全栈,这种MCU玩法太有竞争力
时间:2022-06-21
作者:全栈MCU
分享
 扫码分享到好友
扫码分享到好友
在MCU生态发展大会商,小编听到一个“全栈MCU”概念!
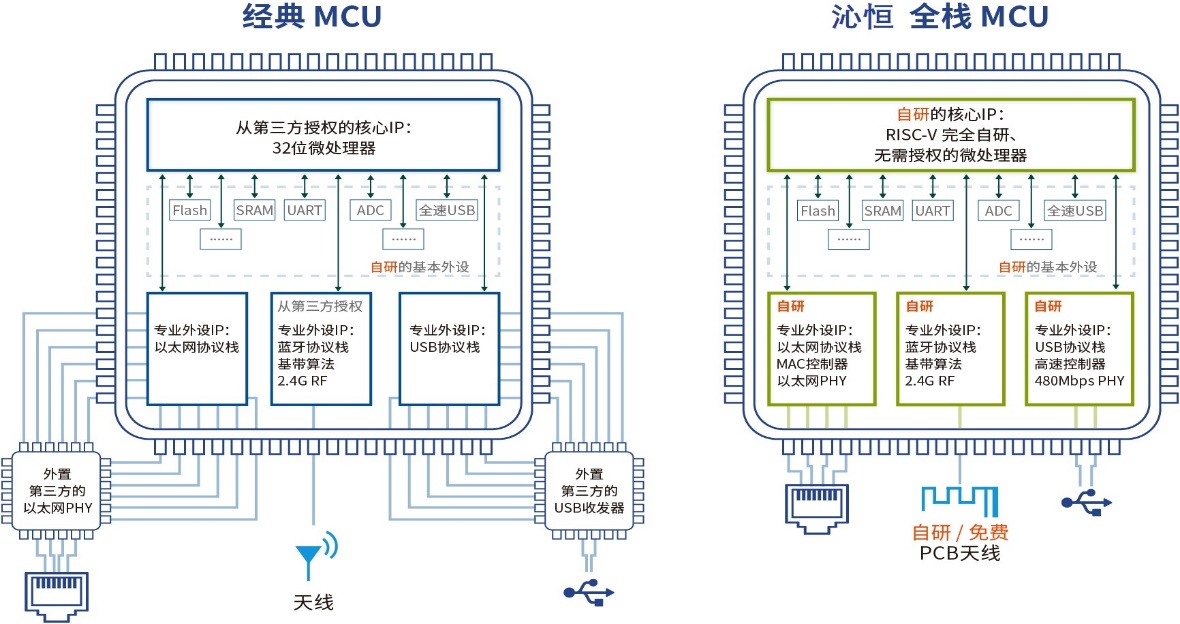
小编印象中,MCU设计分为上游的IP供应商和下游的MCU芯片公司。IP公司专业研究各种技术复杂、较难设计的IP模块,例如处理器IP和PHY等专业模拟接口IP;MCU芯片公司则采购处理器IP并加上其它自研的UART、ADC等常规模块,实现芯片整合,类似于PC机的产业分工。大家熟知的32F103和32F407等高性能MCU多数是购买ARM处理器IP、外置PHY或者购买第三方IP授权。
而“全栈MCU”说是处理器内核自己搞、蓝牙和USB高速PHY及以太网PHY这种专业接口IP也是自家研发、连蓝牙和以太网络协议栈及驱动程序也是自有的,完全用不着第三方IP,号称能节省第三方IP的授权费和每只芯片的IP提成费若干,能更实时响应中断和降低功耗,提升传输距离和速度。
带着疑问,小编采访了沁恒微电子公司的产品总监王晓峰。
王晓峰介绍,沁恒也用第三方IP,提成费用可以接受,行业做法是这部分费用增加到芯片成本,最终由用户买单,就是觉得不够灵活,没有“内核自由”,没法针对应用进行适配和整体优化,而且多方IP整合时存在资源浪费。后来一种架构更先进的RISC-V指令集出现,沁恒遂在原8位微处理器内核研发团队基础上扩建,投入32位RISC-V微处理内核研究,并于2020年首家推出基于自研RISC-V内核的通用MCU,型号是CH32V103,当时RISC-V内核的通用MCU在全球仅有一两家,是购买第三方IP整合的。
近年来RISC-V发展势头迅猛,生态越发成熟,MCU玩家成倍增加。现阶段大部分MCU厂家已经可以实现基本外设自研、内核国产可控。下一阶段比较难,是连内核也自研。王晓峰说,沁恒早期选择了一条最困难、最费时的处理器自研路线,现在看来,是非常值得的。他说,RISC-V不在于节省第三方IP的授权费和每只芯片的提成费,而在于掌握核心技术,便于与应用结合提升专业性,实现真正的处理器内核级别的自主可控,担负起对客户的长期保供承诺。毕竟百年大厦不能建在别人的沙滩上,PC机的发展历程历历在目,组装兼容机的电脑城几乎消失在历史进程中。
