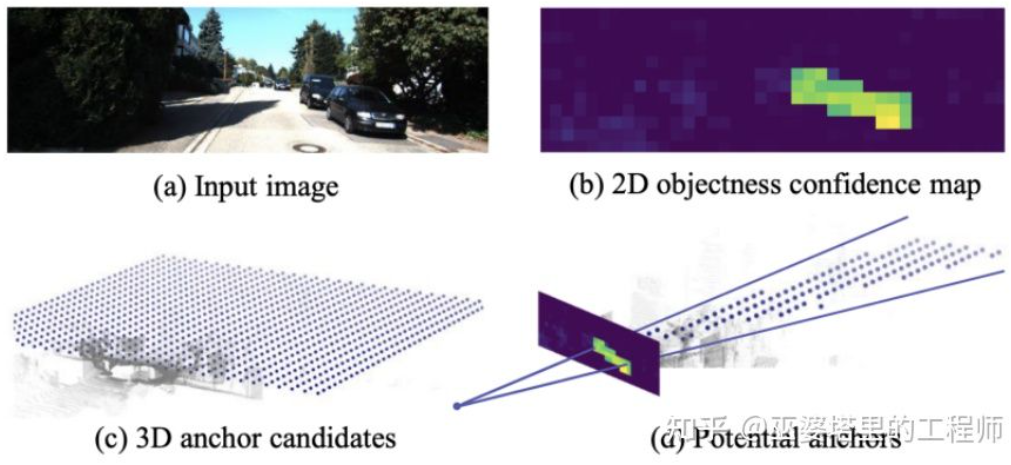
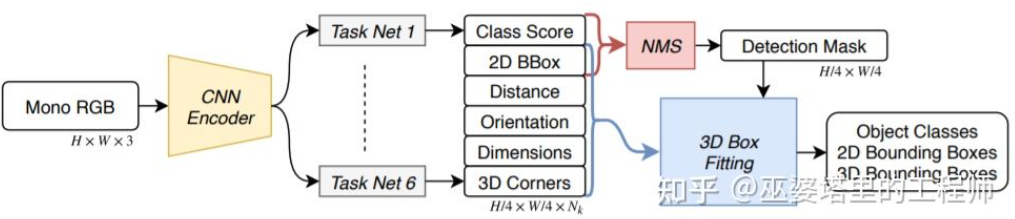
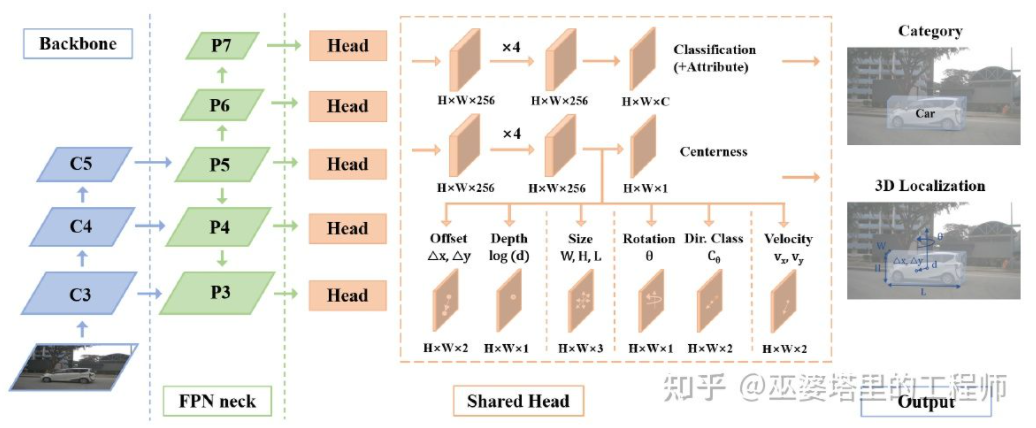
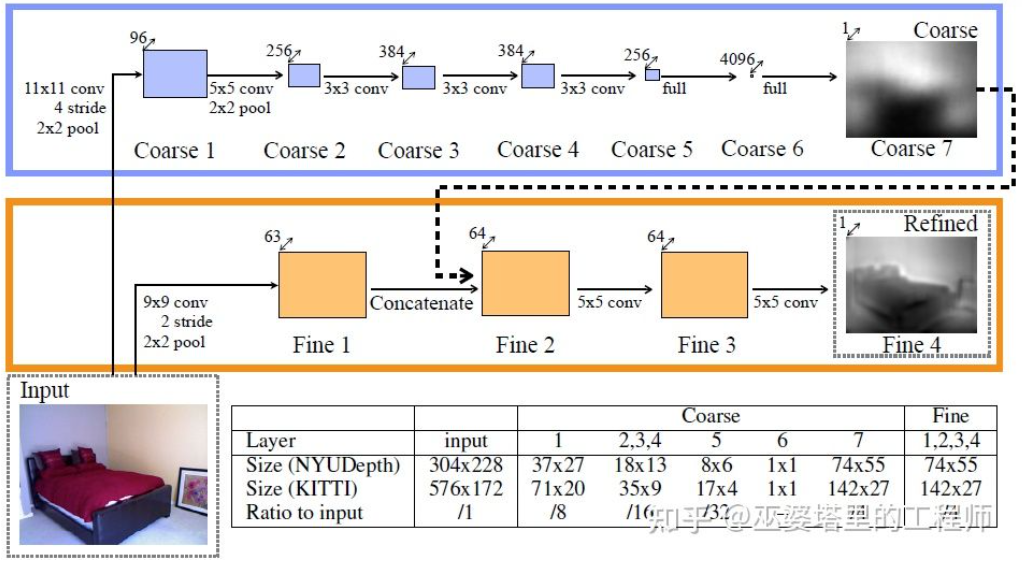
全球知名半导体制造商ROHM Co., Ltd.(以下简称“罗姆”)宣布与Taiwan Semiconductor Manufacturing Company Limited(以下简称“台积公司”)就车载氮化镓功率器件的开发和量产事宜建立战略合作伙伴关系。通过该合作关系,双方将致力于将罗姆的氮化镓器件开发技术与台积公司业界先进的GaN-on-Silicon工艺技术优势结合起来,满足市场对高耐压和高频特性优异的功率元器件日益增长的需求。氮化镓功率器件目前主要被用于AC适配器和服务器电源等消费电子和
电子资讯报
2024-12-10 17:09
88浏览