【作者介绍】
闻茂泉,阿里巴巴计算平台事业部大数据基础工程团队SRE运维专家。通过阅码场平台将日常工作中积累的一些性能分析方面的经验,与打造的性能分析的工具跟大家一起做个分享。系统性能分析ssar工具已经开源到了龙蜥社区。
说起性能分析就不得不提到《性能之巅》这本书,它是业界里程碑式的经典书籍。在书中第4章观测工具部分,Brendan告诉我们观测工具主要包括:计数器(Counters)、跟踪(Tracing)、采样(Profiling)和监控(Monitoring)几大类。
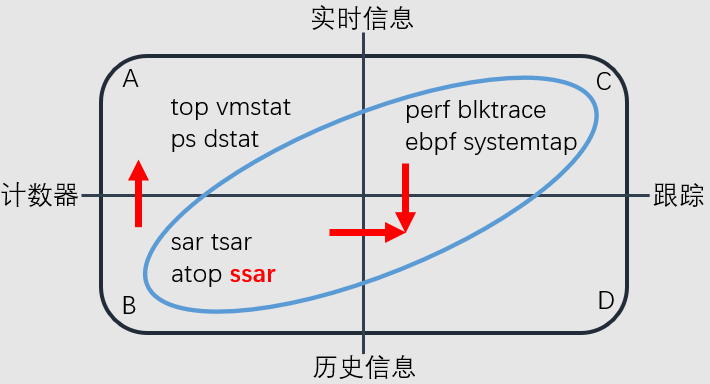
依据数据获取方式和数据实时性,将性能观测工具做了分类:
1)左上角A区是直接读取计数器实时数据的一些系统命令,top、ps这些命令我们都很常用,它们读取的是/proc/这个目录的信息,这里面的数据是内核帮我们记账出来的。
2)左下角B区也是基于计数器的 ,但它是记录历史信息的工具,比如说最常用的就是sar工具,下文我们统称这类工具为系统性能监控工具。在阿里内部也有tsar工具,国外还有开源软件atop。系统性能监控工具一方面可以回朔历史数据,同时也提供实时模式数据。
3)右上角C区跟踪采样工具,内核的tracepoint,kprobe等就是跟踪类工具,perf工具主要是采样类工具,下文我们统称这两类工具为跟踪采样工具。目前这些工具都是只获取实时的数据。如果不结合其他工具,单纯使用它们来追查历史数据,它们是无法提供的。
4)右下角D区,我们认为可以通过B区和C区的工具协同使用达到目标。
我们在性能分析工程实践中重点聚焦在左下B区和右上C区蓝框2个象限的建设上。今天我们主要探讨的就是B区的系统性能监控工具建设情况。以后再给大家介绍C区的工具建设情况。
系统性能监控工具和跟踪采样工具各有优势和特点,我们认为应该挖据各自潜力、发挥各自优势,让他们都最大限度在系统性能分析工作中发挥恰当的作用,切不可偏颇于任何一方。
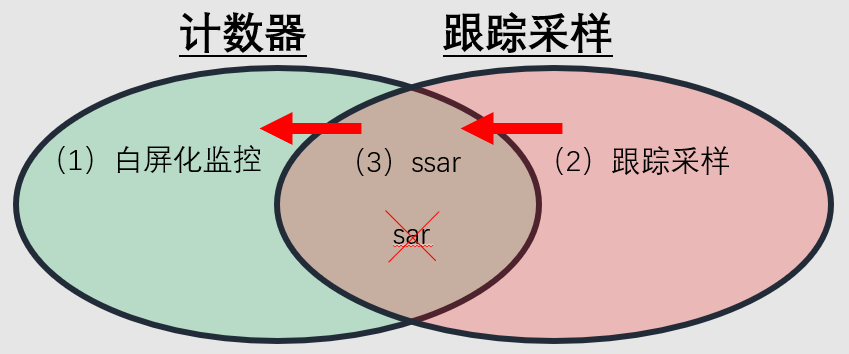
在对系统性能监控和跟踪采样工具的具体理解上,我们认同如下3个理念:
1)内核计数器(Counters)信息获取代价低,无额外开销。相比较而言,跟踪采样工具或多或少都有一些运行开销,如kprobe的使用还可能会引起一些稳定性风险。因此,我们倾向于最大化挖掘计数器信息的价值,给跟踪采样工具减负。比如要获知机器直接内存回收的信息时,内核计数器已经提供了更低代价获取的直接内存回收和异步内存回收的指标,就完全没必要使用ftrace监控直接内存回收的情况了。另一方面,对于内核计数器不能涵盖的细颗粒度内核数据,还必须要依赖内核跟踪采样工具获取。比如当IOPS较高时,我们想了解具体的每一个IO读写的具体文件信息,内核计数器中完全没有相关信息。只有让跟踪采样工具专注于自己的核心任务,才更有条件打磨出更加稳定和可靠的产品级工具方案。毕竟只专注于2件事,比同时干10件事更容易干的出色。
2)现有的系统性能监控工具,除单机监控工具外,还有很多白屏化的监控平台。白屏化监控平台一般都是将数据采集到中心数据库,然后再集中展示。白平化监控平台采集更详细的计数器信息时,总会遇到存储成本的压力的问题,因此不宜将过多计数器指标采集到白屏化监控平台。但同时对于一些高频使用的常规指标,如CPU、内存和网络使用率情况,使用白屏化监控平台展示,确实可以大大提升可观测性。所以高频常规指标使用白屏化监控平台的同时,仍然需要依赖一个数据更加丰富的黑屏系统性能监控工具作为补充,以应对一些关键时刻必须依赖的低频计数器数据。