小编:你们是“内核自由”了,但MCU客户具体能得到什么呢?除了省点提成费之外。
王晓峰说,换成新架构的RISC-V内核后功耗更省、响应更快,这只是基础。WCH的核心竞争力还在于多年积累的连接技术,包括自研的USB高速PHY、以太网PHY、蓝牙收发器等专业接口IP,以及基带算法和网络协议栈,构建了物理层收发器+逻辑层控制器及基带+软件层协议栈的专业级垂直全链IP,加上处理器IP,打造出连接型/互联型/无线型的全栈MCU。
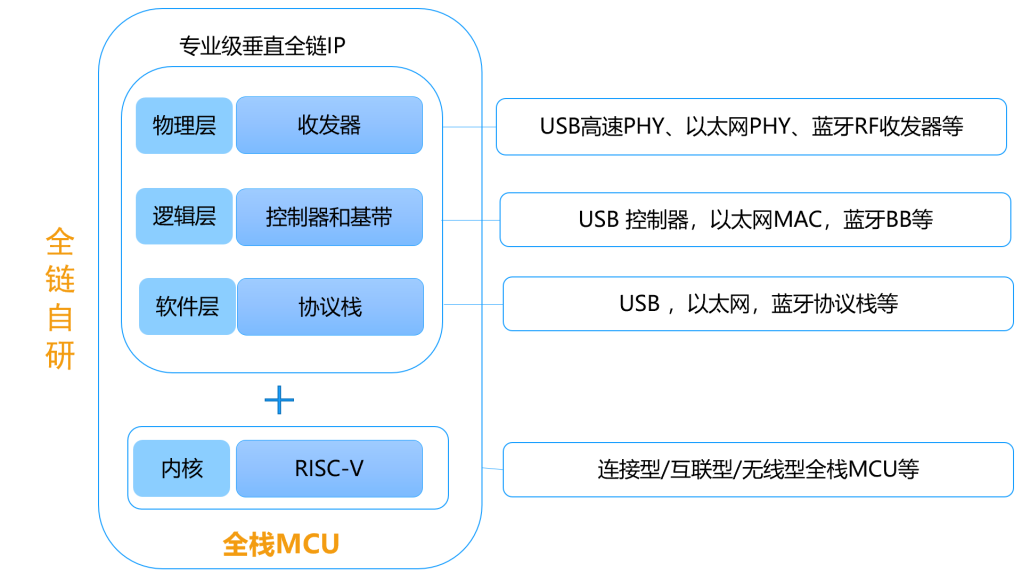
这种内部整合处理器、控制器、收发器、协议栈的“全栈MCU”相比多方购买IP整合、相比单提供物理层的第三方IP,具有更好的软硬件协同性,其内在结合、自成一体、各模块之间兼容性更好,表现为性能强、距离远、功耗低、响应快、体积小、成本低,具体来说。
1、全栈MCU相比外置PHY提升高频高速性能。举例来说,32F107虽然定位于互联型MCU,但是只有12Mbps全速USB、不支持480Mbps高速USB,32F107仅有以太网MAC、需外置以太网PHY;定位更高端的32F407和32F767也需外置以太网PHY和USB收发器,而且占用21个引脚。以USB为例,即使按手册加了外置的ULPI的USB收发器,实测速度仍然比全栈MCU的CH32V307低了很多。
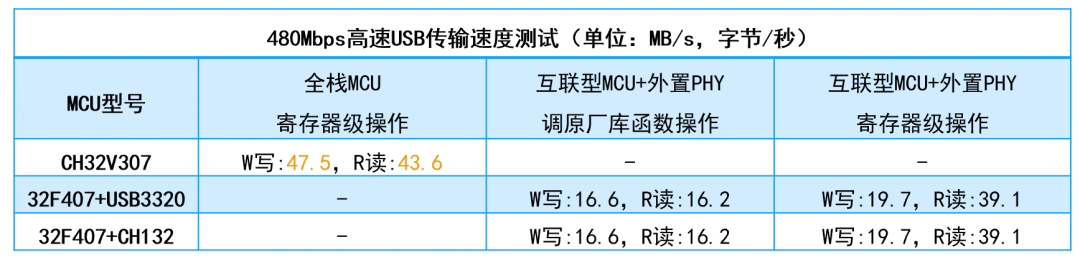
2、全栈MCU的自研PHY相比第三方IP增加传输距离。基于IP级USB技术,沁恒自研PHY并优化,合并共用模块、创建模块间快捷通道、垂直全链紧密衔接,将传输距离提升到了USB规范的两倍。自研的垂直全链IP还能确保更好的软硬件兼容性和协同性,网络协议栈和驱动程序适配了国内外各大主流操作系统和平台。
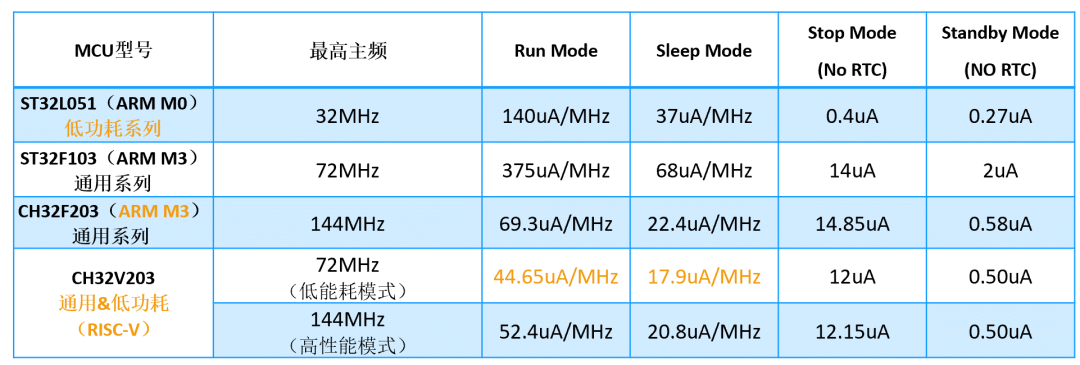
