OPTION_5:HP
整机系统的功能越来越强,推动了集成电路复杂度的不断提高。尽管我们看到包括物联网等应用对半导体工艺的要求仍维持在28nm至65nm的区间,但无疑,对一些领先或想领先的半导体厂商而言,对16/14/10nm甚至更低的工艺却有无法停止的追求。
而且,以CPU、GPU和网络芯片为代表的超高集成芯片,对工艺、系统仿真、以及IP有更复杂的需求。
在Globalpress组织的硅谷行中,访问的两家公司Mentor Graphics和Arteris就是在硬件仿真以及IP领域颇具代表性的公司。
本次美国行第三部分的故事就以他们展开。

图:Mentor Graphics美国总部。
为什么以太网入了Mentor的法眼?
Mentor在10多家亚太和欧洲媒体面前推出了支持25G、50G和100G以太网的Veloce VirtuaLAB Ethernet环境。
“除了CPU和GPU以外,网络芯片也是最复杂的芯片设计类型,”Mentor Graphics仿真部市场总监Jean-Marie Brunet表示,“在CPU和GPU方面我们已经做了很多的工作,网络芯片成为我们这次的关注点。”

图:Brunet在演讲中。
从应用需求来看,数据中心、云计算、存储网络、社交网络、视频应用以及日益巨大的城市网络,都对以太网芯片提出了更高、更严格的需求。
而从网络的带宽发展来看,25G、50G、100G,甚至400G都在一定的应用场合中得到和开始得到广泛的应用。
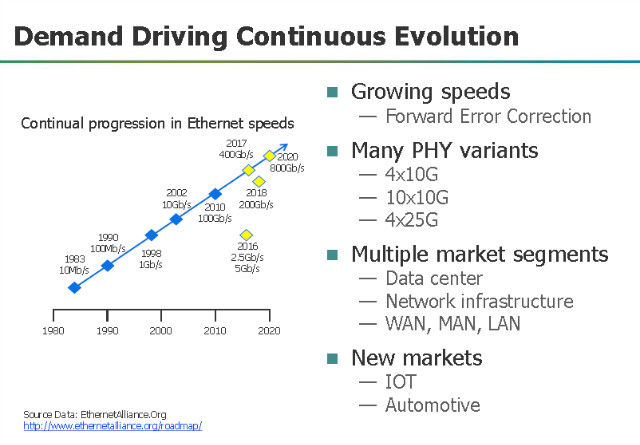
图:网络带宽的发展趋势。
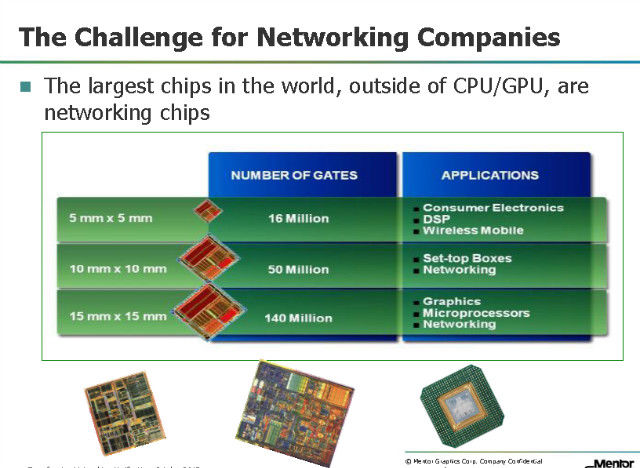
图:网络芯片正在遭遇的挑战。
“网络的大提速使其芯片复杂度急剧提升,这对芯片设计公司带来的压力可想而知,”Brunet继续分析到,“相应地,这对芯片的验证能力带来了全新的需求。”
“对芯片整体而言,包括早期阶段的软件,进行快速验证是芯片设计者所需要的。”他表示。

图:以Juniper公司为例,所需芯片的复杂度。
本文下一页:Veloce VirtuaLAB Ethernet环境
{pagination}
Veloce VirtuaLAB Ethernet环境
这是Mentor针对以上设计需求和应用挑战最新推出的以太网芯片设计解决方案。
“传统的模拟验证方式已经无法满足网络芯片发展的速度,而以前的基于实验室的方式也大大受限。”Brunet分析到,“现在是时候转移到新的策略上了。”

图:基于实验室的早期方案。
涉及到网络芯片设计的领域包括三个方面。一是容量,网络芯片会达到10亿万门的量级;二是速度,需要加速仿真;三是实验室虚拟化。其中,实验室虚拟化(Lab Virtualization)是Mentor提出的一个新技术词汇。
“验证将由模拟(simulation)转向基于仿真(emulation-based)的流程方法。”Brunet总结到。

