使用Xtensa可配置处理器设计打印机SOC芯片的图像处理管线
时间:2008-01-17
作者:Sumit Gupta
分享
 扫码分享到好友
扫码分享到好友
高质量彩色打印机在家庭中越来越普及。一般来说,打印机都是随着PC电脑一起购买使用。但随着需求的变化,这种情况正在改变,其中数码相机是促进这种变革的最大因素,消费者希望可以通过数码相机将相片直接打印出来。在这个过程中,只需要通过USB接口将数码相机拍摄到的相片传入到打印机中就可以直接打印,而不需要再经过计算机处理。
这种消费者的需求使得打印机的基本原理在发生变化,原来由PC准备需要打印的文档,打印机只负责打印,现在这些工作都需要由打印机全部完成。这就需要打印机提供更加强大的图像处理功能。如今,打印机允许消费者直接通过CD或DVD打印图像,就像通过数码相机和数码摄像机一样,并且提供一个LCD显示屏供使用者在打印前进行预览。
厂商一方面需要不断提升打印机的图像处理能力,另一方面也面临着巨大的成本压力,因此大部分功能需要尽可能的集成到一块芯片中完成。此外,从成本考虑也不可能为每款打印机单独设计不同的SoC芯片,因此需要一次设计可以满足多种款式打印机的要求。 打印机SoC芯片中一般会有一个系统控制处理器,用于协调图像处理功能和打印控制功能。打印控制功能一般有几个小的微控制器实现,用于控制打印机针头的速度和方向。在图像处理方面则由以前使用的硬件连线RTL转向使用多个DSP处理器。
基于可编程处理器的图像处理
功能的灵活性需求使得打印机SoC芯片的设计者往往选择可编程平台作为图像处理管线的基础。与硬件连线的RTL模块相比,使用处理器可以提供更多的灵活性,支持更多的算法实现,并且通过软件就可以进行升级和优化。例如,对于打印机中的半色调(half-toning)算法即使在打印机芯片被设计出来以后也可以不断地优化。处理器的可编程性可以支持不断更新的图像压缩算法,并且可以通过软件修复原有设计中的一些缺陷,而不需重新设计芯片。 此外,基于处理器的SoC芯片可以应用于不同类型的打印机设计中,根据不同的需求开启或屏蔽芯片中的一些功能,通过这种方式可以大大节省打印机厂商的成本。 最后,通过简单的增加或减少SoC中的处理器我们可以开发出更多不同的芯片。
使用可配置处理器获取比定点DSP处理器更高的性能
可编程处理器,例如Tensilica 公司的Xtensa 处理器,已被广泛应用于多种喷墨打印机和激光打印机设计中。大型打印机制造商中有四分之三在打印机SOC中使用了Xtensa处理器。
Xtensa处理器允许架构设计师针对特定任务设计专用的DSP处理引擎。考虑如图1所示的打印机SoC原理示意图。在这个例子中,采用了多个Xtensa处理器来完成不同的功能,如JPEG解压缩,图像增强,色彩处理等等。
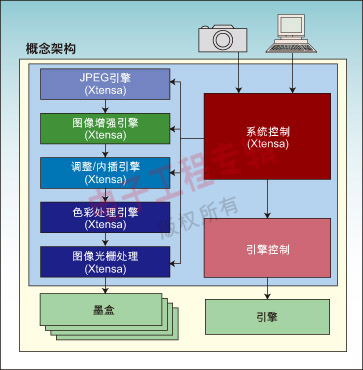
图1:打印机SoC芯片原理示意图。
运用Xtensa处理器独特的功能,可以为特定应用设计专有指令,从而裁剪出最适合的处理器功能。因为每一部分都是针对需要实现的功能而设计的,没有多余的指令和功能,所以与一般的DSP处理器相比效率更高,面积也更小。
采用Xtensa处理器实现图像管线的优势
除了自身的可编程特性以外,在打印和图像处理设备中使用Xtensa处理器具有下面5大优势:
1. 通过在Xtensa处理器中增加特殊图像处理指令来创建特殊任务引擎:这些指令可以在各种相似的算法中重复使用。同时,因为处理器中不需要增加非任务性专用指令,所以DSP可以说是为这些任务量身定做的。这种DSP可以轻松获得通用DSP处理器无法获得的性能水平。和硬件连线的RTL模块相比,在面积和功耗上面因而也具有很强的竞争优势。