3、降低运行功耗。CH32V203与CH32F203存储和外设资源相同,但前者采用青稞RISC-V微处理器,实测运行功耗会比后者低20%,CH32V103与32F103资源差不多,实测运行功耗会比后者低30%。这种功耗优化得益于RISC-V架构更新和自研处理器时的内核级优化,不放过每一处可以优化的地方,而如果购买第三方的处理器IP,原则上不能改动,当然也不敢贸然改动那么复杂的处理器,就算想比公版设计降低5%都不容易做到。另外,动态功耗主要由高频信号线上的电容在高低电平切换时充放电造成,内置PHY的引脚电容只是外置PHY的10%以下,故整体功耗低。
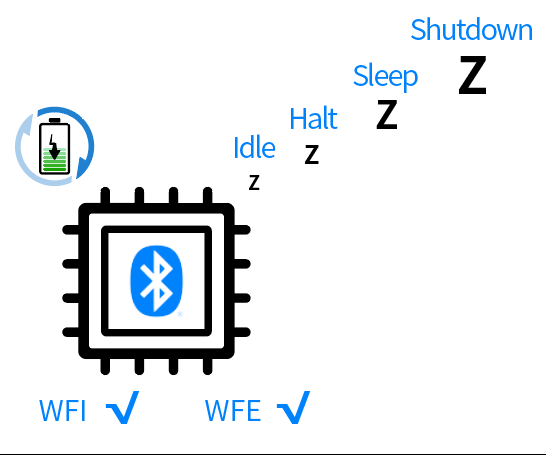
4、青稞微处理器首家支持WFE低功耗睡眠指令。其实ARM架构有WFE指令,但RISC-V最初不支持,原因是官方标准没有定义,导致睡眠响应略差,睡眠功耗偏大。沁恒多年研究低功耗的BLE蓝牙MCU芯片,最早注意到这个应用需求,对自研的内核进行扩展优化,在首版青稞微处理器中就支持了WFE指令,降低了睡眠唤醒的功耗。
5、内核级优化提升实时中断响应。沁恒在设计USB3.0等高速芯片时,面对数据量大、状态和控制灵活且多的情况,前者采用高带宽多层DMA自动处理,后者则需要深入微处理器内核改进中断控制器及流程,基于HPE和VTF技术创新解决方案,最终得到更快速的实时中断响应,相比当时的第三方RISC-V提速到3倍,相比经典32位MCU提速到1.6倍。这样对于对于高性能工业应用,可以获得更快的中断响应和实时处理。
6、首创RISC-V高速2线调试接口。在CH32V103面市之前,主要RISC-V处理器IP的调试方案是低速的4线调试接口,萝卜快了不洗泥,终端用户体验不佳。而沁恒在首版青稞微处理器中就提供2线调试接口,相比当时的4线调试接口提速到3.8倍并节省一半引脚,引导了RISC-V通用MCU采用2线调试接口的潮流。

7、全栈MCU相比外置PHY节省I/O引脚,减小芯片体积和节省封装费,减少PCB走线降低整机EMI,紧密结合的单芯片架构还能明显降低整体功耗。
