瞄准未来IP网络,挑战高性能路由器设计
时间:2006-06-15
作者:James Chen, Jimmy Zhou, 陈佳, 周志明
分享
 扫码分享到好友
扫码分享到好友
对于依靠代理网络游戏《传奇》走红之后押宝“家庭互动娱乐”的上海盛大网络发展有限公司来说,2006年4月18日可能是一个令他们感到沮丧的日子。这一天,他们忍痛宣布放弃投入了巨资的“盛大盒子”计划。事情缘起于中国的广播电影电视主管机构——国家广电总局向中国电信和中国网通等两大电信运营商发出函件,明确以上海盛大为例,称凡是未获得许可证而把互联网内容搬上电视机的行为,均在被叫停之列,要求两运营商不提供网络接入服务。
“盛大盒子”计划的夭折,折射了广电部门针对IPTV业务迅速发展对自身利益带来挑战的忧虑。市场研究机构Strategy Analytics预计,2006年IPTV全球业务收入将达到80亿美元,用户数将达到800万以上。而在中国,由于PC、手机、电视机用户规模均居全球前列,为中国IPTV发展打下了坚实的基础。艾瑞市场咨询日前发布的《2005年中国IPTV市场研究报告》指出,中国IPTV市场的发展将会十分迅速,在2004年1.3亿元和2005年6.1亿元人民币的基础上,预计2006年将达30亿元,而到2008年更将达到148亿元的规模。
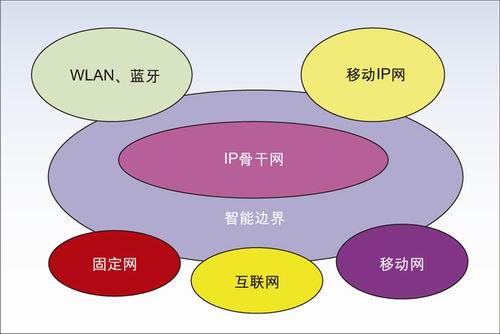
可以看到,随着VoIP、IPTV等IP业务的迅速增长,应用的不断增加,IP网络正在向下一代网络演进,其网络协议也产生重大变化,正从IP地址空间紧张的IPv4向在IP地址量、安全性、服务质量和移动性等方面优势明显的IPv6演进。而为了推动下一代网络的发展,中国启动了中国下一代互联网示范工程(CNGI项目),参与者都已经提出计划或正在推出不同的应用,如中国电信CNGI上IPv6 的应用场景具体内容包括永远在线、随处可见的网络(非PC设备的连接)、简单的即插即用、增强的内置安全、自由移动、新的通信模式等,目标是将IPv6作为实现"无所不在"网络应用的重要后台支撑技术。中国联通、中国网通/中科院、中国移动也各自提出了其CNGI上的IPv6应用。
 |
赛迪顾问市场分析师张菊表示,在这些业内纠葛或举措的背后是运营商已经达成共识—用户的习惯或需求是未来趋势的最终决定者,于是固网运营商和移动运营商纷纷希望赶在下一轮网络高潮之前准备好一张崭新的、能够承载未来的IP网络。她认为,运营商IP承载网的新一轮建设高潮已经来临,相应的,中国路由器市场在2008年将会迎来下一个增长高峰,届时市场规模将达126.1亿元人民币,约是2005年市场规模的1.6倍,未来三年的年复合增长率将高达17.1%。
不管是三重业务(Triple Play)、NGN或IPv6,它们都对网络性能和服务质量提出了更高的要求。PMC-Sierra公司通信产品部营销与应用副总裁Dino Bekis表示:“随着服务提供商开始部署三重业务,网络设备必须满足用户对语音和视频的质量与可靠性的期望。特别是随着向全IP网络迁移的趋势,路由器需要增加新的特性和功能。”
另一方面,随着光传输和光交换新技术的发展,比如密集波分复用(DWDM)和使用了MEMS技术的光交叉连接(OXC)交换系统在主干网络的广泛应用,每12个月光纤链路容量就增加一倍,这使得传输和交换的带宽轻松进入petabit的级别。随着光传输和光交换成本的不断下降和带宽的不断提高,对网络的中枢-路由器的性能要求也越来越高。
高性能路由器设计的技术挑战