2. Xtensa处理器能以极具竞争力的面积和功率指标获得接近RTL的性能:Xtensa处理器的基本内核实现只有大约2万门左右,设计师做的扩充部分可以被正确地插入处理器管线中,其门数量通常与RTL实现接近相同。另外,通过扩展面向图像处理优化的专用指令,不需要提高主频,也不要求非常高频的深度管线(这样做极耗面积)就能显著地提高性能。 因此,总体面积要优于硬件连线的RTL模块。在功耗方面,在设计师完成Xtensa处理器的优化后,Xtensa处理器的生成器可以自动在处理器管线中插入超细颗粒的门控时钟,设计师不需要做任何事,一切完全自动执行。这种方式可以比一般的RTL模块更节省功耗。
3. 为专用指令扩展提供优秀的编译器和软件工具链支持:一旦设计者确定了新的专用指令,Tensilica 的Xtensa C/C++编译器(XCC)和其他的软件工具链可以立即自动更新,以支持新增加的指令,这些指令在应用程序代码中以C原语(函数调用)的形式使用。 XCC编译器自动调度设计师定义的指令,并根据设计师定义的寄存器文件进行寄存器分配。指令仿真器(ISS)可以用于对新增加的指令进行仿真,完善有关多周期操作的时序信息。调试器则显示新指令以及在用户定义寄存器和寄存器文件中的值等信息。
4. 比RTL实现更快的上市时间:采用Tensilica 的设计方法学,设计一块新的功能模块在时间上比RTL模块要短很多。因为新的专用指令采用高层次的TIE(Tensilica Instruction Extension )语言来定义。TIE 语言与Verilog语言比较类似(支持C数据类型),不过设计者只需要定义操作的功能而不需要定义架构实现。这使得设计非常容易验证,因为只需要验证输入与输出之间的关系,不像RTL实现那样,不仅需要验证功能,还需要验证架构实现。 Tensilica 可以保证根据设计师的TIE描述产生的处理器RTL实现是预先验证过的,与硬件连线的RTL模块开发相比,这样做大大简化了验证过程,从而缩短了上市时间。
5. 可以实现灵活高效的图像处理管线:Tensilica 技术具有专门针对图像处理应用的多种优势。特别是Tensilica 的Xtensa LX 2处理器能够创建复杂的指令集,使处理器成为多时隙超长指令字(VLIW)处理器。 设计者还可以添加可变宽度的单指令多数据流(SIMD)操作。设计师还可以通过在处理器上增加定制I/O端口和FIFO接口戏剧性地重建芯片上数据流。
案例分析:使用误差扩散(Error Diffusion)算法实现半色调(Half-Toning)打印
下面例子可以很好地说明Xtensa 处理器在图像处理中的应用,这个例子采用了Xtensa 处理器实现Floyd Steinburg 误差扩散算法。
在图像处理器中一个很重要的步骤是进行图像量化。然而,图像量化会引入亮度误差,因为一个灰阶的像素会被量化成黑色或白色。这些亮度的误差可以通过向邻近的像素点扩散来减少。这就是所谓的误差扩散算法。其中Floyd -Steinburg 算法是这些算法中比较常用的。这些不同的算法被广泛应用于当今的打印机当中。
如图2所示,Floyd -Steinburg 算法将量化误差向邻近的像素点传播。 从图中伪代码中可以看到,首先计算第一个误差,然后将小数部分与邻近的像素误差相加。注意这些像素的误差此时还没有计算出来。
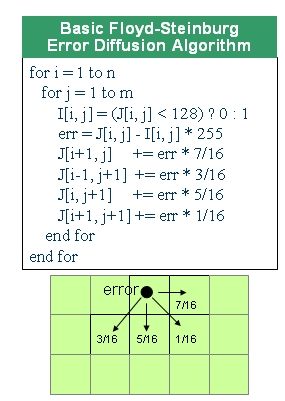
图2: 基本Floyd -Steinburg 误差扩散算法。