3)传统的黑屏系统性能监控工具,多年来一直相对比较固化,历数2010年、2015年、2020年指标内容变化不是特别大。举个例子,新版本内核的计数器中,网络扩展指标多达400多个,仅TCP扩展指标就有116个,但是实际上常规的系统性能监控在TCP网络指标这一块,也就使用了不超过15个指标,大部分指标价值并没有被挖掘出来。这些网络的内核计数器指标,在很多网络相关问题发生时,都特别有使用价值。
基于这些理念,我们认为研发一款数据指标更全、迭代周期更短、性能更加稳定的系统性能监控工具,以应对日益复杂系统性能问题是很必要的。
今天我们要介绍的阿里自研ssar工具,就是这样一款系统性能监控类工具,并且已经在知名的操作系统社区龙蜥开源。它几乎涵盖了传统系统性能监控sar工具的所有功能,同时扩展了更多的整机级别的指标,新增了进程级指标和特色的load指标,load高问题的诊断是这个工具一个独特的功能。
开源软件atop也是这样一个类似功能的系统性能监控工具。公开渠道了解到友商也在大规模部署atop工具,这说明在业界其他互联网公司也感受到了拥有这样一个功能定位的监控工具的重要性。
下文我会用几个例子说明我们是如何结合使用系统性能监控工具和跟踪采样工具的。
系统性能监控工具ssar开源地址:
https://gitee.com/anolis/tracing-ssar.git
其中Reference_zh-CN.md是详细的中文帮助手册,package目录中有rpm和deb包提供,其他操作系统可以自行编译打包。
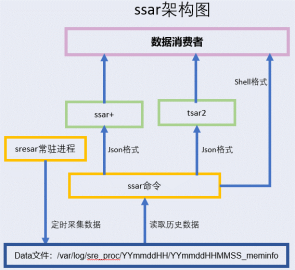
ssar工具分为采集器、内层的通用查询器、外层的增强查询器和经典查询器几部分。
1)采集器sresar:C语言实现的一个常驻进程,将数据记录到本地磁盘,采集数据内容包括:
(a) 按文件单位采集的整机数据,meminfo、stat、vmstat等;
(b) 包含24个指标的进程级数据;
(c) 独特的load5s指标和详细的R或D状态线程详情数据;
2)通用查询器ssar命令:c++语言实现,负责按文件名、某行、某列等通用规则对文件数据进行逻辑解析。
3)古典查询器tsar2:python语言实现,对ssar命令进行封装,全面兼容tsar命令;
4)增强查询器ssar+:python语言实现,对ssar命令进行封装,规划上是未来ssar工具的主要核心,适合于把较复杂的数据逻辑放在python语言实现层。
传统sar工具只采集一些固定指标。在使用C语言采集的同时进行指标解析的模式下,不是极难扩展新指标,就是扩展新指标迭代周期特别长。
ssar工具完全颠覆了传统sar工具的架构设计,在产品设计和程序架构上做了很多变化,可以让我们快速、低成本的增加新的计数器指标。
1)如果我们关注一个新的指标,但是又没有被采集。对于修改传统的系统性能监控工具sar来说,修改发布迭代周期是非常长的,发布下来可能要数周到数月。在学习内核知识或者解决生产问题的时候,新问题等不起这么久。但ssar工具以文件为采集单位,不需要修改代码,直接改一下配置文件,重启srerar采集进程就可以采集一个新的数据源文件。新增采集文件可在sys.conf文件中的file区域增加一行配置项,其中sre_path为数据源位置,cfile为数据文件存储名,turn为开启采集。

2)ssar把一些通用处理逻辑都抽象到ssar命令通用查询器里,配置文件采集后,只需一条ssar命令查询显示数据,完美实现分钟级周期的迭代。其中cfile指定存储文件名,line指定第3行,column指定第5到15行,metric指定显示原值,alias指定指标名称。

