AI芯片升级,新一代AI集群加速处理万亿参数大模型
时间:2024-04-01
分享
 扫码分享到好友
扫码分享到好友
一、AI芯片满足庞大计算需求,市场规模不断增长
随着数据规模的爆炸式增长和算法的不断优化,传统的CPU和GPU在处理大规模数据和复杂算法时遇到了性能瓶颈。为了满足日益增长的庞大计算需求,AI芯片应运而生,成为人工智能领域的核心技术之一。
近年来,随着深度学习技术的广泛应用,AI芯片的需求进一步增加。深度学习需要大量的数据进行训练,同时需要高效的计算平台来支持模型的训练和推理。AI芯片的出现正好满足了这一需求,为深度学习任务提供了强大的计算能力。另外,云计算、大数据、物联网等技术的快速发展,人工智能应用场景不断拓宽,AI的训练、推理和自学习基于大量数据处理,对算力有极高需求,拉动AI芯片市场需求持续旺盛。
从市场规模来看,全球AI芯片市场规模预计在未来几年将持续增长。2032年,全球AI市场规模约为2274.8亿美元,预计将以每年约30%的速度继续实现增长。这一增长趋势主要得益于人工智能技术的广泛应用和推动,使得对AI芯片的需求不断增加。
从市场参与者来看,全球AI芯片市场呈现出多元化的竞争格局。英伟达(NVIDIA)等企业在全球AI芯片市场中占据重要地位,以其领先的技术和大规模生产能力成为市场的领导者。同时,谷歌、华为、苹果等科技巨头也在AI芯片领域具备一定的技术实力,并逐渐占据市场份额。此外,越来越多的初创企业也加入到AI芯片市场的竞争中,推动市场创新和技术进步。
从应用场景来看,全球AI芯片的应用领域也在不断扩展。除了传统的智能安防、无人驾驶、智能手机等领域外,AI芯片还广泛应用于智慧零售、智能机器人等新兴领域。这些领域对AI芯片的需求不断增长,推动了AI芯片市场的快速发展。
从技术趋势来看,全球AI芯片领域的技术创新也在不断推进。一方面,随着深度学习等人工智能技术的不断发展,对AI芯片的性能要求也越来越高,需要更高的计算能力、更低的功耗和更小的延迟。另一方面,随着数字孪生、生成式网络等新技术的兴起,AI芯片在数字孪生技术中的应用也将成为未来的发展趋势之一。
然而,尽管全球AI芯片市场发展前景广阔,但也面临着一些挑战和问题。例如,技术壁垒、市场竞争、数据安全等问题都需要得到关注和解决。此外,AI技术的普及和应用场景的日渐扩大,对AI芯片的可靠性和安全性要求也越来越高,需要进一步加强技术研发和标准化工作。
二、构建SuperPOD集群,AI算力大幅提升
据统计,人工智能训练任务中使用的算力呈指数级增长,每3.5个月翻一倍,而趋近物理极限的摩尔定律正在放缓脚步,无法满足每18个月晶体管数量提升一倍的原定目标。随着计算模型复杂性的日益增加,AI和高性能计算(HPC)工作负载典型平台的出现就具备了跨时代意义,新一代AI集群的建设为百亿参数大模型的加速处理提供助力。