图:从模拟至仿真的变化和比喻。
“VirtuaLAB Ethernet通过用虚拟器件替代了用于在线仿真(ICE)的传统物理器件,改变了网络芯片的仿真方式。这种虚拟化使仿真从工程实验转移到了计算数据中心,以实现最大的仿真资源利用率。”该公司仿真部解决方案市场经理Neil Mullinger给出了具体的解释。
据称,VirtuaLAB组件提供了超过传统模拟速度15,000倍的性能,运行完整软件驱动的以太网协议栈。
“这个新的协议可以支持验证今天复杂的基于以太网的设计,”Mullinger表示,“新的仿真方式可动态地改进验证的吞吐量,达到每天运行1,100万个数据包,而以往的模拟方式每天只能运行1,000个数据包。”
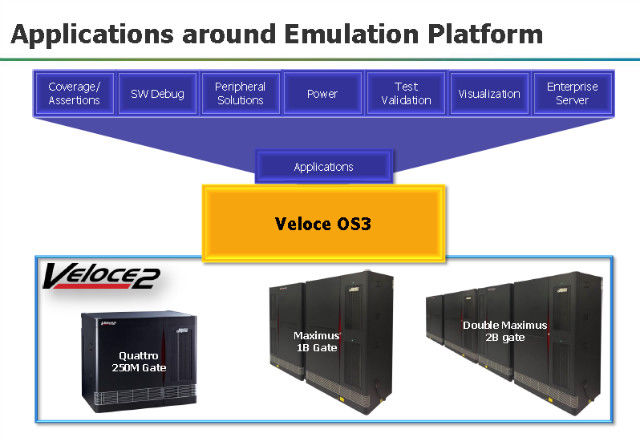
图:VirtuaLAB可运行在Veloce II硬件加速平台。

图:数据中心支持多用户、远程仿真。

图:用户实例。
本文下一页:Arteris:独具特色的自动pipeline插入IP
{pagination}
Arteris:独具特色的自动pipeline插入IP
这是第二次面对面地了解Arteris推出的新IP。第一次接触该公司时就对他们的FlexNoC在片网络互连IP非常欣赏,这次带来的利用SoC互连IP改善芯片物理布局的介绍仍然令我眼前一亮。
FlexNoC Physccal互连IP主要是解决随着芯片设计复杂度的增加如何更好优化芯片内部互连的IP。
“进入到28nm甚至更低的节点时,芯片内部互连的挑战日益明显,”Kurt Shuler,Arteris市场部副总裁,在演讲中表示,“这时,架构设计师们需要去想象SoC架构的物理影响,TL级工程师手工增加pipeline可能花费数个月的时间,而同时,布局工程师提供的内部互连IP在RTL级时可能并没有经过物理验证。”
按照他的分析,布线中的阻容参数和门延迟都会使内部互连变得复杂万分。

图:Kurt Shuler。
Arteris本次推出的FlexNoC Physical互连IP就是将以前的手工加入pipeline方式进行自动化,使芯片尽快满足时序收敛的设计需求。
那么,如何做到自动增加pipeline?
简单的解释就是对布线路由进行分析,自动改变路由布局,以实现时序收敛的目的。
以下三张图会更详细地帮助你理解这个IP是如何工作的。

图:隔断NoC物理instance。
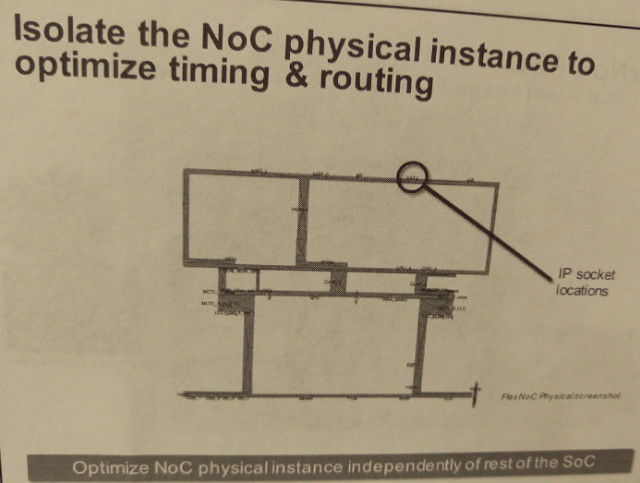
图:优化NoC物理instance。

图:自动增加pipeline。
你可能会问:增加了pipeline,芯片裸片(die)的尺寸是否会变大?是的,但你必须在时序收敛(以保证芯片能满足设计功能)和芯片尺寸之间取得平衡,而最佳的结果无疑是两者能实现最优折衷,而前提是保证芯片能正常工作。
下面的这张图给出了无pipeline、全部放置pipeline、以及自动插入pipeline三种条件下裸片面积和时序是否收敛的对比。

图:不同条件下的结果。
“如果采用手工操作,可能需要数月的时间,而采用该IP,时间将缩短到小时的量级,而芯片面积与过度加入pipeline的设计相比也会节省10~15%,”Shuler最后总结到。
END
本文为《电子工程专辑》原创,版权所有,谢绝转载
