3)更加复杂的逻辑,ssar把它转移到外层python语言的查询器中实现。这个时候你很容易通过在python中的修改来适应数据解析的变化。内核中有些指标伴随着内核版本的变化格式也在变化,比如TCP的TimeWaitOverflow指标在3.10、4.9和4.19版中所处的列数就不同。此时可以python语言中轻松获取column值,传递给ssar通用查询器。即使面对未来内核版本中的未知变化,我们也可以通过python查询器应付自如。可随时调试和升级python查询器,如cp tsar2 /tmp/test.py,不论是单机环境debug,还是脚本批量下发,均可轻量级操作。
相比较传统系统性能监控工具,ssar的特点是能记录更加丰富的计数器 (Counters) 指标信息,但这也会占用更多的磁盘存储空间。ssar工具默认记录7天历史数据,通常占用磁盘空间不超过1GB。近20年来,随着存储技术的发展,单位空间的磁盘存储成本价格下降到千分之一。适当提高系统性能监控工具的采集数据量是有一定可行性的。
为了追求更加完美的磁盘空间稳定性,ssar仍然设计了更加积极的磁盘存储空间策略。还设置了专门的参数,当磁盘空间使用率达到阈值(默认90%)后,会停止数据采集。不但如此,当由于其他进程原因使磁盘空间数据继续增长并超过90%时,ssar会启动对7天内较早历史数据的删除工作,直到磁盘空间使用率小于90%或将ssar历史数据基本删除。
用图示表示,图中蓝色的部分就是A、B、C、D中各台机器的原来磁盘空间使用情况,有多些的,有少些的。
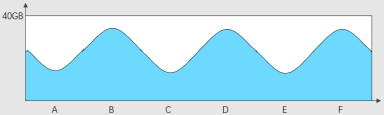
传统的系统性能监控工具会占用每台机器固定的磁盘存储空间,相当于不区分各个机器的磁盘空间使用现状,每台机器都增加图中红色部分的磁盘空间占用。当系统性能监控工具采集数据量较大后,必须重新规划磁盘分区的存储空间。
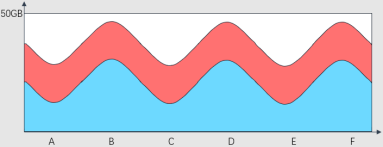
ssar系统性能监控工具,使用的是图中这个绿色区域的存储空间。无需重新规划磁盘分区的存储空间。
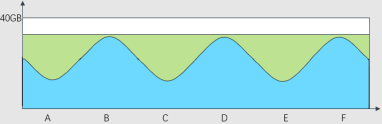
实际生产中磁盘空间的规划,一般都会保留一定的free空间作为buffer,应对突发情况。传统系统性能监控工具所在磁盘分区必须相应的规划一个额外的磁盘空间,而ssar工具的这种磁盘空间处理逻辑不用规划额外的磁盘空间。唯一的缺点就是磁盘打满同时又需要消费ssar数据的场景,但这个场景概率极低。
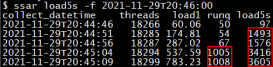
传统的系统性能监控工具中的load1指标尽管比load5和load15指标更精准,仍然不能满足排查问题时的时间维度的精准度要求。ssar在国内外全行业独创了load5s指标,该指标可以让我们将load的准确性提升到5秒级的精度。load5s指标的准确性绝不仅体现在采集频率上,简单说load5s指标就是R+D的线程数,也是内核数据结构中的全局变量active值。
下面通过一个实验来带大家理解load5s指标。我们找一台实验机器,我们在终端窗口A查看load,没有任何负载压力load1非常低。我们现在再开一个终端窗口B,运行一个模拟负载压力的命令,命令内容是“stress -t 40 -c 1000”,其中stress命令需要自己安装。stress 命令主要用来模拟系统负载较高时的场景,这里并发启动1000个消耗CPU资源的单线程进程,就是1000个线程,并且控制只运行40秒后就停止。我们测试的stress命令是15分10秒执行的,经过40秒就是15分50秒结束。stress命令执行结束后,我们再回到终端A使用ssar load5s命令查看运行效果。
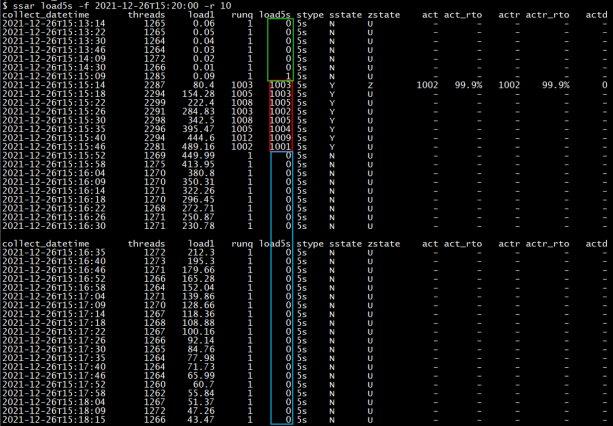
依次分析实验的结果:
1)绿色时间区域15分09秒时,load5s和load1都还处于一个低水位,毫无疑问说明当时机器负载压力很低。
