瞄准五大方向持续攻关,构建AI网络底座
时间:2024-08-28
作者:是德科技产品营销经理Linas Dauksa
分享
 扫码分享到好友
扫码分享到好友

是德科技产品营销经理Linas Dauksa
如果企业拥有数据中心,需要关注的是人工智能(AI)技术可能很快就会部署到数据中心。无论AI系统是一个聊天机器人,还是横跨多个系统的自动化流程,亦或是对大型数据集的有效分析,这项新技术都有望加速和改善许多企业的业务模式。然而,AI的概念也可能会令人产生困惑和误解。是德科技的这篇文章旨在探讨有关AI网络如何工作以及该技术面临的独特挑战等五个方面的基本问题。
GPU相当于AI计算机的“大脑”
简单来说,AI计算机的大脑就是图形处理器(GPU)。过去,人们可能听说过中央处理器(CPU)是计算机的大脑。GPU 的优势在于,它是一个擅长进行数学计算的 CPU。当创建AI计算机或深度学习模型时,需要对其进行 “训练”,这就要求对可能包含数十亿个参数的数学矩阵方程进行求解。进行此种数学运算的最快方法是让多组 GPU 在相同的工作负载上运行,即便如此,训练AI模型也可能需要数周甚至数月的时间。AI模型创建后,会被迁移到前端计算机系统,用户可以向模型提问,这就是所谓的推理。
AI计算机集众多GPU于一身
用于处理AI工作负载的最佳架构是在一个机架中集成一组GPU, 并将其连接到机架顶部的交换机中。还可以有更多的 GPU 集成机架,按照网络层次结构连接所有 GPU。随着所要解决的问题的复杂性增加,对 GPU 的需求也就越大,有些将要部署的解决方案可能会包含数千个 GPU 集群。这不难让人联想到数据中心里一排又一排密密麻麻的服务器机架,这种场景非常常见。
AI集群是一个小型网络
在构建AI集群时,有必要将更多GPU连接起来,这样它们才能协同工作。而GPU之间的连接可以通过创建微型计算机网络的方式来实现,让GPU与GPU之间能够互相发送和接收数据。

图1:AI集群
图1展示了一个AI集群,其中最下方的圆圈代表了GPU在执行任务时的工作流程。将许多GPU连接到了机架顶部(ToR)的交换机。ToR 交换机还连接到了上图顶部的骨干网络中使用的交换机,这张图充分描绘了需要集成众多GPU时所采用的清晰网络层次结构。
AI部署的瓶颈在于网络
