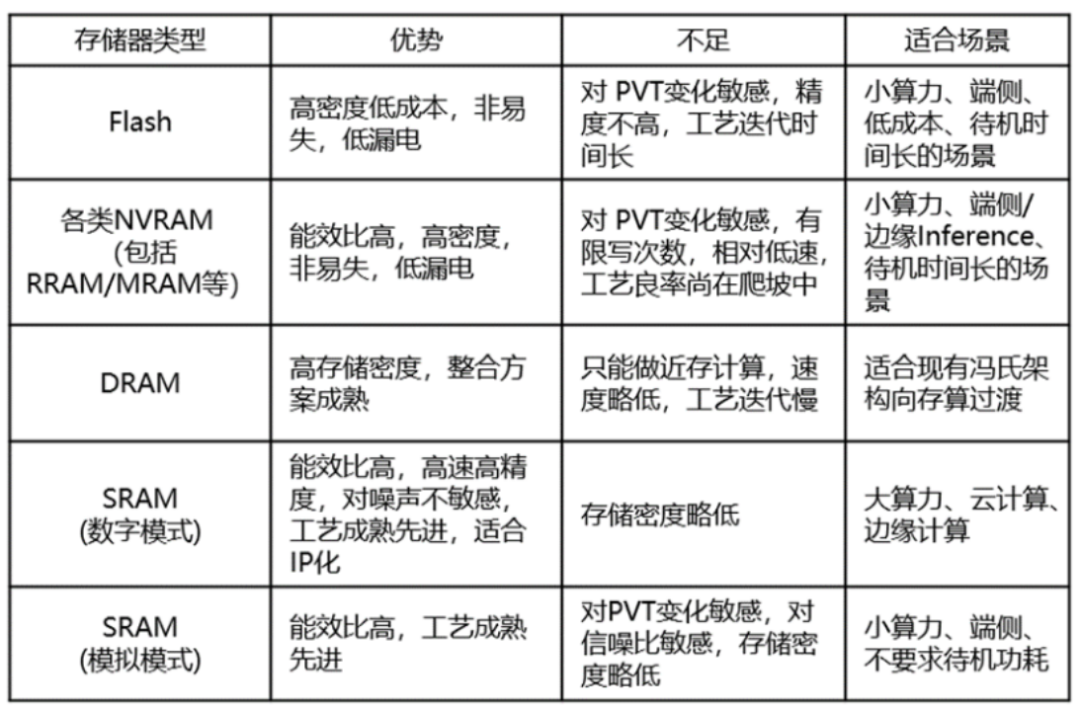
存算一体芯片基本架构
人工智能/深度学习计算中有大量的矩阵乘法计算,其本质是乘累加(Multiply-Accumulate,MAC)运算。存算将计算直接映射到存储结构中,具有最高的能效比和最小的延迟。
如存算一体芯片基本架构图所示,神经网络模型的权重可以映射为子阵列中存储单元的电导率,而输入特征图(Feature map)作为行电压并行加载(图中WL方向),然后以模拟方式进行乘法(即输入电压乘以权重电导),并使用列上的电流求和(图中BL方向)来生成输出向量。
CIM 可以支持多位权重/输入/输出精度。根据存储单元的精度,一个多位权重可能被分成多个存储单元。例如,如果每个单元使用 2 位,则 8 位权重可以由 4 个存储单元表示。
ADC(模数转换器)/SA(灵敏放大器) 之后的输出可经过“移位+加法”以重建跨多列的乘法/加法,以提升计算精度。
存算一体中存储单元的对比
存储单元有不同的适合场景
目前可用于存算一体的成熟工艺存储器有DRAM 、SRAM、Flash。
DRAM成本低,容量大,但是可用的eDRAM IP核工艺节点不先进,读取延迟(Latency)也大,且需要定期刷新数据。Flash则属于非易失性存储器件,具有低成本优势,一般适合小算力场景。SRAM在速度方面具有极大优势,有几乎最高的能效比,容量密度略小,在精度增强后可以保证较高精度,一般适用于云计算等大算力场景。
可用于存算一体新型存储器有PCRAM、MRAM、RRAM和FRAM等。
目前学术界比较关注各种忆阻器(RRAM)在神经网络计算中的引入。RRAM使用电阻调制来实现数据存储,读出电流信号而非传统的电荷信号,可以获得较好的线性电阻特性。但目前RRAM工艺良率爬坡还在进行中,而且依然需要面对非易失存储器固有的可靠性问题,因此目前还主要用于端侧小算力和边缘AI计算。
存算技术的发展趋势
1)提升计算精度
模拟存内计算精度受到信噪比的影响,精度上限在4-8 bit左右,只能做定点数计算,难以实现浮点计算,并不适用于需要高精度的云计算场景和训练场景,适用于对能效比有较高要求而对于精确度有一定容忍的场景。
数字存算技术则不受信噪比的影响,精度可以达到32bit甚至更高,且可支持浮点计算,是云计算场景存算的发展方向。
2)多算法适配
目前大部分存算芯片还是针对特定算法的DSA(Domain Specific Accelerator),因此当客户算法需求改变时,就很难做到算法的迁移和适配。这使得一款存算芯片可能只能适配优先的细分市场,难以形成较大的销量。特别是在端侧市场,这一现象明显。
为了解决多算法适配的问题,目前产业界开始使用可编程或可重构的技术来扩展存算架构的支持能力。其中可重构存算的能效比高于可编程存算的能效比,具有更强的发展潜力。
3)存算/数据流编译器的适配
存算一体芯片产业化处于起步阶段,目前仍面临编译器的支持不足的问题。
目前大部分存算芯片采取DSA的方式进行落地,以规避通用编译器的适配问题。
但随着存算技术的高速发展和落地,对应的编译器技术也在快速进步。
存算技术在海量数据计算场景中拥有天然的优势,将在云计算、自动驾驶、元宇宙等场景拥有广阔的发展空间。
目前存算技术正处在从学术领域到工业产品落地的关键时期,随着存算技术的不断进步和应用场景的不断催生,预计存算一体技术将成为AI计算领域的主要架构。
*声明:本文系原作者创作。文章内容系其个人观点,我方转载仅为分享与讨论,不代表我方赞成或认同,如有异议,请联系后台。