误差的计算和误差的扩散可以并行执行,如图3所示。图中,“X”表示正在处理中的像素点,像素周围的数字是要存储中间结果的寄存器号码,如果这些计算准备结果映射到一个Xtensa 处理器上。
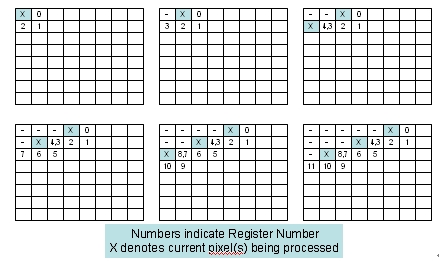
图3:在8x8图像中同时进行量化误差计算和误差扩散运算。
这种像素的并行处理类似于运算波阵面。对如图4所示的一个8x8图像模块来说,最多可以处理4个像素点。值得注意的是,最多需要15个寄存器来保存中间结果。
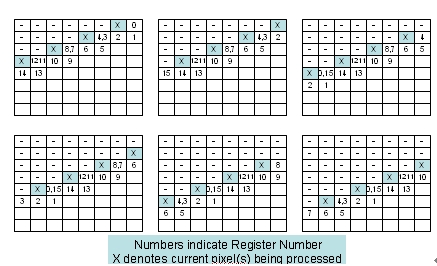
图4:误差扩散运算的稳定状态,最多可以并行处理4个像素点。
将误差扩散算法映射到Xtensa处理器
将Floyd -Steinburg 误差扩散算法映射到Xtensa 处理器时,首先需要建立一个16入口的寄存器文件,这在TIE语言描述中只需要一行简单的语句,比如“regfile myReg 816mr ”。该语句创建了一个16入口8位寄存器文件,命名为“myReg”,缩写为“mr”。TIE 编译器同时创建一个名为“myReg ”的C数据类型与该寄存器文件对应,使得“myReg ”类型的变量可以在C/C++代码中声明。XCC编译器再将这些映射到寄存器文件的变量进行自动分配。
我们可以采用创建两条用户定义TIE指令的方法来生成计算误差和扩散误差的功能单元。第一条指令用于计算误差,并将误差与来自邻近像素的扩散误差值(保存在myReg寄存器文件中)。注意在像素被装载后这些误差只需要加一次:
TIE 指令 1: error = ComputeError() + mr0 + mr15
其中mr 0和mr 15是用于保存来自邻近像数误差的寄存器。它们通过这条TIE指令与当前像素误差相加。
第二条指令用于计算影响相邻像素的扩散误差,中间值保存在myReg寄存器文件中。针对每个像素需要为邻近的4个像素进行计算,并且需要累加上邻近像素点传递过来的误差。该指令如下:
TIE 指令 2: mr0 = e.α + mr14; mr1 = e.β; mr2 = e.γ + mr1; mr3 = e.δ + mr2
其中“α,β,γ,和δ”是误差的小数部分(对于Floyd -Steinburg 算法而言,它们分别是7/16,3/16,5/16,和1/16)。Mr 14、mr 1和mr 2是已经处理过的像数扩散误差。注意这些小数的计算可以采用乘法和移位来实现,不需要使用除法。例如,除以16可以用向右移4位来实现。
这两条指令对应的操作如图5所示。

图5:组成两条TIE指令的分步操作。
像素数据的装载与保存
对于一个8x8的图像模块,需要使用64位的数据装载(load)和保存(store)。Xtensa LX 2处理器支持每周期并行执行2个128位的load/store操作。首先,创建一条“Load64”指令和一条“Store64”指令,用于装载和保存64位(8个像数)的数据。先执行Load64指令,然后计算第一个像数,将误差保存在“myReg”寄存器文件中。然后计算下一个像数的误差,同时装载下一行的像数点。这个过程持续到第一行的像数计算完毕。然后执行Store64指令。整个计算、保存误差和装载下一组像数的过程如图6所示。从图中可以看出,当处于稳定状态时,4个像数点的误差同时计算。这意味着需要4个上面提到的基本TIE指令副本(也就是说存在4套进行误差计算和扩散的功能单元)。
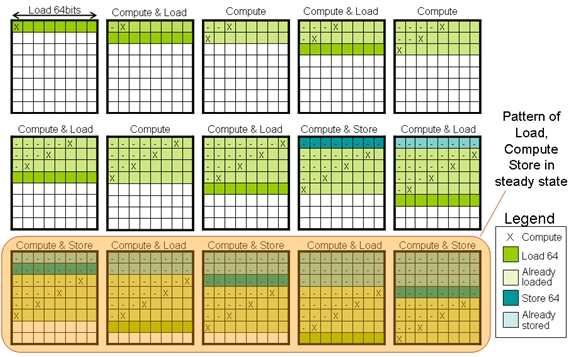