2)伴随着15分10秒stress命令开始执行后,红色时间区域load5s和load1都同时升高, 15分14秒采集时刻,load5s值已经达到1003,load1开始升高到80.4,但是这个load1的值远远不能体现出当前机器上并发运行1000个负载压力的线程的状况。随着时间的推移,15分46秒这个时刻,load1的值缓慢升到了489.16。
3)15分50秒1000个stress并发进程退出,在蓝色时间区域15分52秒这个时刻的load5s值也同时迅速降低到了很低的值0。但是我们看到15分52秒这个时刻的load1值,依然有449.99这么高,这里的load1值看上去是及其令人迷惑的。
上面这个实验说明load5s才是更准确反映系统负载压力的指标,而单纯用load1值判断机器的负载是不准确的。所以我们需要用load5s指标替代load1指标来精准判断机器负载发生的时间范围。除load5s指标外,上面的解决方案中,还提供了一组指标用于全面的评估系统负载情况。其中load5s是R+D状态的线程数之和,runq是当时的R状态线程数,threads是所有状态线程数总和,因此threads值是load5s值的天花板,threads最大值受内核参数设置限制。
ssar工具还会根据load5s和CPU核数之比,来触发对load详情的采集,前边的actr是采集到并发的R状态线程数,actd是采集到并发的D状态线程数,act是actr和actd数之和。当我们需要了解load构成的详细因素时,可以借助load2p子命令进一步显示actr和actd的详情数据。
虽然load5s指标体系能如此精准的反应系统的负载压力情况,但我们并没有依赖kprobe、ebpf等任何跟踪采样技术。load5s指标完全在用户态通过工程化的方法巧妙获取,充分体现了我们“最大化挖掘计数器历史信息价值”的理念。
如此神奇的load5s指标,在最初的发现和理解过程,还曾经深入借助了跟踪采样工具的支持,下面按时间线来回顾下这个历程。
1)首先结合systemtap工具的使用,同时阅读内核load部分的内核代码,了解到linux load的计算逻辑是在calc_global_load函数中获取一个active全局变量(active包含R和D两种状态的线程数量),然后按照每隔5秒钟的频率采样,最后由近及远按不同权重计算出load值。归纳起来的公式就是:
load1(n) =func1(load1(n-1), active(n))
load1(n-1) =func1(load1(n-2), active(n-1))
当前的这个load1值,是拿5秒钟前的上一个load1跟当前时刻这个active值做一个计算得出来的。那上一个时刻load1值就是上上一个时刻load1值和上一个时刻active值计算出来的,所以这是一个无限递归的过程。
2)遗憾的是内核并没有暴露active变量值,但我们可以借助一个kprobe内核模块hook内核变量并通过proc接口暴露给用户空间。可参考本人较早文章《深度好文:全面解析 Linux Load 》,其中有如下代码:
git clone https://github.com/os-health/load5s.git
通过暴露的内核变量值,运行load预测脚本,按照内核里面load的计算方法,在用户空间重算一遍load值,结果如图。
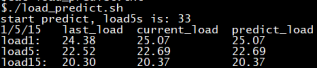
看到内核吐出的current_load值25.07和我们shell脚本预测的predict_load值25.07完全一样,说明在load_predict.sh脚本中计算逻辑就是内核对load值的计算逻辑。这个预测值25.07是根据上一个load1值24.38和load5s值的33(load5s就是active值)计算而来。