去年秋天,在OCP(开放计算项目)全球峰会上,与会者重点讨论了新一代AI基础设施。其中,来自迈威尔科技的Loi Nguyen充分阐述了由此出现的一个关键问题:网络已经成为新的瓶颈。
GPU在解决数学问题或者处理工作负载方面非常有效。这些系统完成任务的最快方法是让所有 GPU并行计算、协同工作来处理相同的工作负载。要做到这一点,GPU需要获取它们即将处理的信息,并且它们彼此之间可以互相进行通信。如果其中一个GPU没有得到它所需的信息,或者需要更长的时间来输出结果,那么所有其他GPU都必须等待,直到能够一致协作来完成任务。
从技术角度来讲,拥堵的网络造成的数据包延迟或者数据包丢失可能会导致系统需要反复重新传输数据包,并显著延长完成任务所需的时间。这意味着,可能会有价值数百万或数千万美元的 GPU闲置,从而影响最终的结果,当然也可能会影响希望通过利用AI技术获得商机的企业的上市时间。
测试是成功运行AI网络的关键
为了高效运行AI集群,用户需要确保GPU得到充分利用,这样才能较早地完成学习模型的训练,并将其投入使用,实现投资回报最大化。这就需要对AI集群(图2)的性能进行测试和基准测试。然而,这并不是一件轻而易举的事儿,因为GPU和网络架构之间有着千丝万缕的联系和诸多设置,它们需要在架构上实现互补,以满足处理工作负载的需要。
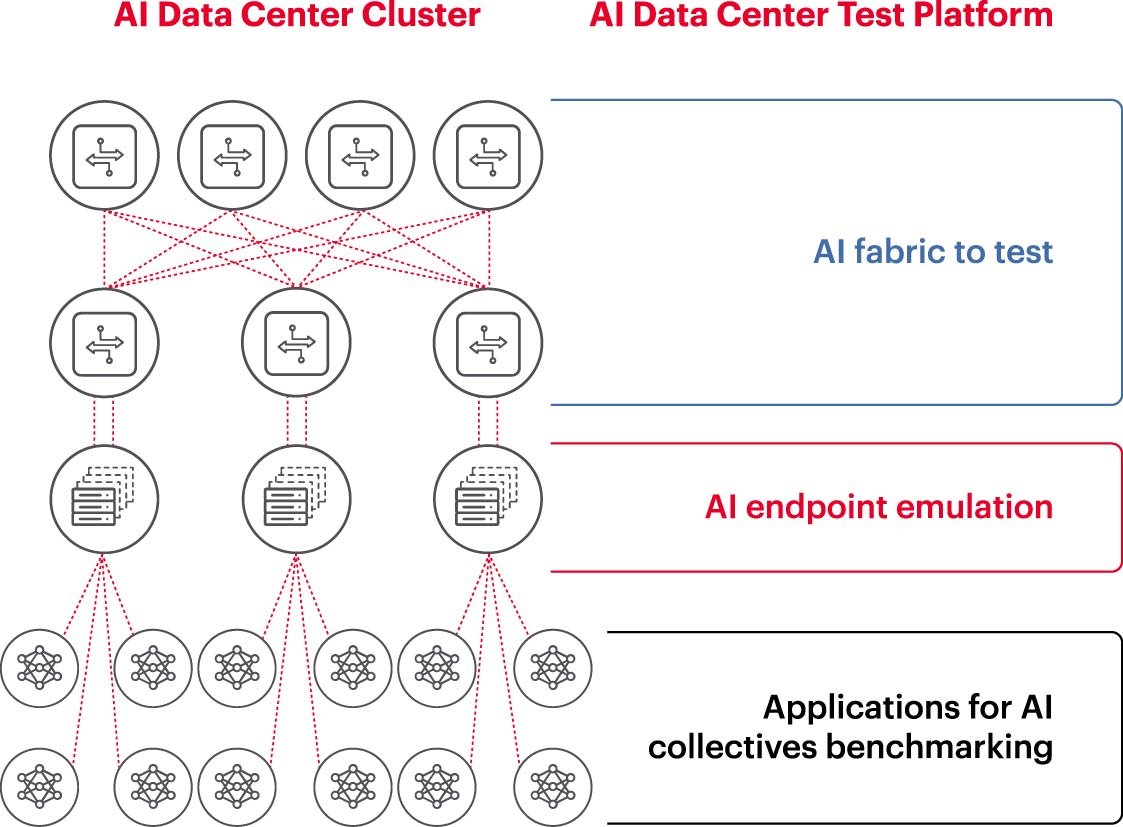
图2:AI数据中心测试平台及如何测试AI数据中心集群
这给AI网络带来了诸多挑战:
应对上述挑战的方法之一是,首先在实验室环境中对所提出的设置的一个子集执行测试,以便对JCT、整个AI集群所能达到的带宽等关键参数进行基准测试,同时将这些参数与Fabric容量利用率以及内存缓冲区消耗情况进行比较。这种基准测试有助于找到GPU/工作负载的分布与网络设计/设置之间的平衡点。当计算架构和网络工程师对结果比较满意时,他们就能够将这些设置应用到执行任务的工作系统中并且衡量新的结果是否理想。
小结
为了充分释放AI的潜能,需要优化AI网络的设备和基础架构。企业的研究实验室和学术机构致力于对构建和运行高效AI网络所涉及的各个层面进行分析,以解决在大型网络上执行任务所面临的挑战。尤其是在当前行业最佳实践正不断发生变化的情况下,形势更是如此。只有采用这种可以反复验证、高度协作的方法,业界才能实现可重复的测试,并灵活地尝试各种“假设 ”场景,这是优化AI网络的基础。