图6: 计算误差与装载/保存64位数据(8像数) 同时并行。不用多久计算、装载和保存就能进入正常模式。
更大图像模块尺寸和其他算法的扩展
上面提到的基本误差扩散算法的实现架构可以很容易地扩展到16x16、32x32或者更大的图像模块尺寸。Xtensa处理器中的两个Load/Store单元可以用于完成128位数据的装载/保存,FIFO接口则可以用于处理器管线之间的数据流传送和接收。更大的图像需要更多的并发误差计算,图7是16x16图像模块的例子。
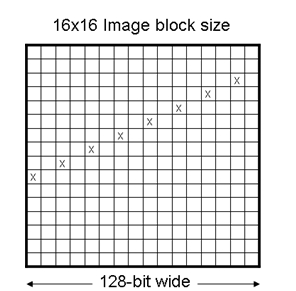
图7:在16x16图像中最多可同时处理8个像素点。
除了Floyd -Steinburg 算法以外,还有其他的一些变化算法可以使用,例如Jarvis ,Judice和Ninke,它们将误差扩散到更宽范围的像素来获得更好的抖动性能,如图8所示。通过在TIE中增加更多的误差计算,可以完全避免增加硬件连线的RTL模块。

图8:更复杂的误差扩散算法例子。
案例研究:爱普生公司采用Xtensa处理器实现打印机SoC
日本爱普生(Epson)公司成功将Xtensa 处理器用于其REALOID 打印机SoC芯片设计中。在过去几年中,Epson 公司设计的芯片复杂性不断提高。当Epson 公司在考虑其最新的体系架构时,他们希望该架构可以在未来几年的打印机型号上使用。这需要该架构具有足够的灵活性,因为图像算法不断更新,特别是半色调算法,经常需要优化以改善性能。同时Epson 的开发团队还希望设计的SoC芯片留有一些空余的空间用于未来更复杂算法的实现。
起初,Epson公司考虑采用硬件连线的RTL实现方案,该实现需要几百万门。然而,这个解决方案无法满足灵活性和可编程性的要求,并且需要进行大量的验证工作。最后,他们决定采用Xtensa 处理器作为硬件连线RTL实现的替代解决方案。采用可编程处理器在保证高性能的同时提供了良好的灵活性和可扩展性。
Epson 公司采用多个Xtensa 处理器设计了一个可扩展的架构。当算法的复杂度和产品需求增加时,他们可以通过简单的增加Xtensa 处理器来满足这些要求。
在REALOID 芯片中Xtensa 处理器采用系统总线和FIFO与存储器和其他处理器之间进行通信,这些通信机制完全采用Tensilica 的TIE语言进行描述。Xtensa 处理器还使用TIE描述的端口进行相互的控制信号通信,相当于一般处理器核中的GPIO。这些队列和端口接口可以被数据通路采用像“Pop_Queue”和"Write_Port"这样的指令直接访问。通过这种方式,不同的Xtensa 处理器之间的数据传输不再受到Load/Store单元和系统总线的带宽限制。
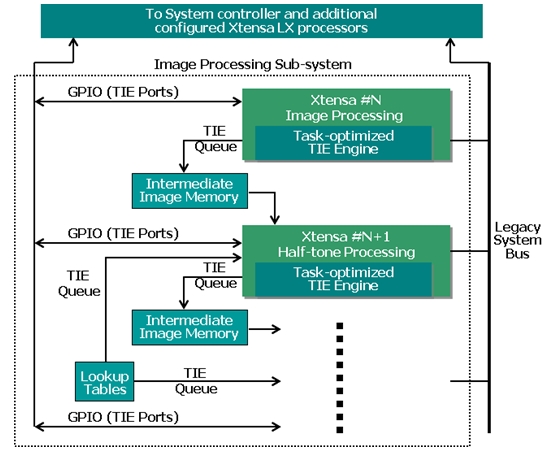
图9: Epson 公司的Realoid打印机SOC采用了基于Xtensa 的可扩展图像处理管线架构。
本文小结
通过前面分析我们可以看到,可配置处理器 Xtensa所具备的一些特征使其非常适合用于图像处理管线的实现。其中误差扩散算法的例子说明了Xtensa处理器在图像处理中的适用性。 使用TIE语言可以方便快捷的创建复杂的多周期多操作并行指令。高效的Load/Store指令使带宽满足持续运算的要求。
Xtensa处理器独有的特色使其成为打印机SoC芯片中实现图像处理管线的理想选择。Xtensa处理器可以满足打印机厂商对芯片的绝大部分需求。可编程处理器的灵活性可以满足图像处理管线中不断增加的功能需求,从而使实现更加灵活,更加高效。
产品营销经理
Tensilica 公司