3)由此,我们完全可以反其道而行。既然是这个25.07是通过这24.38和33这两个值算出来的,我们完全可以监控这个load1的值的变化,然后每5秒钟去把这个active值反算出来就可以了。
active(n) = func2(load1(n) , load1(n-1))
通过在用户空间反算active值,使其在工程上具有极大的通用性和可靠性,我们将active值命名为load5s。
在load高的各种场景中,有一种R状态线程数并发多的load高是由于sys CPU使用率偏高引起的。ssar全面的指标体系,从多个角度将这种场景发生过程进行了透彻的呈现。
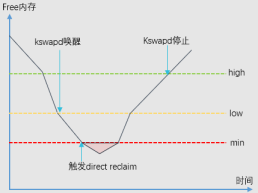
为了准确的说明问题,有必要回顾下内核内存回收的相关概念。如图所示,当整机free内存低于黄线low阈值时,内核异步内存回收线程kswapd开始被唤醒,kswapd会在其他进程申请内存的同时回收内存。当整机free内存到达红线min阈值时,触发整机直接内存回收,所有来自用户空间的内存申请将被阻塞住,线程状态同时转换为D状态。此时只有来自内核空间的内存申请可以继续使用min值以下的free内存。后续当整机free内存逐步恢复到绿线high阈值以上后,kswapd线程停止内存回收工作。
下面以ssar的数据指标为依据,一步一步的展示了当整机内存紧张后是如何引起sys CPU高,并进而引发load高的完整过程:
1)用户空间java进程在20点43分到20点45分2分钟内大量申请24GB内存;

2)整机内存used在20点43分到20点45分2分钟内迅速增长了26GB,同时整机free内存迅速减少了14GB;
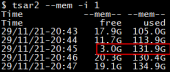
3)free内存在20点45分时只有3GB,低于low阈值,pgscan_kswapd/s值非0表明触发kswapd异步内存回收。
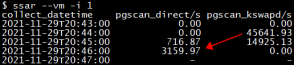
4)kswapd异步内存回收跟不上进程内存申请的速度,当free内存达到min阈值时,pgscan_direct/s值非0表明触发直接内存回收,用户空间内存申请进程D住。栈顶函数sleep_one_page和congestion_wait等都是典型的直接内存回收时的特征。
5)20点44分到20点45分出现大量网络吞吐,每秒进出流量分别达到1.5G和1.0G。网络流量吞吐会伴有内核空间内存申请,继续消耗min阈值以下(橙色部分)free内存。
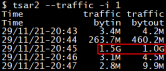
6)内核网络模块会申请order3阶内存,20点45分时刻buddyinfo中order3以上高阶内存消耗殆尽,剩余的3GB free内存处于碎片化状态。内核空间申请的内存是连续内存,虽然order2和order1有库存,但申请order3时是无法被分配的,内核只能处于忙等状态。

7)触发内核态忙等,同时会引发20点44分到20点45分的sys CPU升高,sys CPU平均每秒占总CPU资源的89.61%,挤占用户空间既有进程CPU资源,同期用户态CPU使用从原来的72.59%降低到7.73%。
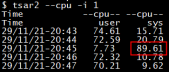
8)触发直接内存回收时,会引发大量D状态线程,后续order3库存枯竭引发sys CPU高后,会继续引发大量R状态线程。load5s子命令看到的现象就是先出现load5s指标升高,再出现load5s和runq同时升高。
