浅析网络安全的“守门神”-iptables
时间:2024-07-18
分享
 扫码分享到好友
扫码分享到好友
iptables最早可以追溯到ipfirewall,这是在Linux内核1.x时代的一个简易访问控制工具,能够工作在内核中,对数据包进行检测。然而,ipfirewall的功能非常有限,因为它需要将所有的规则都放进内核中才能运行。随着内核技术的发展,进入2.x时代后,ipfirewall更名为ipchains,它可以定义多条规则,并将这些规则串联起来,共同发挥作用,这使得防火墙的配置和管理变得更加灵活和强大。
而现在,我们所说的iptables是在ipchains基础上的进一步发展。iptables可以将规则组成一个列表,实现绝对详细的访问控制功能。与ipfirewall和ipchains一样,iptables本身并不算是防火墙,而是工作在用户空间中定义规则的工具。这些规则会被内核空间中的netfilter读取,从而实现防火墙的功能。
换句话说,netfilter才是防火墙真正的安全框架,iptables其实是一个命令行工具,位于用户空间,我们通过它操作真正的安全框架netfilter。
当客户端希望与服务器上的某个进程通信时,它会将数据包发送到网卡。在这个过程中,数据包的目标指向了该进程的特定套接字,即特定的IP地址和端口号。当该进程需要回应客户端的请求时,它会生成响应数据包,此时数据包的目的地址变为客户端的地址,而原本进程所监听的IP与端口则转变为数据包的发送起点。
之前我们提到过,防火墙的实质是内核中的netfilter模块。为了确保防火墙的“防护”功能得以实现,我们需要在内核中设置安检口,即“input安检口”和“output安检口”。所有进出服务器的数据包都必须通过这些安检口接受严格的审查。符合放行标准的数据包将被允许通过,而满足拦截条件的数据包则会被拦截,如下图1所示。
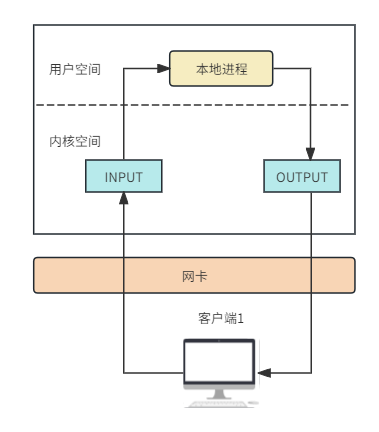
图1 防火墙示意图1
当然,客户端发来的数据包访问的目标地址可能并不是本机,而是其他机器,这时服务器就可以进行对数据包进行转发。这类转发的数据包就会先后通过“prerouting安检口”、“forward安检口”和“postrouting安检口”进行检查,即“路由前”、“转发”与“路由后”,如下图2所示。

图2 防火墙示意图2
在iptables中,上述安检口被称为链(chain),规则被定义在这些链上,而规则又因功能的不同被划分到不同的表(table)中。iptables配置防火墙的主要工作就是添加、修改和删除这些规则。
每当数据包通过这些安检口,安检口会立即启动规则匹配机制,针对传入的数据包逐一比对预设的规则,并根据匹配结果执行相应的操作。通常情况下,安检口上并非仅设置单一规则,而是整合了众多规则以满足不同的安全需求。当这些规则按照特定的顺序紧密排列,就构建起了我们所说的“链”。因此,我们可以将每个安检口视为如图3所示的结构模型,每一个通过安检口的数据包,都必须严格按照顺序,逐一与这条“链”上的所有规则进行比对。一旦数据包与某条规则相匹配,就会立即执行该规则所规定的动作。
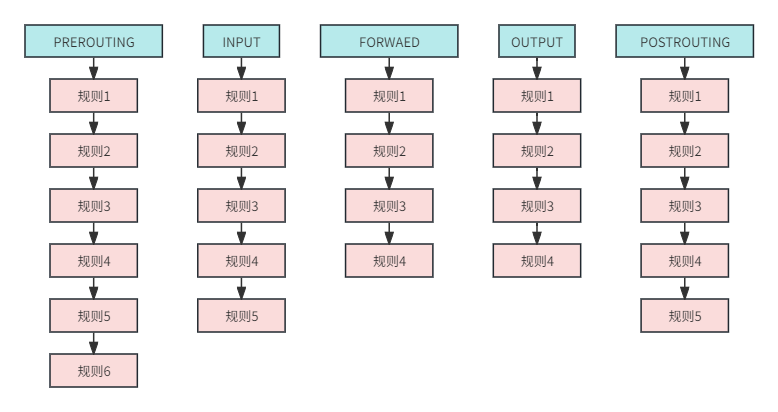
图3 链的结构模型
如上图所示,iptables提供了五个基础链,分别是prerouting,input,forward,output,postrouting,它们的使用场景有所不同。
input 链:当收到访问本机地址的数据包时,将应用此链中的规则。
output链:当本机向外发送数据包时,将应用此链中的规则。