在2024 GTC大会上,英伟达通过构建SuperPOD集群,使得AI算力实现大幅提升。英伟达发布了代号为Blackwell的GPU芯片架构和显卡核心,基于该芯片打造了新一代超级芯片GB200,并基于GB200打造了新一代AI计算节点。英伟达还用该AI计算节点配合第五代NVLink连接多块GB200超级芯片,构建了DGX机架。最后,用8个DGX机架所包含的576块最强B200显卡构建了SuperPOD集群,AI算力高达11.5 Exaflops。
具体来看,新一代AI集群的构建始于B200。B200采用了192GB的HBM3e显存,拥有8TB的内存带宽,提供20 PetaFlops的AI性能(FP4),10 PetaFlops的FP8性能。将两块B200显卡芯片与一块Arm Neoverse V2处理器放在一起,B200和Grace Arm核心通过900GB的NVLink-C2C连接,就构成了新一代的超级芯片GB200。双芯片设计使其晶体管数量达到2080亿个,显存容量达到384GB,可提供40 PetaFlops的AI性能。GB200芯片再加上Arm CPU自带的内存,总体内存容量达到864GB,还拥有16TB/s的HBM内存带宽,以及总体3.6TB/s的NVLink带宽。
GB200超级芯片组成了新一代AI计算节点。英伟达通过将2个GB200超级芯片组成一个Blackwell计算节点,使得算力达到80PetaFlops。面对整体较高的计算密度和功耗,英伟达针对这套节点选择了水冷散热方式,采用新发布的、专为AI场景优化的Connectx-800G Infiniband SuperNIC网卡,服务器的另一端还带有NVLink 交换机芯片。同时,节点中还使用了Bluefield-3 DPU,帮助服务器处理网络、存储、网络安全方面的需求。
AI计算节点组成了DGX机架。通过将18台Blackwell计算节点放在一个机架中,使一个机架搭载36块GB200超级芯片。显卡之间通过NVLink交换机连接,在DGX GB200 NVL72机架中包含72块共享显存的B200显卡芯片。
DGX机架是构成SuperPOD AI算力集群的最后一步。DGX GB200 NVL72机架的顶部拥有一台Quantum Infiniband-800交换机。配合第五代NVLink技术,8个DGX GB200 NVL72机架组成了包含576块B200显卡芯片的SuperPOD AI算力集群,可提供 11.5 Exaflops(576 x 20 PetaFlops)的AI计算性能。值得注意的是,一台每秒完成1 Flop的笔记本电脑,要花费大约31.7 亿年的时间才能完成1 Exaflop的运算量,因此DGX GB200 NVL72机架组成的AI算力集群可提供的算力可谓相当惊人。