8、既兼容又扩展。出于生态兼容、降低学习成本、产品开发延续性考虑,通常用户会优先选择x86、ARM、RISC-V、8051等主流指令集。青稞处理器支持RISC-V标准指令集,支持业界主流操作系统和主要RISC-VIDE,用户可享受主流的RISC-V开放成熟生态。同时,WCH深入研究应用需求,扩展了一些有价值的新指令,配套MRS开发工具,发挥更佳性能。青稞处理器提供内核手册,能够长期直接响应用户的内核级需求,不至于链接到第三方IP供应商那里。类似地,USB和以太网PHY也是既支持业界标准,又扩展了距离或其它性能。结构上32V208则是基于F103、F107扩展了蓝牙。
小编:既搞处理器又搞收发器,会不会太辛苦?
王晓峰说,处理器IP和高速接口IP确实复杂,需要专业经验和多年研发,不然MCU芯片公司也不会心甘情愿向IP公司付费。做全栈MCU,得定位成IP级芯片公司,是很难,但这是沁恒工程师的专业追求。第三方IP比较成熟,标准设计,无法针对应用优化;而且各PHYIP形状不一、衔接不便、可能浪费面积增加成本。
我们有些工程师可能有强迫症,看到可以提升30%速度、看到可以降低20%功耗、看到可以帮客户节约15%成本,就坚定不移的去优化改进,谁也不忍心阻止他的进取。有个工程师在研究以太网MCU芯片时,注意到常用的网络协议栈编译后目标代码较大,分析其汇编程序,发现大量的字节和半字的读写指令,随即反馈给处理器IP设计团队,研究多种应用的共性需求,最终在青稞V4内核中扩展了字节和半字压缩指令,提升了代码密度,属RISC-VMCU业界首家。
类似情况很多,不满足于基本款,不坐在办公室里闭门造车设计IP,而是了解并研究应用,在应用中发现新需求,再深入芯片架构底层进行适配优化和改进,让产品更趋完善,将技术创新转换为客户的价值,为客户带来便利!
当前大部分8位MCU并没有用第三方微处理器IP,我们认为全栈MCU不算是新玩法,当条件成熟,业界都打算自研32位微处理器、自研PHY等高速接口IP并提供协议栈时,自然就都是全栈MCU,现阶段下,全栈MCU只是一种基于趋势的选择!
小编独白:太卷!