以上各指标立体的展现了整机内存不足时,如何引发load高的机制。有人也许会好奇,一开始是如何将这些指标关联到一起的。高阶内存不足引起sys CPU异常的场景,在问题调查早期也的确是通过采样(Profiling)工具火焰图获取的直接线索。在火焰图热点函数栈中有__alloc_skb这样函数,再结合内核代码,之后才想到补充buddyinfo内核计数器指标观察order0到order10的情况。
补充buddyinfo计数器指标后,再遇到sys CPU高问题,通过以上指标体系就直接可以判断了,不用再次使用采样工具(perf)。
终于有一天,sys CPU又打高了,但是并没有同时出现内存相关指标的异常,只发现占用sys CPU的是大量内核线程kworker。

这时还需要继续借助采样(Profiling)工具获取火焰图分析。
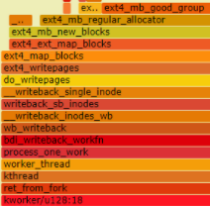
根据火焰图中热点函数ext4_mb_regular_allocator/ext4_mb_good_group,再结合sys CPU占用率高的进程是kworker,结合内核代码可以看到这是文件系统方面的函数,在分配空闲块。自然就会去想到查看磁盘空间指标,发现确实出现了100%的情况发生。

这是本文第二个例子体现了“最大化挖掘计数器历史信息价值,发挥计数器指标和跟踪采样工具各自的优势”的理念。
本文举的第三个例子,是关于nvme协议的SSD盘的。这种盘IO性能很高,有时候会遇到读的IOPS高达上万的情况,磁盘IO Util打到100%,而且单IO size特别小只有4KB。
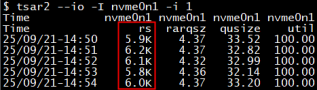
阿里有一个自研的IO跟踪工具,可以抓到每一个IO读写了那个文件。最初出现这种IO打满情况时,我们使用阿里自研的IO跟踪工具抓取了每一个IOPS的详情,发现读取的文件都是二进制的so包,而且分析扇区地址Sector信息时发现同一个扇区地址平均最多每秒被重复读取了178次,这是非常不符合常规的。正常情况下,我们的程序是一次性从磁盘加载到内存空间,不会重复加载,但是这里一秒钟重复加载178次,说明一秒内又被丢弃了177次。问题调查到这里,我们自然想去查看内存方面的问题。
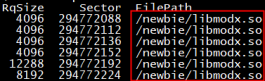
经分析最终确认是cgroup的内存设置问题,该进程的memory.limit_in_bytes设置为4GB,当前进程的rss内存使用已经到了3.9GB,剩余的100MB空间不足以完全加载800MB的clean 状态的二进制可执行代码部分。先加载第一个100MB的代码段,当开始执行第二个100MB的代码段时,必须释放一些第一个100MB的代码段。如此就会出现反复加载同一个扇区地址代码段的情况。
了解了这种场景的原理,会发现出现这种场景时整机和进程级别的主缺页中断数会大量增加。当再次出现磁盘读IO异常高时,我们可以不依赖IO跟踪工具,直接查看整机主缺页中断数,判断是否又发生了内存颠簸。
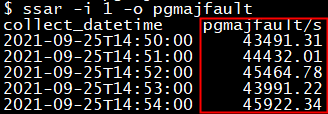
当确定时发生内存颠簸时,再进一步通过ssar进程级指标确定大量发生主缺页中断的进程。通过pid查看进程cgroup中memory.limit_in_bytes 值的设置,并对比进程当前的rss值也可以诊断这类问题。并且这类问题不论发生在任何时间,都可以通过ssar指标轻松诊断。

前面在linux load、sys CPU和IOPS的性能分析过程中,分享了3个案例。这3个案例都贯穿了一个性能分析的思路,最大化挖掘计数器历史信息的价值,解放跟踪采样工具。使用跟踪采样工具探索发现问题的内在逻辑后,再将相关计数器指标固化到ssar系统性能监控工具中。