在此之上,SuperPOD系统通过 NVIDIA Quantum InfiniBand 或者Spectrum以太网连接,在AI数据中心里扩展到32000个B200显卡,整个数据中心图提供645ExaFlops的AI算力,13PB的高速内存。
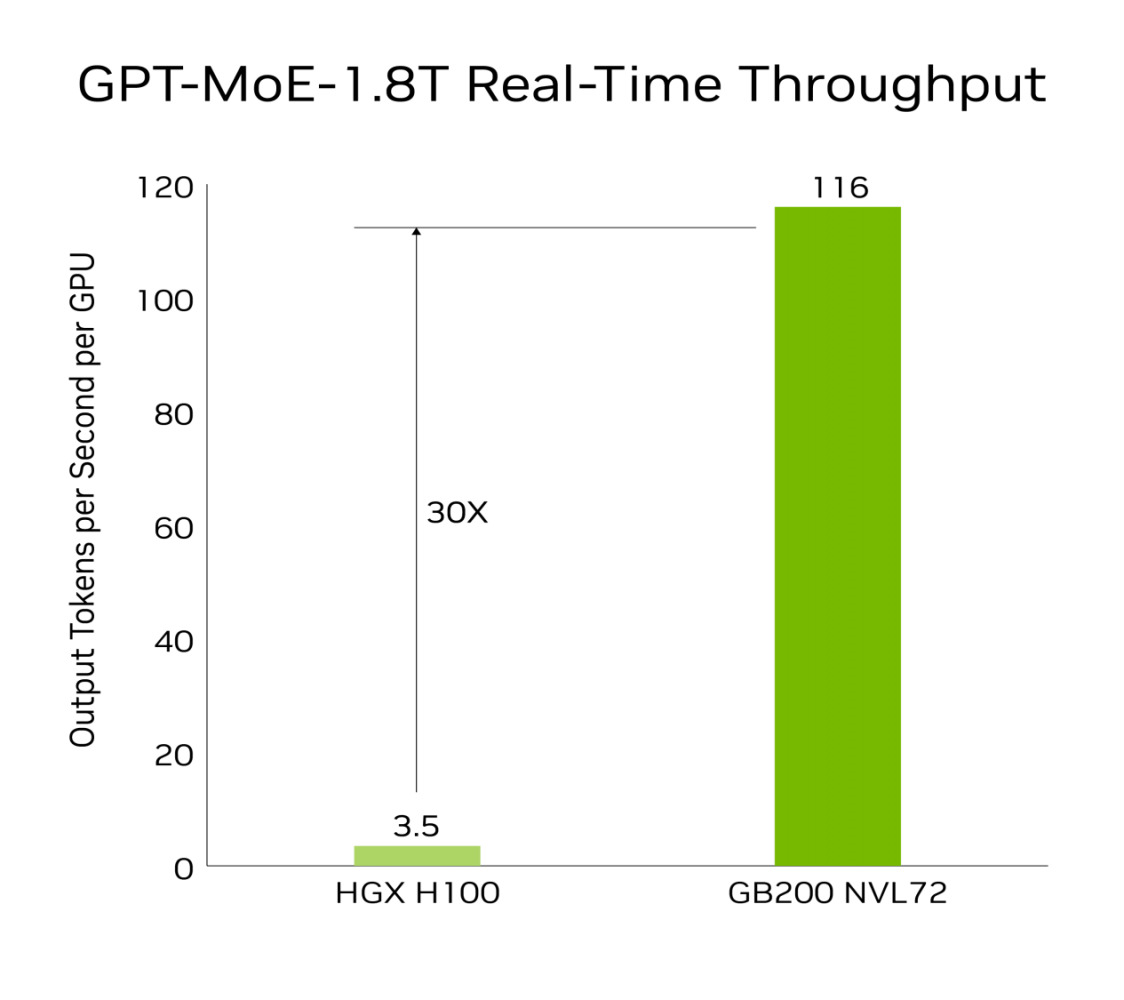
硬件配置、参数规格的提升使得英伟达新一代显卡性能实现了巨大飞跃。在推理方面,得益于第二代Transfomer技术。与相同数量的NVIDIA H100 GPU相比,GB200 NVL72可以为如GPT-MoE-1.8T这样的大型语言模型提供4倍的训练性能提升。相比于72个H100,GB200 NVL72推理性能提升30倍,成本和能耗降低25倍。在AI推理方面,GB200与上一代H100相比,对于资源密集型应用如1.8T参数的GPT-MoE,GB200可以提供30倍的速度提升。一个GB200 NVL72机柜可训练27万亿参数的模型,足以支持15个GPT-4模型。
三、引入硬件解压缩引擎,加速数据处理
企业会持续生成大规模数据,并依赖各种压缩技术来减轻瓶颈问题并节省存储成本,这需要硬件层面和基础软件层面同时提高。硬件层面包括高性能网络,高性能处理器,高性能服务器,高性能存储器件等。高性能网络包括InfiniBand和 RoCE(RDMA over Converged Ethernet)。高性能处理器层面,包括高性能CPU,如AMD、Intel的高性能服务器CPU等。基础软件层面,包括调度、存储、通信、编译、计算等各种基础软件。此类基础软件和高性能硬件的组合是高性能计算的核心部分。
为了在GPU上高效处理这些数据集,Blackwell架构引入了一个硬件解压缩引擎,为业界加速数据处理提供了借鉴与参考。该引擎能够在大规模上原生解压缩经过LZ4、Deflate和Snappy格式压缩的数据,从而加速整个分析流程。该解压缩引擎加快了受内存限制的内核操作,提供高达800GB/s的性能,并使得Grace Blackwell的查询基准测试比英特尔第四代至强快18倍,比NVIDIA H100 Tensor Core GPU快6倍。
在高达8TB/s的高内存带宽和Grace CPU高速NVlink-Chip-to-Chip(C2C)连接助力下,Blackwell架构引入的硬件解压缩引擎能够加快数据库查询过程,在数据分析和数据科学的使用案例中体现出较高性能,帮助企业介绍查询时间及成本。















