炬芯科技重磅发布全新端侧AI音频芯片,低功耗大算力技术助力AI生态发展
时间:2024-11-08
作者:炬芯科技
分享
 扫码分享到好友
海报分享
扫码分享到好友
海报分享
2024年11月5日消息,炬芯科技创新性的采用了基于模数混合设计的电路实现存内计算Computing-in-Memory(简称CIM)技术,在SRAM介质内用客制化的模拟设计实现数字计算电路,既实现了真正的CIM,又保证了计算精度和量产一致性。炬芯科技面向电池驱动的低功耗IoT领域成功落地了第一代基于模数混合电路实现的SRAM based CIM(Mixed-mode SRAM based CIM,简称MMSCIM)在500MHz时实现了0.1TOPS的算力,并且达成了6.4TOPS/W的能效比,受益于其对于稀疏矩阵的自适应性,如果有合理稀疏性的模型(即一定比例参数为零时),能效比将进一步得到提升,依稀疏性的程度能效比可达成甚至超过10TOPS/W。基于此核心技术的创新,炬芯科技打造出了下一代低功耗大算力、高能效比的端侧AI音频芯片平台。
炬芯科技正式宣布发布全新一代基于MMSCIM端侧AI音频芯片,共三个芯片系列:第一个系列是 ATS323X,面向低延迟私有无线音频领域;第二个系列是ATS286X,面向蓝牙AI音频领域;第三个系列是 ATS362X,面向AI DSP领域。
三个系列芯片均采用了CPU(ARM)+ DSP(HiFi5)+ NPU(MMSCIM)三核异构的设计架构,炬芯的研发人员将MMSCIM和先进的HiFi5 DSP融合设计形成了炬芯科技“Actions Intelligence NPU(AI-NPU)”架构,并通过协同计算,形成一个既高弹性又高能效比的NPU架构。在这种AI-NPU架构中MMSCIM支持基础性通用AI算子,提供低功耗大算力。同时,由于AI新模型新算子的不断涌现,MMSCIM没覆盖的新兴特殊算子则由HiFi5 DSP来予以补充。
以上全部系列的端侧AI芯片,均可支持片上1百万参数以内的AI模型,且可以通过片外PSRAM扩展到支持最大8百万参数的AI模型,同时炬芯科技为AI-NPU打造了专用AI开发工具“ANDT”,该工具支持业内标准的AI开发流程如Tensorflow,HDF5,Pytorch和Onnx。同时它可自动将给定AI算法合理拆分给CIM和HiFi5 DSP去执行。 ANDT是打造炬芯低功耗端侧音频AI生态的重要武器。借助炬芯ANDT工具链轻松实现算法的融合,帮助开发者迅速地完成产品落地。

根据炬芯科技公布的第一代(GEN1)MMSCIM和HiFi5 DSP能效比实测结果的对比显示:
当炬芯科技GEN1 MMSCIM与HiFi5 DSP均以500MHz运行同样717K参数的Convolutional Neural Network(CNN)网路模型进行环境降噪时,MMSCIM相较于HiFi5 DSP可降低近98%功耗,能效比提升达44倍。而在测试使用935K 参数的CNN网路模型进行语音识别时,MMSCIM相较于HiFi5 DSP可降低93%功耗,能效比提升14倍。
另外,在测试使用更复杂的网路模型进行环境降噪时,运行Deep Recurrent Neural Network模型时,相较于HiFi5 DSP可降低89%功耗;运行Convolutional Recurrent Neural Network模型时,相较于HiFi5 DSP可降低88%功耗;运算Convolutional Deep Recurrent Neural Network模型时,相较于HiFi5 DSP可降低76%功耗。