forward链:当收到需要转发给其他地址的数据包时,将应用此链中的规则。
prerouting链:在对数据包做路由选择之前,将应用此链中的规则。
postrouting链:在对数据包做路由选择之后,将应用此链中的规则。
之前我们提到每个“链”上都配置了一系列规则,然而这些规则中有些具有相似的功能。例如,A类规则主要用于对IP地址或端口进行过滤,而B类规则则负责修改数据包内容。为了更高效地管理这些规则,iptables在ipchains的基础上进行了优化升级,将具有相同功能的规则集合称为“表”。iptables提供了四个主要的表,分别是filter表、mangle表、nat表和raw表,其中默认使用的是filter表。这样的设计使得规则的管理和配置更加条理化和系统化。
filter表:对数据包进行过滤,具体规则决定如何处理一个数据包。
nat表:修改数据包的 IP 地址、端口号信息。
mangle表:修改数据包的服务类型,生存周期,为数据包设置标记。
raw表:决定是否对数据包进行状态跟踪。
由于五种链使用场景的不同,注定了某些链不具备某类规则,相对应地,某类规则不一定在所有链里存在。在iptables中,表和链之间的关系如下图4所示。
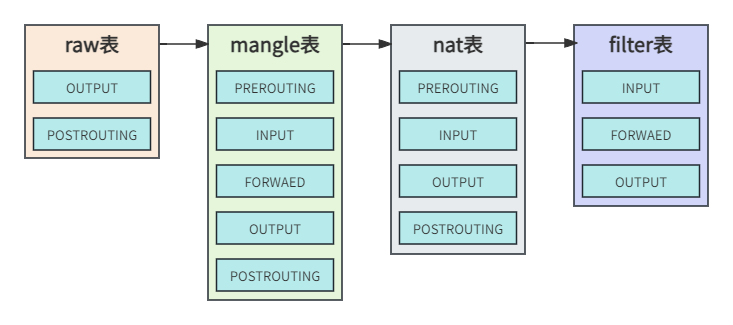
图4 表链关系
上图还反映了一个规律,就是链中不同表的规则匹配的先后。拿prerouting链举例,prerouting链中的规则存放于三张表中,而这三张表中的规则执行的优先级如下:raw - mangle - nat。事实上,iptables为我们定义了4张”表”,当他们处于同一条”链”时,执行的优先级如下:raw - mangle - nat - filter。
在iptables规则中,匹配条件和处理动作是定义规则行为的两个关键组成部分。匹配条件用于确定规则适用于哪些数据包,可以是数据包源地址、目的地址、端口、协议等;而处理动作则定义了对匹配的数据包采取的操作,可以是放行(accept)、拒绝(reject)和丢弃(drop)等。通过灵活组合这些匹配条件和处理动作,管理员可以构建出复杂而精细的规则,以实现网络安全防护、路由管理、地址转换等多种网络操作。
规则的基本命令操作,强烈建议大家去学习朱双印的博客:
,本文主要为大家剖析iptables的工作原理。
结合上述信息,我们可以将数据包通过防火墙的流程总结为下图5所示,在配置iptables规则时,该图应该了然于胸。
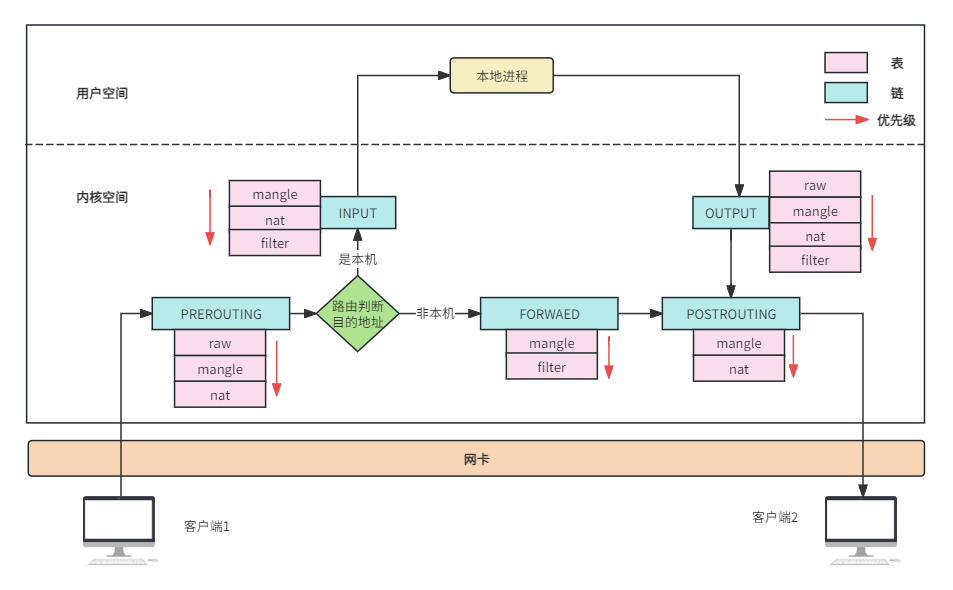
图5 数据处理流程图
发送数据包过程:先进入output链处理,如果没有被拦截则根据路由选择出网口,再进入postrouting链处理,最后从网卡出去。
接收数据包过程:先进入prerouting链处理,根据路由判断数据包发给本机,报文进入input链处理,如果没有被拦截则被进程处理。
转发场景的数据包处理过程:先进入prerouting链处理,根据路由判断数据包是不是发给本机,是则进入forward链处理,如果没有被拦截则进入postrouting链处理,最后从网卡出去。
网络安全防护是不可或缺的一环,特别是在构建大型网络时,在实际使用中iptables有着灵活且强大的防火墙功能。深入理解iptables,不仅有助于更全面地理解整个网络架构,还能精准把握内核空间中的数据流向,并深刻洞悉Linux的安全机制。希望今天的技术分享能为大家带来启发。
作者:万伟潇,缪云海
单位:中国移动智慧家庭运营中心