设计高性能大规模路由器的关键问题是要具有成本效益,路由器容量能够扩展达到petabit级别。很明显,构建这样大规模路由器的复杂性和成本远远高于构建光交叉连接(OXC)交换系统。这是因为在数据包的交换过程中需要处理数据包(比如分类、表查找、数据报头修改),并且要对数据包进行存储,调度并执行缓冲管理。随着线速的提升,与每个数据包相关的存储和调度时间也按比例减小。而且随着路由器的容量提升,解决输出竞争的时间也越来越受到限制。在设计大容量数据包交换时,对存储器和互连技术的要求是最苛刻的。存储器速度经常成为大容量数据包交换的瓶颈,而互连技术极大地影响了系统的功耗和成本。因此设计一个好的交换结构,其巨大的交换容量能够扩展,并且还要具备成本效益,在如今是个很大的挑战。
1)存储器的速度和容量
如今光电器件的工作速度达到了10Gb/s(OC-192),并且对工作在40Gb/s(OC-768)的光纤的需求也在产生。而端口到交换结构的速度通常要达到线速的两倍。这是为了克服输出竞争的不完美的仲裁和用来执行路由、流控和数据报头/信元头的QoS信息引起的开销。因此,交换接口的总存储器I/O带宽可能达到120Gbps。对于40个字节的数据包,每个端口的缓冲存储器的周期时间需要低于2.66ns。这对于如今的存储器技术仍然是个很大的挑战。与此同时,需要的存储器容量很大,很难集成进如流量管理器或其它的交换接口芯片的ASIC中,这也会影响速度。此外,缓冲存储器的管脚数可能高达好几百,从而限制了与ASIC相连的外部存储器芯片的数量。
2)数据包的仲裁
仲裁器是用来解决发生在输入端口间的输出端口的竞争。对于一个40Gbps线速、传输40字节大小数据包的交换接口,考虑到输出端口两倍的速度提升,仲裁器只有4ns的时间解决输出竞争。随着输入端口数量的增加,解决竞争的时间不断减少。数据包仲裁可以用集总的方式解决,这时仲裁器和所有输入线卡/端口卡间的互连会异常复杂和昂贵。如果用分布的方式,线卡和交换板都会参与仲裁。这会降低吞吐量和延迟的性能。因此,需要在交换结构上提升速度以改善性能。
3)QoS控制
与上面提到的数据包仲裁问题相似,随着线卡速度的提升,在输入端口执行策略/整形和在输出端口进行数据包调度,缓冲管理(丢弃数据包策略),以满足每个流和每一级的QoS需求非常困难和具有挑战。每个线卡的缓冲大小通常需要保持100ms时长的数据包,对于40Gbps的线速,缓冲器需要500MB的大小以保存几十万个数据包。要在4-8ns内选择一个数据包脱离或丢弃不是一件小事。此外,为了实现每个流控而保持的状态的数量可能极其昂贵。还有一种方法是执行基于类的调度和缓冲管理,这在核心网更加切合实际,因为流的数量和连接速度实在太高了。有几种整形和调度机制需要对到达的数据包加上时间标记,并基于时间标记的值调度数据包的脱离。在4-8ns的时间内选择具有最小时间标记的数据包也会产生性能瓶颈。
4)光互连
大容量的路由器通常需要多个机架以容纳全部的线卡、接口卡(可选)、交换结构板、控制板(如路由控制器,管理控制器,时钟分配板)。每个机架根据线卡和交换结构板的密度可能容纳0.5-1Tb的容量。其还需要在每个方向与另外的具备0.5/1Tb容量的机架进行互连。借助如今的VCSEL技术,光收发器可以用12个SERDES通道传输300m的距离,这广泛地用于背板互连。然而,这些光器件的大小和功耗可能限制了每块电路板上互连的数量,从而导致了更高数量的电路板和更高的实现成本。而且,需要大量的光纤来互连多个机架。这增加了安装成本并使得光纤重配置和维护非常困难。光纤的布线需要仔细的设计以减少人工失误引起的潜在中断。安装新的光纤以提升路由器的容量很容易出错并中断现有的服务。
5)功耗
因为SERDES技术容许在一个CMOS芯片上容纳超过100个双向通道,每个通道工作在2.5或3.125Gb/s,该芯片的功耗可能高达20W。使用VCSEL技术,每个双向通道可能消耗250mW的功率。假设我们要在机架间的互连上实现1Tb的带宽,这就要在光纤互连上消耗总共1000W/机架的功耗。而每个机架由于散热的限制最高只能几千瓦的功耗,这反过来又限制了每块卡上元件的数量和每块板上卡的数量。大的功耗也会增加房间的空调的成本。
作者:陈佳、周志明
电子工程专辑