最后,相同条件下在运算某CNN-Con2D算子模型时,GEN1 MMSCIM的实测AI算力可比HiFi5 DSP的实测算力高16.1倍。
综上所述,炬芯科技此次推出的最新一代基于MMSCIM端侧AI音频芯片,对于产业的影响深远,有望成为引领端侧AI技术的新潮流。
炬芯科技选择基于模数混合电路的SRAM存内计算(Mixed-Mode SRAM based CIM,简称MMSCIM)的技术路径,具有以下几点显著的优势:第一,比纯数字实现的能效比更高,并几乎等同于纯模拟实现的能效比;第二,无需ADC/DAC, 数字实现的精度,高可靠性和量产一致性,这是数字化天生的优势;第三,易于工艺升级和不同FAB间的设计转换;第四,容易提升速度,进行性能/功耗/面积(PPA)的优化;第五,自适应稀疏矩阵,进一步节省功耗,提升能效比。
而对于高质量的音频处理和语音应用,MMSCIM是最佳的未来低功耗端侧AI音频技术架构。由于减少了在内存和存储之间数据传输的需求,它可以大幅降低延迟,显著提升性能,有效减少功耗和热量产生。对于要在追求极致能效比电池供电IoT设备上赋能AI,在每毫瓦下打造尽可能多的 AI 算力,炬芯科技采用的MMSCIM技术是真正实现端侧AI落地的最佳解决方案。
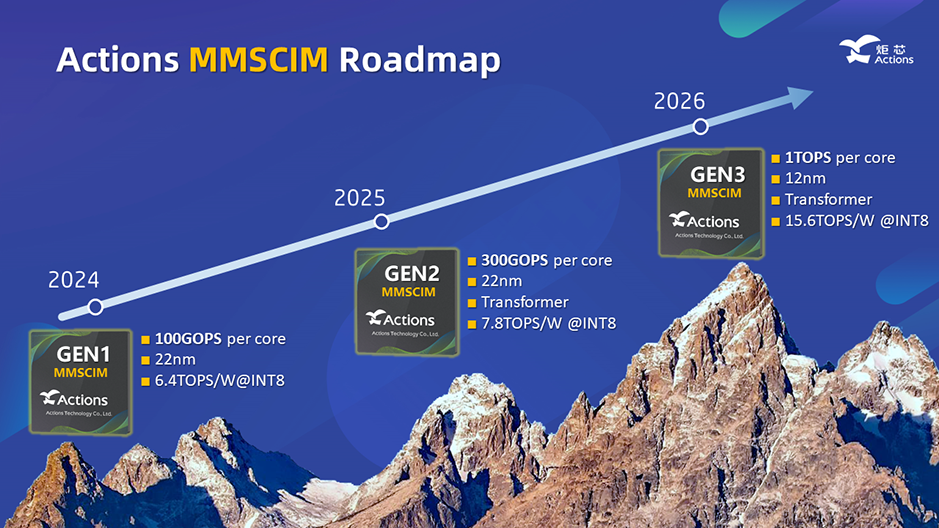
炬芯科技还公布了MMSCIM路线规划,从路线图中显示:1、炬芯第一代(GEN1)MMSCIM已经在2024年落地, GEN1 MMSCIM采用22 纳米制程,每一个核可以提供100 GOPS的算力,能效比高达6.4 TOPS/W @INT8;2、到 2025 年,炬芯科技将推出第二代(GEN2)MMSCIM,GEN2 MMSCIM采用22 纳米制程,性能将相较第一代提高三倍,每个核提供300GOPS算力,直接支持Transformer模型,能效比也提高到7.8TOPS/W @INT8;3、到 2026 年,推出新制程12 纳米的第三代(GEN3)MMSCIM,GEN3 MMSCIM每个核达到1 TOPS的高算力,支持Transformer,能效比进一步提升至15.6TOPS/W @INT8。
每一代MMSCIM技术均可以通过多核叠加的方式来提升总算力,比如MMSCIM GEN2单核是300 GOPS算力,可以通过四个核组合来达到高于1TOPS的算力。
从ChatGPT到Sora,文生文、文生图、文生视频、图生文、视频生文,各种不同的云端大模型不断刷新人们对AI的预期。然而,AI发展之路依然漫长,从云到端将会是一个新的发展趋势,AI的世界即将开启下半场。
以低延迟、个性服务和数据隐私保护等优势,端侧AI在IoT设备中扮演着越来越重要的角色,在制造、汽车、消费品等多个行业中展现更多可能性。基于SRAM的模数混合CIM技术路径,炬芯科技新产品的发布踏出了打造低功耗端侧 AI 算力的第一步,成功实现了在产品中整合 AI 加速引擎,推出CPU+ DSP + NPU 三核 AI 异构的端侧AI音频芯片。
未来,炬芯科技将继续加大端侧设备的边缘算力研发投入,通过技术创新和产品迭代,实现算力和能效比进一步跃迁,提供高能效比、高集成度、高性能和高安全性的端侧 AIoT 芯片产品,推动 AI 技术在端侧设备上的融合应用,助力端侧AI生态健康、快速发展。Actions















